Un Viaggio nel Cuore della Generazione di Immagini AI 🎨🖼️
DALL-E e Stable Diffusion: Un Viaggio nel Cuore della Generazione di Immagini AI 🎨🖼️


1. Introduzione: La Frontiera della Generazione di Immagini AI 🌌
Immaginate di possedere un algoritmo in grado di trasformare input testuali in immagini visivamente coerenti e dettagliate.

Questa capacità, resa possibile da modelli avanzati di intelligenza artificiale come DALL-E e Stable Diffusion, rappresenta un traguardo significativo nella generazione automatica di immagini.

Esploreremo in dettaglio le architetture sottostanti, i processi di generazione e le differenze metodologiche tra questi due modelli.
2. Architettura: Fondamenti Tecnici dei Modelli 🏗️

2.1 DALL-E: Un'Implementazione Transformer per la Generazione di Immagini
DALL-E, sviluppato da OpenAI, è basato sull'architettura dei Transformer, originariamente concepita per compiti di traduzione linguistica. Un Transformer è un tipo di rete neurale che utilizza meccanismi di attenzione per pesare l'importanza di diverse parti dell'input durante l'elaborazione.

Componenti Chiave
- Encoder Testuale: Utilizzando un embedding spaziale, l'encoder converte il testo in una rappresentazione vettoriale densa, catturando semantiche complesse e relazioni contestuali.
- Decoder Immagine: Un generatore autoregressivo che decodifica la rappresentazione vettoriale in un output visivo, utilizzando una combinazione di upsampling convoluzionale e meccanismi di attenzione multi-head.
- Meccanismo di attenzione multi-head: Divide le operazioni di attenzione in più "teste" parallele, permettendo al modello di concentrarsi su diverse parti dell'input simultaneamente. Questo meccanismo può essere formalizzato come segue:
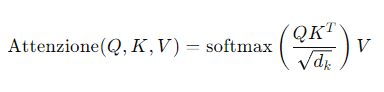
dove Q query, K key e V sono matrici derivate dall'input.

2.2 Stable Diffusion: Un Approccio Basato su Diffusione Latente
Stable Diffusion, sviluppato da Stability AI, utilizza una tecnica di diffusione latente, che permette di generare immagini tramite un processo iterativo di raffinamento del rumore latente.

Componenti Chiave
- CLIP Encoder Testuale: CLIP (Contrastive Language-Image Pre-Training) crea embeddings testuali robusti correlati a rappresentazioni visive su larga scala.
- Rete U-Net: Una rete neurale convoluzionale utilizzata per la denoising step-wise, applicando convoluzioni spaziali e transposte per rimuovere iterativamente il rumore dall'immagine latente.
- VAE (Variational Autoencoder): Un modulo per la compressione e decompressione delle immagini nello spazio latente, ottimizzato per rappresentazioni efficienti e scalabili.

3. Processo di Generazione: Meccanismi Dettagliati 🛠️
3.1 DALL-E: Pipeline di Generazione Autoregressiva
Il processo di generazione di DALL-E può essere modellato come una sequenza di passi autoregressivi:

- Codifica del Testo: Il testo descrittivo viene trasformato in una rappresentazione vettoriale densa mediante l'encoder, catturando le semantiche necessarie.
- Pianificazione dell'Immagine: Il decoder utilizza la rappresentazione vettoriale per determinare la composizione generale dell'immagine.
- Generazione Iterativa: Pixel per pixel, il decoder genera l'immagine finale utilizzando tecniche di upsampling e convoluzione, mantenendo coerenza con la rappresentazione testuale originale.
- Feedback Ciclico: L'immagine in fase di generazione viene continuamente raffinata mediante meccanismi di attenzione che ricalibrano il contesto visivo rispetto alla descrizione testuale.
3.2 Stable Diffusion: Procedura di Denosing Iterativo
Il processo di generazione di Stable Diffusion segue un paradigma di raffinamento iterativo:

- Inizializzazione del Rumore: Un vettore di rumore gaussiano iniziale viene generato nello spazio latente.
- Denosing Step-wise: Attraverso un U-Net iterativo, il modello prevede e rimuove progressivamente il rumore dal vettore latente, utilizzando tecniche di denosing via convoluzione.
- Retroazione via VAE: La VAE consente una compressione e decompressione efficiente delle immagini, migliorando la stabilità del processo di generazione.
- Rivelazione Finale: Il vettore latente depurato viene mappato nello spazio delle immagini reali, producendo l'immagine finale coerente con la descrizione testuale.
4. Randomizzazione: Variabili Stocastiche e Creatività 🎲🎨
4.1 DALL-E: Stochastic Sampling e Parametrizzazione della Creatività

- Distribuzioni di Probabilità: Utilizza tecniche di sampling stocastico (e.g., nucleus sampling) per introdurre variabilità e creatività nell'output.
- Parametro di Temperatura: Controlla l'ampiezza delle distribuzioni di probabilità durante il sampling, influenzando la diversità e la coerenza dell'output finale.
- Top-K e Top-P Sampling: Tecniche per limitare il dominio di scelta durante il processo di generazione, focalizzando il modello su scelte più probabili e rilevanti.
4.2 Stable Diffusion: Seed e Guidance Scale

- Seed Iniziale: Controlla la randomizzazione del processo di diffusione, garantendo replicabilità e coerenza nei risultati.
- Guidance Scale: Parametro che bilancia l'aderenza alla descrizione testuale rispetto alla libertà creativa del modello, regolando l'influenza del testo sull'immagine finale.
- Iterazioni di Denosing: Numero di iterazioni di denosing controlla la granularità e la precisione del processo di generazione, migliorando la qualità del risultato finale.

5. Confronto Tecnico: Analisi Comparativa ⚖️
Stile di Lavoro
- DALL-E: Generazione autoregressiva continua, richiede significative risorse computazionali e memoria durante il processo.
- Stable Diffusion: Processo iterativo di raffinamento, maggiormente efficiente in termini di memoria grazie all'uso dello spazio latente.
Controllo e Replicabilità
- DALL-E: Generazione unica per ogni esecuzione, maggiore variabilità.
- Stable Diffusion: Alta replicabilità con controllo preciso tramite seed, possibilità di tuning dettagliato.
Velocità vs Controllo
- DALL-E: Maggiore velocità di generazione, minore controllo fine.
- Stable Diffusion: Maggiore controllo sul processo generativo, richiede più tempo computazionale.
Efficienza delle Risorse
- DALL-E: Richiede più memoria durante il processo di generazione.
- Stable Diffusion: Più efficiente, opera in uno spazio latente compresso, permettendo un uso ottimizzato delle risorse.
6. Fondamenti Matematici 📐📊
.png)
Entrambi i modelli si basano su principi matematici avanzati per le operazioni di encoding, decoding e generazione delle immagini.
6.1 DALL-E
DALL-E utilizza l'architettura Transformer, fondata sull'attenzione multi-testa (multi-head attention) e sul meccanismo di attenzione scalare (scaled dot-product attention). Le operazioni di codifica e decodifica possono essere formalizzate come segue:
dove ( Q ), ( K ) e ( V ) rappresentano le matrici delle query, key e value, e ( d_k ) è la dimensione delle key.

6.2 Stable Diffusion
Stable Diffusion si basa su tecniche di diffusione e denoising, utilizzando processi stocastici per la generazione di immagini. La denoising è governata dall'equazione di Fokker-Planck, che descrive l'evoluzione temporale della distribuzione di probabilità del sistema:
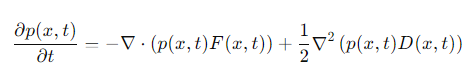
dove ( p(x, t) ) è la distribuzione di probabilità, ( F(x, t) ) è il drift term e ( D(x, t) ) è il diffusion term.
.png)
7. Evoluzione e Sviluppo 🚀
7.1 DALL-E
DALL-E ha introdotto un paradigma rivoluzionario nella generazione di immagini AI rispetto ai modelli precedenti, come GANs e VQ-VAE, grazie alla sua capacità di creare immagini uniche e dettagliate da descrizioni testuali complesse.

7.2 Stable Diffusion
Stable Diffusion si distingue per la sua efficienza e scalabilità, permettendo applicazioni in tempo reale e la generazione di immagini ad alta risoluzione con risorse computazionali limitate.
8. Conclusioni: L'Avanguardia della Creatività Computazionale 🌐
Entrambi i modelli, DALL-E e Stable Diffusion, rappresentano pietre miliari nella generazione di immagini AI, offrendo strumenti potenti per la creatività computazionale. Le loro architetture e metodologie uniche, insieme alla loro capacità di generare immagini sorprendenti da input testuali, continueranno a influenzare e ispirare nuovi sviluppi nell'intelligenza artificiale e oltre.


lg
against downvote abuse