The Message is the Medium
A Preliminary Message
This post introduces what I think is a fundamental flaw in almost all blockchain designs. In brief, it is the emphasis on state as the ‘atomic element’, when we could also build using messages instead. The implications of this are quite severe, but also quite hard to understand because the computer science concepts are a bit inaccessible to the non-CS world.
What follows is a very informal, non-rigourous description to try and explain the difference between messaging and state to the non-technical audience. I’ve tried to get the simple message across but if you find yourself in a state of confusion, there is another way to understand it and that is to watch this space - we’re going to build it, so then the message will be put to the medium. Enough bad analogies, let’s forge on.
What’s a State Machine, anyway?
A state machine is a computer science invention to capture the reliable, deterministic machine. In words, it is a software “machine” that given some set of inputs and memory, always delivers the same outputs.
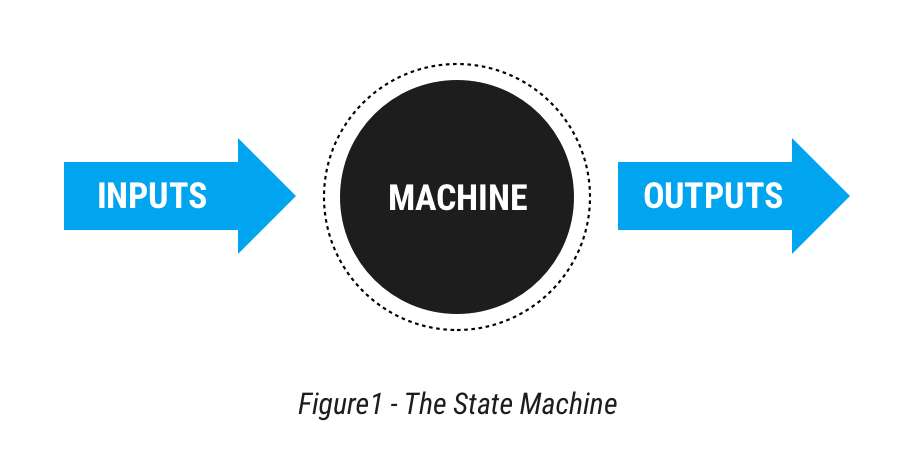
Think about a vending machine, and the software inside, which has to simulate the hardware machine so as to figure out what to do next. In words, “if we are in State 1, wait for coin. If a coin turns up, enter State 2. If in State 2, wait for button push. If a button push turns up, deliver drink, go to State 1.” In essence then, our machine consists of some code to handle that algorithm, some state (memory) to recall where we are, and an ability to read incoming messages (coins, buttons) and write out some instructions as messages (drink!).

We can also construct bigger state machines out of smaller ones - a database is essentially an enormous state machine, made up many little machines for each SQL table, each row and each cell. A protocol is a small state machine made of two state machines - one for each end. A blockchain is another enormous state machine, made of thousands of “full node” state machines with lots of hangers-on called SPV clients. While the essence of the design of a state machine is pretty simple, using them is as much an art as a science because we don’t have a great view on how to compose small state machines into large state machines. But we’ll leave aside that complexity for now.
Choice
It turns out that there are two fundamental approaches to building a state machine.
Note, what follows is a very stylised viewpoint, not a rigorous one. We ignore the code above, and just assume it is referenced wherever needed. We also ignore the output messages, for simplicity. Our goal is to get you to a state of understanding the message, not to impress CS geeks.
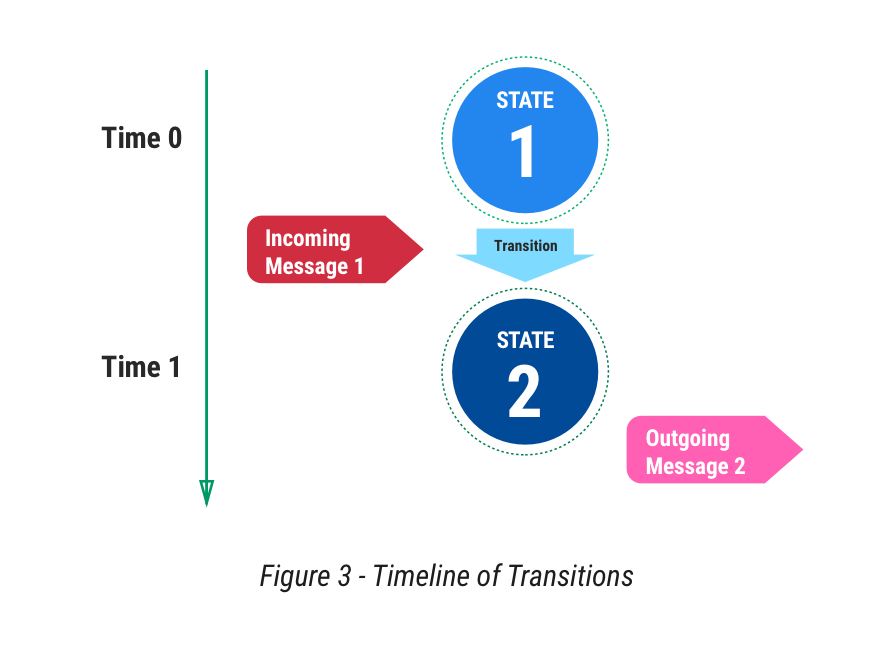
We normally model the state machine as above - it starts out in State One, and then Message 1 arrives. The processing of this message causes a transition from State One to State Two. On transitioning to State 1, the machine sends out messages, although that is strictly optional - it depends on the machine’s needs at that transition.
Our job in building the state machine is to write the code to store and transition all states for all known messages. It turns out that, in doing this job, there are two fundamentally different ways in which to write the machine, and the choice of which colours our thinking, our design and eventually our capabilities.
First Way: Thinking of it as a machine of states. In this view, we store State One. Then, when the message arrives, the machine turns over to State Two, and we store that new state. Repeat! Think of the states as the Blue Circles above, and you can ignore any other view of the world.
Second Way: Thinking of it as a machine of messages. In this alternate view, we record the messages. We always start the machine at State One. Then we pump all of the incoming messages (Red Pills above) into the machine (and out pops any new messages). We store the messages, but don’t bother with the state, because we can calculate it any time.
These views are mostly equivalent in theory, and the trick to understanding this is that the machine is deterministic. Once we’ve established the machine as being exact and unforgiving in its actions, we know that for example M1 on State1 always results in State2 (and M2 out).
Then, if we have the machine, and we have the set of messages, we can always roll it again to get the states. OR, if we have recorded the states, we can always walk the chain of states to reproduce the action, although we don’t necessarily know what messages caused that journey. If you like your graphs, you could think of the distinction as storing the nodes OR storing the edges.
We have a choice about how we think about things. And, depending on our desires and assumptions, we are likely to prefer one way or the other: databases are seen as machines of state, as is a light switch - it knows whether it is on or off, but doesn’t know how it got to where it is now. Whereas protocols are typically thought of more as machines of messages; consider an email exchange in which the last message doesn’t tell you all the story, and if it’s been a while you might have to scan all the previous messages in thread to work out what’s happening.

Wheretofore the machinery of blockchain?
That’s in theory - practice can be different. Your online bank account is presented as a machine of state, with balance being told to you. But inside the bank, use of double entry accounting makes it more a machine of messages.
What should blockchain do?
For reasons that might be historical, or maybe because it’s more typical for designers to think this way, blockchains are seen as machines of state, and not as machines of messages:
… The goal of a blockchain is to represent a single state being concurrently edited. In order to avoid conflicts between concurrent edits, it represents the state as a ledger, that is as a series of transformations applied to an initial state. These transformations are the “blocks” of the blockchain, and — in the case of Bitcoin — the state is mostly the set of unspent outputs.
(my emphasis) LM Goodman, “Tezos: A Self-Amending Crypto-Ledger Position Paper”, 2013
Or, from a recent Ethereum replacement project:
How do transaction semantics fit into our description of contracts? From the process level, a transaction is an acknowledgment that a message has been “witnessed” at a channel.
Messages themselves are virtual objects, but the pre-state and post-state of a contract, referring to the states before and after a message is sent by one agent and witnessed by another, are recorded and timestamped in storage, also known (in a moral sense) as the “blockchain”.
Message passing is an atomic operation. Either a message is witnessed, or it is not, and only the successful witnessing of a message qualifies as a verifiable transaction that can be included in a block.(author’s emphasis in bold, my emphasis in italics) anon?, “RChain Architecture - Contract Design”, 2017 RChain Cooperative
Note how the author above has established everything we need to store the message as transaction, and then fallen back to blockchain canon of state.
If we look at the Bitcoin state machine in Figure 4 below for another example, we can see this state view writ large in the UTXO model, which groups transactions as collections of Unspent Transaction Outputs (“UTXO”). The transaction is a record of state that includes the input, and the output. Comparing to Figure 3 above, think of both of the blue circles in each record, but none of the messages. Normally each UTXO transaction is represented as a box with a column of inputs on the left, and outputs on the right, Figure 4:
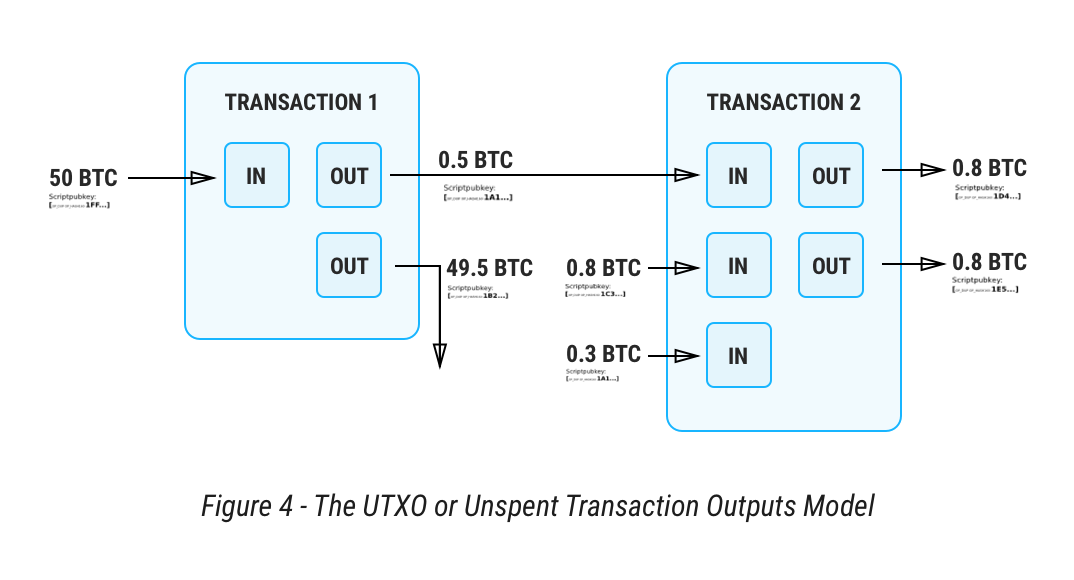
On the input (left) side of each transaction is a list of references to prior outputs or “coins”, by which presence they are then spent, and on the output (right) side is another matching list of new coins, by which presence they are now created and spendable in the future. Above, “Transaction 1” creates a 0.5BTC coin as an output, and “Transaction 2” spends the 0.5BTC coin by citing it as an input.
The Bitcoin transaction record, as a record of both inputs and outputs, is like a miniature balance sheet; the inputs match the outputs. For the visually minded, each of these transaction records is also like lego blocks in that new ones must plug onto old ones, and provide for newer ones to plug into them in the future.
The Brittleness of the UTXO
Now, it has been observed before, but it is worth repeating: the Bitcoin design is of an extraordinary design, but one of its facets is that all of the components are strongly linked to each other in a very dependent way. As it says:
“A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.”
Satoshi Nakamoto, “Bitcoin: A Peer-to-Peer Electronic Cash System,” 2008.
The mission was the money, but the money is also the driver for the security model, by means of paying miners to compete to validate. This powerful facet of intra-dependency does have one weakness - it is brittle in architectural terms. By this, I do not mean that Bitcoin is about to fall apart at any moment, but rather, if we change one design element, it threatens the sanctity of the entire architecture.
And so it is with the UTXO. As mentioned, the mission of Bitcoin was a money. Every (full) node needs to have each record of the money available for it, so it can validate every incoming transaction, and proceed to distribute the transactions into its proposed block for mining. In contrast, SPV or remote clients need to have an easy way of proving just their component of incoming coins, without dragging in the whole chain.
These two requirements are in conflict. Because there are a lot of records in a big chain like Bitcoin, the UTXO layout is an elegant design that meets both those requirements with a reasonable efficiency given its other impacts. It is very good at providing the proof that a client needs at a point in time.
An Order Book
But what happens to the UTXO when the requirements change? Let’s say we want to do trading. For various reasons, the best way to do this is to bring everyone together, construct an order book - a list of bids to buy versus a list of offers to sell - and then run an auction clearing process to find the best price for all traders. There are other ways of course, but this is both the time-tested way and the way imposed by exchanges. Figure 5.
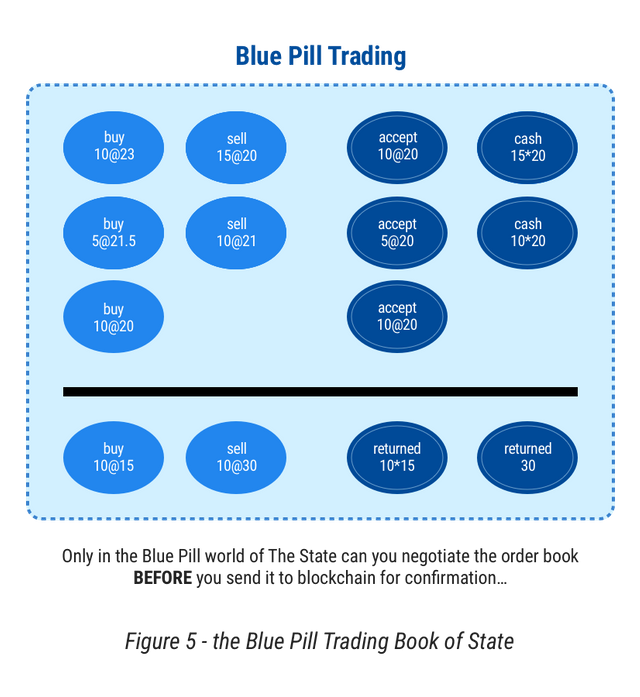
In coming together in a UTXO state machine, an unknown number of people want to bid for positions on the buy side, as do an unknown number of people on the sell side. The UTXO design cannot easily facilitate this design for two reasons: 1. the interaction of many unknowns competing for one result does not scale because the entire layout needs to be negotiated on the fly - inputs, outputs and prices! - between the competing traders; and 2. trading is information sensitive - if there is a way to pull out of the negotiation and collapse it, traders will do that once they’ve spotted your position. This is a fundamental contradiction!
A messaging flow can handle this conundrum easily. If the blockchain intermediator (the miner in a PoW design, or the producer in DPOS) receives a steady series of messages for bids and offers, he simply collects them up in order and hands them to the “book contract” which internally constructs the book, decides on the swap price, and sends new messages out confirming the contract’s outcome.

The messages are logged, but the state (e.g., UTXO) is implied, which means it is constructed by the computer internally, and then (can be) thrown away. As long as the blockchain has decided on the strict set of messages - both which messages and in what order - the result is deterministic because every other node runs the same contract for each set of the same input messages, and concurs on the output messages.
Two more advantages: if any incoming trades are dropped in this block they can simply be deferred to the next block. That’s because the incoming messages are independent intents to trade whenever, whereas the inputs and outputs making the UTXO state are more constrained to being parts of their dependent collection that should happen now, inside that very transaction.
Secondly. This construct captures much more of the problem of the trading book. That is, when you want to trade with me, or I with you, we both write our bid/offer as a message and send it in. The hard part is done inside the contract, and the smart contract author has covered that in her design. In contrast, with the UTXO construct, it is you and I that have to lay out the blue box in Figure 5, agree on everything, sign off and then submit it for consensus. UTXO leaves the hard part to us the traders, and the easy part - logging the fact - to the chain.
As an exercise, you might like to examine how you would handle fees in both designs.
Slight Demurral
It’s not all one way - the state model has the benefit of trapping bugs more quickly. Every transaction has to be perfectly in agreement in its recorded state, not just the messages that got us there. This ability to trap errors quickly could be seen as a major advantage in reconciliation of trades, which the banking sector is looking at for cost and operational risk reduction.
But even this could be a choice of risks - when a bug turns up in a blockchain, the chain quickly breaks and forks.
Everything stops while nodes argue and hash. When a bug hits a message-model chain, the bug is implicit, and for the most part generates a dispute between parties over the meaning of the messages. Persons impacted can take it offline; including, we could develop the proofs to watch the issue offline, or ex-chain.
Conclusion
The messaging model is for many reasons superior to the state model for the purpose of building broadly capable blockchains. It’s not all one way - the state model has the benefit of trapping breaks more quickly.
A fuller post would list all the pros and cons, but for now, we’ll just call out one major pro. Other than the flexibility of the above example, messaging chains can reach much higher performance. For example, Bitshares and Steem by @danthemamn were all built on this model, and show 1000s of transactions per second. As was my Ricardo system, albeit non-blockchain, but it explains why it is so easy for me to like :-)
On paper at least, this approach promises much higher performance, and you can possible see a hint that EOS will be built this way too! Indeed, it was the need for speed in those systems that led designer @dantheman and myself to the discovery that, with apologies to Marshall McLuhan,
the message is the medium.
message flow = more quantum-like behavior, from a design perspective (my visual analogy, interpetation, as non CS-geek): message = medium | messaging ↔ quantum superposition
time to read this a few more times...
Ummmmm okay I'll roll. Liberties taken.
When the DARPA guy needs to read it a few more times, I feel better about myself for having done so.
The way I think of it in terms of requirements to classes of users, Bitcoin is a state machine to a consumer and a messaging machine to a bank. A user only cares about the current state of their balance after every transaction ie deposit or withdraw . The bank cares about where that money has been, what it has done, keep track of where it is going.
That's a good analogy.
Do I understand it right:
The chain doesn't store the state of my account, but the nodes calculate it, and I can query them for the balance - right? Then I only have the node's word for it, but I can test it by sending money to some other account. If my message is included in a block, then the previous balance is practically validated, and no more an assumption. Was this correct?
Right - this chain is a set of messages, where the other chains are a set of states (like UTXOs). To know the balance of your account, the node has to read all the relevant messages and calculate it.
In terms of a wider application, a blockchain typically relies on many miners or producers, and each of them can censor your messages, or in effect decline to process your transactions. But as there are many, your messages just pass on to the next and the next. So as long as most of the producers and you are in agreement over your total set of messages, your balance isn't in doubt.
Just sending another message such as a transfer does not validate directly your view of your balance - you'd have to instead transfer the lot to prove it. But with signed and agreed messages, it's a lot easier to write code that comes to solid consensus on a set of messages. In effect deviation is a bug. Bugs we can solve.
The State Machine is an important concept and very useful too, but not easily grasped, especially the consequences of not following State Machine protocol. I wonder how many of these self-taught computer geniuses out there actually know about it.
There's lots of CS about this... but in my experience one just has to dive in and do it, build the state machines needed. I find myself relearning the lessons time and time again. I'm not sure why, but state machines just don't seem easily amenable to the mind. Maybe in 10 years someone will come up with the invention that makes it easy ... here's hoping!
I see State Machines as being an artifact of modern times. Like Turing Machines, the Internet and Blockchains, State Machines were natural phenomenon (laws of nature) waiting to be discovered by man. Who knows what other powerful ideas lurk ou there for the creative individual to discover and develop? I find it comforting to know that there may be thousands or millions of potential Satoshi Yakamotos who exist or will be born in the future.

What an interesting point of view brother.
Oswald Spengler, my favorite philosopher, who authored "The Decline of the West", argumented about humans beings having to be "in shape" or "in good form", in order to grasp ideas and oppotunities that are preexistent, but need an ideal vessel to express them. You captured his thinking in a very elegant way. And even more, your thoughts give me even more hope on the greatness of human future on this planet:
"Who knows what other powerful ideas lurk ou there for the creative individual to discover and develop? I find it comforting to know that there may be thousands or millions of potential Satoshi Yakamotos who exist or will be born in the future."
"
Thanks for the upvote and intelligent comment. $.20 isn't much, but when steem hits $100 you could treat yourself to a steak dinner;)
On the topic of great ideas, I think there is an element of an idea having it's "time". Using bitcoin as an example, microprocessors, distributed computers, ledgers and cryptography have all been around for decades. However, when someone thought to put them all together, they got Bitcoin.
I think one "vessel" is the need to solve a problem. Proof of Stake was a meaningless concept 10 years ago, because there were no blockchains hence no Proof of Work algorithms. In this era of blockchains, Proof of Work is a tedious, expensive process and it is now easier to envision how Proof of Stake can be an improvement.
Taking it a step further, there are even a handful of true visionaries whose ideas bordered on magic in their time; Tesla, Edison and Jules Verne
I spend a lot of time searching for the next great idea and it was rewarding to be appreciated for my quest.
For the sake of completeness, one might add that instead of logging inputs or states, you could also store outputs. Given a deterministic statemachine will allow you to derive the list of consecutive states and thus inputs from that.
Of course, storing outputs is not what you want :)
Yes, there are lots of subtle variations. In practical implementations, we'd tend to store all three: inputs, state, outputs. But we'd be recovering only from one of them. The others would be debugging logs.
EOS at least will store the incoming messages and the outcoming messages. And if the outputs become inputs into a later contract, they are referenced again.
Wow awesome post
Great post and good explanation, thanks @iang
You really smashed it with this post. Thank you!
Thank you for this wonderful post, iang. I wonder if the best solution would be a combination of both - messages and states + cutting out the history that has already been carved in stone... More resource-consuming by all means, but maybe worth the while?
Hi, Mr Ian Grigg, I am Kevin Jing, and I really appreciate your great work.
I have already translated several great articles writen by you, and I'd like to seek your permission for post the Chinese version of this article and your great article "Triple Entry Accounting" on https://www.bihu.com, which is kind of the chinese version of steemit. I might receive some income from the translation.
I will put author, title and link at the top and encourage readers to visit the original article and clap for it.
Please reach me if you have any questions, my email is : [email protected].
Thanks a lot.