Block Producer Failover Proposal - The Thin Proxy
by Sam Noble, CTO EOS Dublin
I've been thinking a lot about failover and how we can make it as simple and easy as possible to implement for all BPs across the entire network. Drawing from my experience building real-time health monitoring systems in distributed environments, I wanted to take a stab at a high level proposal to catalyze conversation. I'll try to keep this light and non-technical in the beginning.
What is failover and why is it so important?
Failover is a term used in infrastructure/server architecture to describe a redundant setup, e.g. if something breaks, we have another one on standby that can take over and keep things running. For example, if you're running a website from a single server and that server crashes, your website is now offline. We can solve this by having a backup server take over if the first goes offline, just like a reserve parachute. This is a simple example but it hopefully provides a starting point.
Why do we care about this in the EOS ecosystem?
As block producers, part of our responsibility is to ensure that the network is reliable and highly available. The network itself has built-in failover—part of the reason for having many elected producers and even more standby nodes. However, as block producers, we want to make sure that we can continue to produce blocks without skipping a beat, be it a sudden failure or a planned maintenance. That means that we need to run at least 2 nodes. If one node is lagging behind, completely falls down or needs to be restarted to apply the latest security patches, we need a standby node in place to handle production until the first node is back online.
Most of the time, failover is a trivial problem and in modern-day distributed applications, it's expected. We've dealt with it long enough to know how to handle it efficiently. In the EOS network, the situation gets interesting because each block producer uses a unique signature to sign blocks. Only one producer can use that key at a time. Additionally, the primary function of a node is broadcasting events, not receiving requests.
Any solution that we evaluate should hit a few key objectives. The failover mechanism should be:
simple, with as few moving parts as possible
passive
independent of node state (Is the node reachable or not? —not cats in boxes here)
stateless
What's the solution?
There has been some discussion of solving this problem by promoting a standby node to be a producer. Really, this all comes down to the private key that a block producer uses to sign blocks. A node with no signing key could become a producer at runtime, should the key be updated and the producer plugin re-initialised.
This idea is still being explored, although it immediately raised a few questions for me which prompted me to seek an alternate solution:
How do we ensure the update was successful? (you'll want a failover on the updater)
Who performs the update?
How is the update secured to prevent anyone from gaining access?
Remember that we need to coordinate this across geographically redundant locations.
Proposal
The approach I wish to propose takes a different view on what makes a block producer active in the network: its connectivity to the rest of the network.
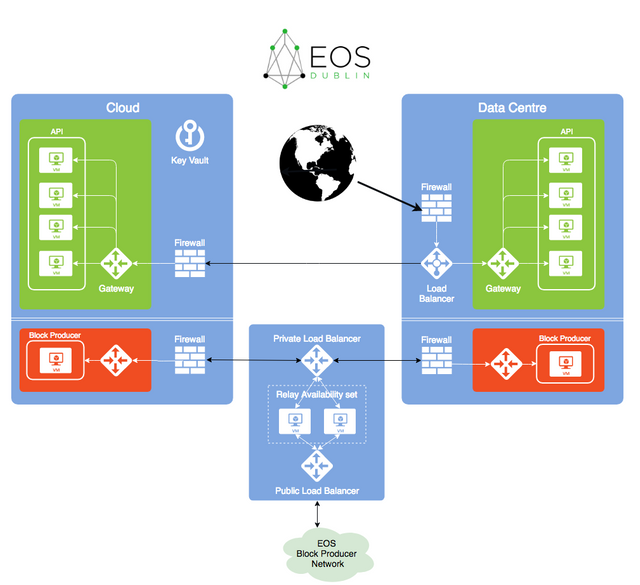
.png)
If you have 3 machines all with the same private key, all producing blocks, but only one of those nodes is allowed to communicate with the rest of the network, you could still have a single, active block producer. The first thought here is that you could simply add/remove rules to your firewall to turn nodes on/off. However this requires active monitoring of your nodes and the long-term state of offline nodes which should be online.
Instead, we can use a thin proxy between our internal network of block producers and the rest of the world. The proxy has a very simple job to do: for each block cycle, forward only one message from all of the machines sitting behind it. When it receives a message from the network, broadcast it internally to all the nodes. It needs to be thin so that we're not adding noticeable overhead to the communication.
As far as the producing nodes are concerned, they're just doing what they normally do, except each node is configured to have a single peer, the relay node. This means we don't need any changes to the EOS platform code!
The relay node will be required to run a single, new plugin. The plugin would simply need to receive events from the nodes in the sub-net and filter them such that only a single message for any given block is forwarded. On the flipside, any messages received from the wider BP network would be relayed to each node on the local network.
Challenges
Naturally, this solution isn't without its challenges that need to be taken on. I have some ideas already and the rest we can figure out together!
What mechanisms can we use to filter out duplicate messages received from the local network?
We still need to secure communications form our internal network to the relay, but this is no different to the securing of connections between block producers in the wider network.
Avoid a single point of failure on the relay.
I'm going to start looking into the creation of this plugin in order to get a test environment up and running. I've published this in the hopes of sparking more discussion around how we'll ensure that we can make our nodes as resilient as possible and would love to get some input on this. Are we crazy? Is this full of holes? Or do you think this has legs and want to get involved?
All the Best,
Sam
EOS Dublin
@eosdublin
https://www.eosdublin.com
[email protected]
EOS Dublin On Telegram: https://t.me/eosdb
EOS Dublin Online: https://www.eosdublin.com/
EOS Dublin On Twitter: https://twitter.com/eosdublin
EOS Dublin On Steemit: https://steemit.com/@eosdublin
EOS Dublin On Medium: https://medium.com/@eosdublin/
EOS Dublin On Meetup: https://www.meetup.com/EOS-Dublin/
EOS Dublin On Everipedia: https://everipedia.org/wiki/eos-dublin/