A scalable Docker Swarm Cluster for an EOS node
Hello EOS community,
In this article we will build and test EOS Block Producing nodes on a Docker Swarm. I (Bohdan) am not a big expert in Docker, so this is experimental training and configuration, but so far, I like the results.
Our configuration withstood an attack of over 42k requests per second. We hope to find the upper limit with additional testing.
Important: this document is not an authoritative manual. We are sharing are experiments, results, and ideas.

Summary
We ran tests on the Jungle testnetwork (http://jungle.cryptolions.io:9898/monitor/) which were started by Syed of @eoscafe and Igor of @eosrio and supported by almost the whole Jungle community. Thank you everyone!!! The test consisted of spamming get_info requests from different parties.
Normal nodes would stop answering requests after 0.5 - 2 minutes spamming an average of approximately 25,000 requests per second. In this round of tests, only Eric's (@xebb's) configuration of the five to ten configurations we tested survived the load. He used HaProxy LoadBalancing and wrote this excellent tutorial here: https://steemit.com/eos-blockproducers/@xebb/eos-community-testnet-update-with-initial-performance-testing-on-dawn-3-0-0.
Docker's build-in loadbalancer and swarm configuration described below also showed great results, we increased spam to over 42k request per second without any problem.
Of course, Docker swarms have their advantages and disadvantages. The advantages include the use of containers, easy scaling to other servers with a single command, decentralized design (you can have cluster managers in different locations), service discoversy, built-in load balancing, flexible updates (service updates can be applied incrementally).
The disadvantages (for now) are some difficulties re-synching nodeos data-dir folders.
Our Goal:
To Build a cluster with non producing nodes which can answer a lot of request and can be easily scalable between one and more machines connected to one producing node.
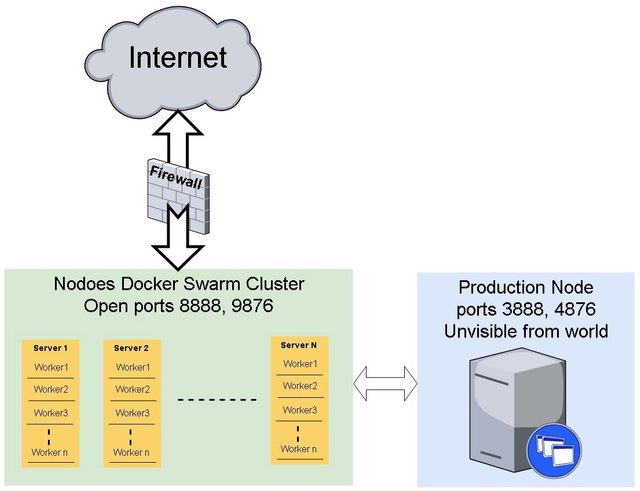
To build our cluster we will use Docker swarm: https://docs.Docker.com/engine/swarm/ .
1. Preparing
Installing Docker: https://docs.Docker.com/install/linux/Docker-ce/ubuntu/
The following instructions are for Ubuntu 16.x.
# Remove old and install new
$ sudo apt-get remove Docker Docker-engine Docker.io
$ sudo apt-get update
$ sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
$ curl -fsSL https://download.Docker.com/linux/ubuntu/gpg | sudo apt-key add -
$ sudo add-apt-repository \
"deb [arch=amd64] https://download.Docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
$ sudo apt-get update
$ sudo apt-get install Docker-ce
2. Preparing Nodeos Docker Image
For convenience, we added related files to our Github (https://github.com/CryptoLions/nodeos-docker).
We updated nodeosd.sh (https://github.com/EOSIO/eos/blob/master/Docker/nodeosd.sh) file with small update:
Wait until nodeos finished working on service stop/restart (trap for TERMSIGNAL)
Add data-dir to nodeos start line (without this option shared_mem folder was saving in container)
Routing logs to worker datadir
$ git clone https://github.com/CryptoLions/nodeos-docker
$ cd nodeos-docker
3. Building Docker container
Before building Docker Image let’s check building scenario Dockerfile. By default there is a defined EOS master branch. Our edition includes the latest release as of this writing Dawn-v3.0.0.
$ sudo docker build . -t eosio/eos:v300
By adding tag v300 it will be easier to make changes later with updates.
Lets create a swarm cluster
$ sudo docker swarm init

To add next server with worker nodes run on new server generated link.

To leave a swarm:
$ sudo docker swarm leave
To get token to connect more managers nodes use command:
$ sudo docker swarm join-token manager
Now we will prepare folders and create a service in our cluster which we can scale.
$ sudo mkdir /opt/DockerJungleNet
$ sudo mkdir /opt/DockerJungleNet/basedir
$ cd /opt/DockerJungleNet/basedir
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/config.ini
$ sudo wget https://github.com/CryptoLions/EOS-Jungle-Testnet/raw/master/genesis.json
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/peerlist.ini
$ cd ..
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/cpbasedir.sh
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/start.sh
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/start_bp.sh
$ sudo wget https://github.com/CryptoLions/nodeos-docker/raw/master/stop.sh
$ sudo https://github.com/CryptoLions/nodeos-docker/raw/master/stop_bp.sh
$ sudo chmod 777 *.sh
$ sudo ./cpbasedir.sh
By default cpbasedir.sh will copy folder “basedir” to folder 1 only. It's for the first worker to test if everything works and to sync the blockchain. Its much faster to sync only one worker (per node) instead of all workers together.
So lets synchronize one worker and then duplicate synced folders to 7 workers on that cluster node. 8 workers for test will be enough.
In start.sh we use a Docker template mapping to map for each worker separated external folder. Probably it would not be the best solution if we added many servers. For example, with 3 server and 8 workers each, this would take 24 slots. So on every server, there should then be 24 data-dir folders.
2 nodeos daemons can’t use the same folder as this folder is locked and can be used for more than one daemon.
There are few solution than came to me during this testing, but they need further study before implementing: storing all workers datadirs in special shared storage cluster one place for all workers or using Docker virtual volumes.
In this cluster we will use one server for start and then add second server to test our cluster.
First worker configured so far, and we can start nodeos as service in our cluster.
$ sudo ./start.sh

Checking logs in 1/nodeos_err.log – wee sse that node start syncing:
$ sudo tail –F 1/nodeos_err.log

OK. Part of work is done. We have one Docker cluster manager with one started nodeos worker.
Lets check logs to see if everything works correctly.
4. Check logs
$ sudo docker service rm nodeos
// or $ sudo ./stop.sh
After this command – Thanks to the logic we added in nodeosd.sh with trapping TERMSIGNAL and waiting script until nodeos stopped, it will watch for a proper nodeos daemon stop (without this update I almost always had corrupted shared_mem).
Checking logs (1/nodeos_err.log) we can see shutdown action:
5. Restart and sync
Lets start again and wait until sync.
$ sudo ./start.sh
6. Available commands
While waiting for sync, lets see what commands we can use.
List executed nodeos services.
$ sudo docker service ps nodeos

List Docker images
$ sudo docker images -a
Get Docker stdout (logs) our logs are in files so not so much useful info here for us
$ sudo docker service logs nodeos --tail 5 --raw -f
7. Clone blocks for other workers
First Worker Synced. Hurra! It took some time in our Jungle testnet, which is up to 2 Million blocks, as of today.
Ok, let's stop first worker and clone blocks folder for other workers.
$ sudo docker service rm nodeos
Wait until it stops.
$ sudo cp -R 1/blocks basedir/blocks
$ sudo cp -R 1/shared_mem basedir/shared_mem
Duplicate base folder using cpbasedir.sh to 8 slots. Also it will update config.ini in each dir with part of peers from peer list in peerlist.ini file. Tests shows that using different peers for workers on one server works much more stable.
$ sudo cpbasedir.sh 8
As we use in bind dir {{.Task.Slot}} Each work will be use own directory for storing blocks.
After this command should be 1..8 folders inside DockerJungleNet floder
8. Restart Workers
Lets start nodeos again:
$ sudo ./start.sh
Check if 1 worker started and add one more replicas:
$ sudo docker service update --replicas 2 nodeos

Checking logs in folder 2 shows that second worker started ok. Lets start all 8 prepared workers
$ sudo docker service update --replicas 8 nodeos
Now is good time to check all logs in folders 1 to 8, to check if each worker started properly.
This is our worker list:

This is not a final solution. We continue to testing and looking for improvements.
Now, if we have 3 servers with 8 workers each and all will be started – its 24 slots, that means - each server should have 24 folder with data-dir copy to be read for open slot and in one time on each server will be used only ~1/3 of these folders.
Below, I’ll add my thoughts how to make it better.
9. Connecting Production Node
First I ran production node as standalone node just using other ports, not in Docker.
But for this article decided to set up a production node using Docker. We will use only 1 replica for the production node to avoid forking. Failover of the production node will be investigated in next articles/steps.
Lets create a copy of our base dir for production node and change the config
$ sudo cp –r basedir producer
$ sudo nano producer/config.ini
Add to config row p2p-peer-address , change listening ports and add peer to our cluster
http-server-address = 0.0.0.0:3888
p2p-listen-endpoint = 0.0.0.0:4876
p2p-server-address = 127.0.0.1:4876
#addres to our nodeos cluster
p2p-peer-address = 127.0.0.1:9876
producer will be only communicate with Docker cluser, and enable producer options:
private-key = ["BP_PUB_KEY","BP_PRIV_KEY"]
producer-name = bp_name
plugin = eosio::producer_plugin
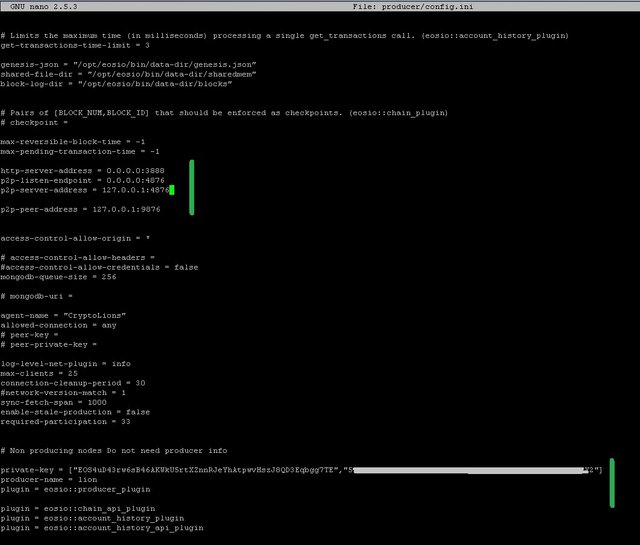
config.ini saved and we are ready to start a producer node
$ sudo ./start_bp.sh
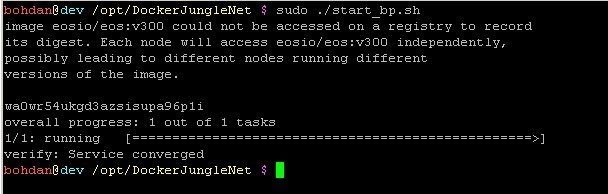
Congratulation we are Up. We have 8 workers that answer user request and one producer that works on the side.
To stop producer node:
$ sudo docker service rm nodeos_bp
// or $ sudo ./stop_bp.sh
10. Firewall
On this stage users are still able to access our producer node and can harm it with spam request. To avoid this we will put the producer behind firewall. If you use external firewall just do not allow access to producer ports. Do not forget to allow access to cluster server ports (swarm communication ports) and to non-production ports
| Ports | protocol | 1/0 | comment |
|---|---|---|---|
| 8888, 9876 | tcp | ALLOW | Non producing nodeos cluster |
| 2376,2377,7946 | tcp | ALLOW | Between swarm cluster nodes for swarm communication |
| 7946, 4789 | udp | ALLOW | Between swarm cluster nodes for swarm communication |
| 3888,4876 | tcp | DENY | Production node |
To disable access to production node using iptablse use this command
$ iptables -I DOCKER-USER -i eth0 -p tcp --dport 3888 -j DROP
$ iptables -I DOCKER-USER -i eth0 -p tcp --dport 4876 -j DROP
Now we producing blocks and no one can access this node from outside. 8 Workers work to answer user request and we easily can add more even on other servers.
Testing
Our Servers Specs:
Main Server:
Intel® Xeon® E5-1650 v3 Hexa-Core, 128 GB DDR4 ECC RAM, 2 x 240 GB 6 Gb/s SSD Datacenter Edition (RAID 1), 1 Gbit/s bandwidth
Additional Server:
Intel® Core™ i7-6700 Quad-Core Skylake, 32 GB DDR4 RAM, 2 x 250 GB 6 Gb/s SSD, 2 x 2 TB SATA 6 Gb/s Enterprise HDD; 7200 rpm, 1 Gbit/s bandwidth
We did some GetInfo() spam stress testing(нам допомагали Sayed Eos Caffe, Igor EOS RIO). Normal BP nodes failed at about 25k requests per second. (They didn't crash, they just stopped responding.) Our Docker Swarm implementation with 8 workers, withstood 42k requests per second.

We will continue testing and will share results in future articles.
In order to better evaluate our testing, we are now working on scripts that measure spam and missed requests more precisely. This will be detailed in our next article.
We created simple a bash script to send a lot get_info request while counting failed request and measuring time: https://github.com/CryptoLions/scripts/tree/master/test_request .
It works in threads and you can select what use to make request - curl or cleos.
Our local tests used this script.
================================
Workers: 5000
Failed Requests: 0
OK Requests: 500000
Total Requests: 500000
Finished. Time: 615.466653262 sec.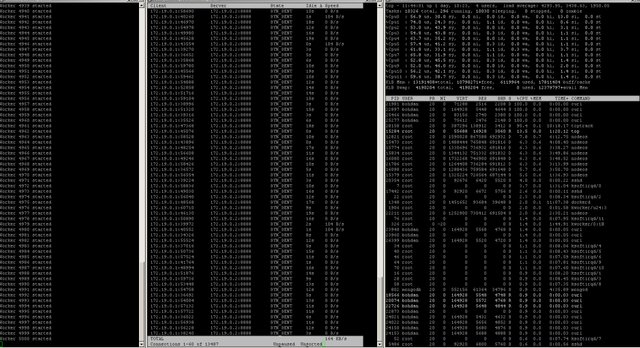
Issues still to resolve
Issues still to resolve
- Using external folders on big clusters is very inconvenient. We will investigate using Docker virtual volumes or create one storage cluster. (Important.)
- Re-syncing. It is very important is to get nodes up in the fastest way (minimize re-syncing or replaying blocks). It is very easy to corrupt blocks/shared_mem folders which makes restarting nodes impossible without deleting these folders. I have an idea to create a script which will control node state, then if node can't start with existing files, it will remove corrupted files and use archived files for a quick restart. (For example to use a separated node with only one task – each 5-10m stop and archive data-dir files.)
- Block Producer node scaling requires more investigation. We've discussed ideas with other BP teams. We're also unsure if a solution will come from block.one. Our ideas include a script which will control the producing node and in case something goes wrong, kill it and start a new one. For now we use only this very simple auto restarter script (https://github.com/CryptoLions/scripts/blob/master/restarter.sh)
===
Thank you for reading. Our modifications are here: https://github.com/CryptoLions/nodeos-docker
Please share with us your own experiments and results. We will continue testing, including testing in a virtualized environment. We will post our results.
🦁🦁🦁
http://cryptolions.io/
https://github.com/CryptoLions
https://steemit.com/@cryptolions
https://twitter.com/EOS_CryptoLions
https://www.youtube.com/channel/UCB7F-KO0mmZ1yVBCq0_1gtA
Jungle Testnet Monitor: http://jungle.cryptolions.io:9898/monitor/
General CryptoLions Chat: https://t.me/block_producer_candidate
Testnet Chat: https://t.me/jungletestnet