Makine Öğrenmesi Nedir?
Makine Öğrenmesi Nedir?
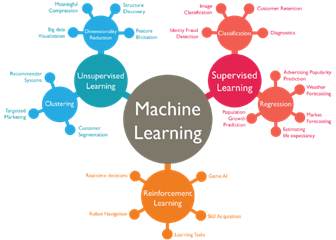
Makine Öğrenmesi, açık bir şekilde programlanmadan deneyimlerden otomatik olarak öğrenme ve gelişme becerisi sağlayan bir yapay zeka ürünüdür. Makine öğrenimi, verilere erişebilen ve kendileri için öğrenmeyi kullanabilen bilgisayar programlarının geliştirilmesine odaklanır.
Öğrenme süreci, verilerdeki kalıpları aramak ve verdiğimiz örneklere dayanarak gelecekte daha iyi kararlar vermek için örnekler, doğrudan deneyim veya talimat gibi gözlemler veya verilerle başlar. Birincil amaç, bilgisayarların insan müdahalesi veya yardımı olmadan otomatik olarak öğrenmesine izin vermek ve eylemleri buna göre ayarlamaktır.[22]
Öğrenme yaklaşımları
Makine öğrenimi algoritmaları hedeflenen sonuca göre birkaç sınıfa ayrılabilmektedir. Bunlar: gözetimli öğrenme, gözetimsiz öğrenme ve pekiştirmeli öğrenmedir.
Gözetimli Öğrenme
Gözetimli öğrenme algoritması gelecekteki olayları tahmin etmek için etiketli örnekleri kullanarak geçmişte öğrenilenleri yeni verilere uygulayabilir.
En çok kullanılan gözetimli öğrenme algoritmaları:
En Yakın Komşuluk → k-Nearest Neighbors (KNN)
Yapay Sinir Ağları → Artificial Neural Network (ANN)
Destek Vektör Makinaları → Support Vector Machine (SVM)
Karar Ağaçları → Decision Trees (DTs)
Doğrusal Regresyon → Linear Regression
Lojistik Regresyon → Logistic Regression
Gözetimsiz Öğrenme
Gözetimsiz öğrenmede örneklerde etiketleme yoktur. Data setindeki bileşenler temel alınarak saklı ilişkilerin veya grupların ortaya çıkarılma amaçlanmaktadır.
En çok kullanılan gözetimsiz öğrenme algoritmaları:
Kümeleme → Clustering
Birliktelik Kuralları → Association Rules
Temel Bileşen Analizi → Principal Component Analysis (PCA)
Pekiştirmeli Öğrenme
Pekiştirmeli öğrenme, hedefe yönelik ne yapılması gerektiğini öğrenen bir makine öğrenmesi yaklaşımıdır. Pekiştirmeli öğrenmede ajan adı verilen öğrenen makinemiz karşılaştığı durumlara bir tepki verir ve bunun karşılığında da sayısal bir ödül sinyali alır. Ajan/öğrenen makine aldığı bu ödül puanını maksimuma çıkartmak için çalışır. Bu şekilde çalışan deneme yanılma yöntemi, pekiştirmeli öğrenmenin en ayırt edici özelliğidir.[23]
Makine Öğrenmesi modelleri
Destek Vektör Makineleri Algoritması
Sınıflandırma konusunda oldukça etkili yöntemlerden birisidir. Sınıflandırma için bir düzlemde bulunan iki grup arasında bir sınır çizilip iki gruba ayırılabilir. Bu sınırın çizileceği yer ise iki grubun da üyelerine en uzak olan konum olmalıdır. Bu işlemin yapılması için iki gruba da yakın ve birbirine yaklaştırılarak ortak sınır çizgisi üretilir.
Çekirdek Hilesi
Data setindeki veriler her zaman karşımıza doğrusal olarak çıkmayabilir. Bu durumdan kurtulmak için çekirdek hilesine başvururuz. Yeni bir boyut oluşturabilirsek doğrusal olarak sınıflandırmamız mümkün olabilir. Örneğin Şekil 1' deki grafikte kırmızı noktaları biraz yukarı kaldırıp 3. bir boyut oluşturabilirsek DVM ile doğrusal bir çizgi oluşturabiliriz.
Naive Bayes Algoritması
Naive Bayes Algoritmasının temeli Bayes teoremine dayanır. Dengesiz veri kümelerinde çalışabilir. Çalışma şekli bir örnek için her durumun olasılığını hesaplar ve olasılık değeri en yüksek olana göre sınıflandırır. Az bir veri setiyle yüksek doğruluk oranları çıkarabilir.[26]
P(A|B) = P(B|A)*P(A)/P(B) (1.1)
Bayes teoremini kullanarak, B oluşumu göz önüne alındığında, A olma olasılığını bulabiliriz.
P(A|B) => B olayı gerçekleştiğinde A olayının gerçekleşme olasılığı
P(A) => A olayının gerçekleşme olasılığı
P(B|A) => A olayı gerçekleştiğinde B olayının gerçekleşme olasılığı
P(B) => B olayının Gerçekleşme olasılığı
K-NN (K- En Yakın Komşu) Algoritması
K-NN algoritması basit ve çok kullanılan yöntemlerden birisidir. Algoritmanın çalışma şekli rastgele bir K değeri belirlenir, ardından sınıflandırmak istediğimiz elemanın en yakın K tane komşusuna bakılır. K tane komşudan en çok sayıyı alan elemanımızın sınıfıdır. Veriler için doğru olan K değerini bulmak için, KNN algoritmasını farklı K değerleriyle birkaç kez çalıştırılır ve doğruluk oranı en yüksek seviyede olduğunda K değerimizi bulmuş oluruz.[27]
Karar Ağaçları Algoritması
Karar Ağacı kullanmanın amacı, önceki verilerden çıkarılan basit karar kurallarını öğrenerek hedef değişkenin sınıfını tahmin etmek için kullanılabilecek bir eğitim modeli oluşturmaktır.
Karar ağacı, her düğümün bir özelliği, her bağlantının (dal) bir kararı ve her yaprağın bir sonucu (kategorik veya sürekli değer) temsil ettiği bir ağaçtır.
Karar Ağaçları Nasıl Oluşturulur?
Karar ağacı oluşturmak için iki algoritmaya bakılacak:
CART (Sınıflandırma ve Regresyon Ağaçları) → metrik olarak Gini İndeksini (Sınıflandırma) kullanır.
ID3 (Yinelemeli Ayırıcı 3) → Entropy işlevini ve bilgi kazancını ölçüm olarak kullanır.
ID3 Algoritması
J.R. Quinlan, tarafından 1986 yılında bir veri setinden “karar ağacı” üretmek için geliştirilen ID3 algoritması geliştirmiştir. Bu algoritma aşağıdan yukarı (kökten alt dallara doğru) ve greedy search (sonuca en yakın durum) tekniklerini kullanır. ID3 algoritmasının temelinde Entropy ve Information Gain vardır.[28]
Entropy: Rastgeleligi, belirsizliği ve beklenmeyen durumun ortaya çıkma olasılığını gösterir. Eğer örnekler tamamı düzenli / homojen ise entropisi sıfır olur. Eğer değerler birbirine eşit ise entropi 1 olur.
Entropi formülü:
Entropi(D1) = -∑_(i=1)^M▒〖pi * log2(pi)〗 (1.2)
m: Entropisi hesaplanacak durum sayısı
pi: i durumun olasılığı
Entropi sadece hedef üzerine hesaplanmaz. Ayrıca özellikler üzerine entropi hesaplanabilir. Fakat özellikler üzerine entropi hesaplanırken hedefte göz önüne alır. Bu durumda entropi formülü:
E(T,X) = ∑_(c∈x)▒〖P(c)E(c)〗 (1.3)
Information Gain (Bilgi Kazanımı)
Bilgi kazanımı, bir veri setini bir özellik üzerinde böldükten sonra tüm entropiden çıkarmaya dayanır. Entropinin küçük değer içermesi durumunda özelliğin önemi Karar Ağacı algoritması ID3 için artmaktadır. Diğer taraftan 1’e yaklaştıkça özelliğinin önemi azalır. Ancak information gain’de olay tam tersidir ve bu açıdan entropinin tersi gibi düşünülebilir. Karar Ağacı inşa edilirken en yüksek değerleri information gain’e sahip özellik seçilir. [29]
Gain(T,X) = Entropy(T) – Entropy(T,X) (1.4)
CART
CART (Sınıflandırma ve Regresyon Ağaçları) metrik olarak Gini İndeksini kullanır.
Gini İndeksi
Gini indeksi, belirli bir alanın etkisi ile örnek sonucu arasındaki dağılımı ölçen bir CART algoritmasıdır. Bu, ortaya çıkan durumda, belirtilen her özelliğin doğrudan ne kadar etkilediğini ölçebileceği anlamına gelir, her alandaki hangi verilerin, karar verme sürecine daha az veya daha fazla yer aldığını ölçebiliriz. Böylece, bu belirli alana / değişkene daha fazla odaklanabiliriz.
Tüm veriler tek bir sınıfa aitse, o zaman saf olarak adlandırılabilir. Derecesi her zaman 0 ile 1 arasında olacaktır. 0 ise, tüm verilerin tek bir sınıfa / değişkene ait olduğu anlamına gelir. 1 ise, veriler farklı sınıfa / alana aittir.
Gini= 1-∑_(i=1)^c▒(p_i )^2 (1.5)
Pi, bir nesnenin belirli bir sınıfa göre sınıflandırılma olasılığıdır.
En düşük gini endeksi cevaptır. Dolayısıyla karar ağacındaki kök düğümümüz en düşük gini indeks düğümü olacaktır. Sonuçta ortaya çıkan örneklerde hangisinin daha fazla etkilediğine bu şekilde ulaşırız.[30]
Rastgele Orman Algoritması
Rastgele orman, adından da anlaşılacağı gibi, bir topluluk olarak çalışan çok sayıda bireysel karar ağacından oluşur. Rastgele orman çalışma mantığı veri setinden n sayıda örnek seçilir her örneğe karar ağacı algoritması kullanılır. Bir sonuç üreteceği zaman bu karar ağaçlarındaki ortalama değer alınır ve sonuç üretilir. Bir topluluk olarak faaliyet gösteren çok sayıda görece ilişkisiz model (ağaç), münferit kurucu modellerin herhangi birinden daha iyi performans gösterecektir. Önemli nokta Modeller arasındaki düşük korelasyonun olmasıdır. İlişkisiz modeller, bireysel tahminlerin herhangi birinden daha doğru olan topluluk tahminleri üretebilir.[32]
Lojistik Regresyon Algoritması
Lojistik regresyon, bir hedef değişkenin olasılığını tahmin etmek için kullanılan denetimli bir öğrenme sınıflandırma algoritmasıdır. Hedef veya bağımlı değişkenlerin iki olası sınıfları vardır. Diğer bir deyişle, bağımlı değişken, doğası gereği, verileri 1 (başarı / evet anlamına gelir) veya 0 (başarısızlık / hayır anlamına gelir) olarak kodlanmış olan ikilidir. İstenmeyen posta tespiti, Diyabet tahmini, kanser tespiti gibi çeşitli sınıflandırma problemleri için kullanılabilen en basit ML algoritmalarından biridir.[33]
Mühendislik Tasarımı dersindeki raporumdan alıntıdır.
[22] https://expertsystem.com/machine-learning-definition/
[23] https://yz-ai.github.io/blog/pekistirmeli-ogrenme/pekistirmeli-ogrenme-bolum-1
[24] https://www.7wdata.be/visualization/types-of-machine-learning-algorithms-2/
[25]https://medium.com/@ekrem.hatipoglu/machine-learning-classification-support-vector-machine-kernel-trick-part-10-7ab928333158
[26]https://medium.com/@ekrem.hatipoglu/machine-learning-classification-naive-bayes-part-11-4a10cd3452b4
[27]https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761
[28] https://www.datacamp.com/community/tutorials/k-nearest-neighbor-classification-scikit-learn
[29]https://erdincuzun.com/makine_ogrenmesi/decision-tree-karar-agaci-id3-algoritmasi-classification-siniflama/
[30] https://medium.com/@riyapatadiya/gini-index-cart-decision-algorithm-in-machine-learning-1a4ed5d6140d
[31] https://medium.com/@vighneshtiwari16377/decision-tree-classifier-mathematics-f1ab9fd29a46
[32] https://towardsdatascience.com/understanding-random-forest-58381e0602d2