Creating faster C/C++ binaries without changing a single line of code
The last few years, while trying to squeeze any performance possible in CPU mining, I've tried all sorts of "peripheral" things (=changing 0 lines of code) in order to attain the best possible results.
In mining, even a 10% speed increase is crucial: If you don't have that 10% then over the course of a month's period, you've wasted 3 entire days of mining.
I will now share my hybridization technique, which I've found to be pretty effective (in some early multi-algo CPU mining algorithms - at least when most of them were still running in C instead of asm).
This technique is not only relevant for mining: It can be applied to any speed-critical application that has diverse pieces of speed-critical code inside it.
Differences in compilers
You may have heard, or even experienced first hand, that most compilers produce executables of about the same speed. This is also my experience with various versions of gcc, clang and icc.
Compilers are generally focused on having good all-around performance to cover a very wide spectrum of possible applications. This will -by necessity- create a lot of performance tradeoffs where some things will be sacrificed in order for other things to go faster - always in pursuit of good "general purpose" performance.
Yet each compiler does things a bit differently, so they are sacrificing or boosting performance on different things. So, on some very specific operations, one compiler may be much faster than another. But at the same time it can also be much slower in some other operation due to the tradeoffs involved.
Phoronix often conducts benchmarks that track the evolution of compiler performance and you can see this effect on their charts: The "Monte Carlo" process shows Clang pulling just 126 Mflops while GCC has much higher performance at 304 Mflops. Yet in "Dense LU Matrix Factorization" Clang pulls 2.9 Gflops while GCC is at 1.3 to 1.6 Gflops, depending the version.
You can also see that even GCC versions may have differences between them: For example C-ray rendering goes from 21s to 23s in GCC7, yet in Smallpt rendering GCC7 gets it down from 47 seconds to 30 (!) - a massive improvement. So on one operation there is a considerable regression, while in another operation there is a massive gain.
So, overall, it's a process of a give here, take there, with the hope that each compiler version will get a bit better overall performance - but some operations in particular have wild swings depending what a compiler brand or compiler version is tuned for.
"Arbitrage" on compiler differences
Virtually everyone I know of, accepts these things as some kind of "fact of life". There is never anything done to "arbitrage" these differences to one's advantage. People will just pick one compiler (what is considered "the faster overall" - which at this point is GCC) and they are done.
Not me though :P
What I try to do is this: Find what parts of a program get better performance with different compilers, and then hybridize these parts (some parts compiled with one compiler, other parts compiled with another) to make the ideal binary.
Case example: Hybridizing the Bitcoin Core wallet
Let's say for example I want to compile Bitcoin Core 0.13.0: This is a program with a lot of speed-critical pieces of code. In its current state, one of the bottlenecks spotted during profiling is the time spent in sha256 operations.
Now, before getting radical (like removing the cpp code and implementing optimized .asm code), one can do something much much simpler.
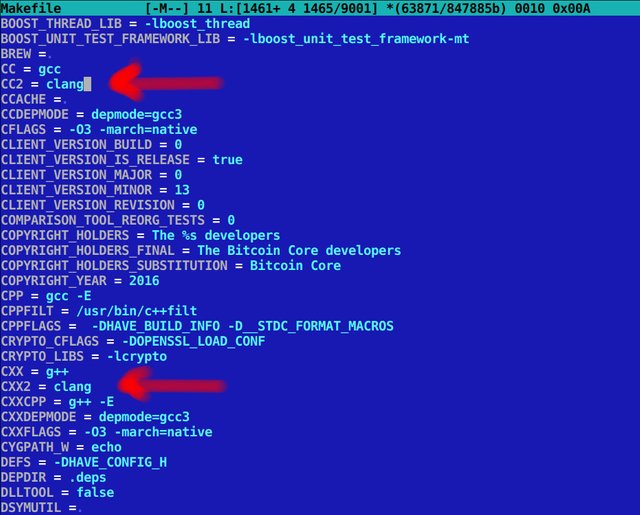
I go over to the /src/Makefile and find the lines where it says CC = gcc and CXX = g++ ...
I then add two new lines:
CC2=clang
CXX2=clang
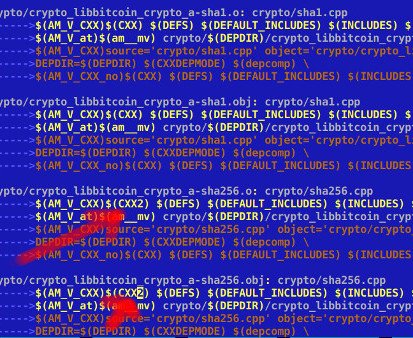
Thus any file that I now want to compile with clang, whether C or C++, I can do it pretty easily by changing the compiler variable for that file. For example, I scroll down the Makefile to the point where sha256.cpp is located. I change its compiler from CXX (gcc 6.2) to CXX2 (clang 3.8).
After finishing the compilation, I run the benchmarks:
Basiline result, with all code generated from GCC 6.2, was:
./bench_bitcoin
Benchmark,count,min,max,average
...
SHA256,112,0.004938751459122,0.009919375181198,0.009891258818763
SHA256_32b,2,0.682719469070435,0.682719469070435,0.682719469070435
...
Yet the hybrid Makefile (everything generated by GCC 6.2 except the sha256 part which was compiled with Clang 3.8) got:
./bench_bitcoin
Benchmark,count,min,max,average
...
SHA256,112,0.004781246185303,0.009601309895515,0.009570819990976
SHA256_32b,2,0.663174033164978,0.663174033164978,0.663174033164978
...
So we have over 3% speedup on SHA256 from a few letters added in a Makefile...
This also works on SHA512 and a few other stuff, but not everything (because clang is generally slower). So you have to find the areas where you can gain.
Variations of this technique
There are two variations of the above technique which I use:
1) Using more than 2 compilers (like gcc4, gcc5, gcc6, gcc7, clang, icc) - all for different parts of code. This is easily executed with Makefile amendments where one can use synonyms like CC=gcc, CC2=gcc-4, CC3=icc, CC4=clang, CC5=gcc-7, etc etc.
I've found something like that extremely useful in multi-hashing algorithms where different compilers produced different performance levels per hash type.
2) Using multiple CFLAGS (or CXXFLAGS) to better take advantage of compiler-specific features. For example ICC may have -ipo. So, one creates multiple entries like CFLAGS2, CFLAGS3 etc and assigns different CFLAGS for each entry. So when I want to change the Makefile in order to compile a particular file with icc and icc-specific flags, I just change 2 bytes and I'm done: CC (default gcc) to CC2 (icc) and CFLAGS (gcc flags) to CFLAGS2 (icc flags).
2a) There is also a subvariation is using different sets of CFLAGS, for different files, with the same compiler. This too can find us more performance compared to a setting where every single file is compiled with, say, -O3 -march=native. Some times a -flto, an -O2 or an -Os can go faster, or one may need some specific flag, which may involve unrolling or inlining, to provide a performance benefit for a specific file. In all these cases, where we do not want to change the flags for the entire program, using customized flags is a nice bonus to extract the maximum performance possible.
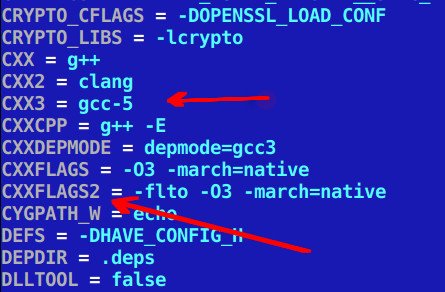
Example of declaring three compilers and two sets of cxxflags (in this case I've not used them):
CC is gcc 6.2 (system default), CC2 is clang 3.8 and CC3 is gcc 5.3:
Using the third compiler:
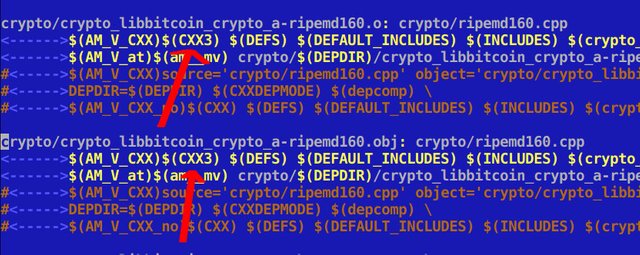
In the above case, where I tweaked RIPEMD160 with GCC 5.3 the benchmarks indicate a small speedup:
./bench_bitcoin
Benchmark,count,min,max,average
RIPEMD160,192,0.002647250890732,0.005307748913765,0.005299630264441
down to:
./bench_bitcoin
Benchmark,count,min,max,average
RIPEMD160,224,0.002588190138340,0.005190156400204,0.005183544542108
So another 2.2% speed improvement by using GCC 5.3 on that, while the rest of the program is on GCC 6.2 (and SHA256 is done with clang).
Even if one picks up small differences here and there, like 2-5%, if there are many pieces of speed-critical code, it is very likely that some compiler or some flag will be better for a particular piece of code.
It is also very unlikely that just one compiler will have the best solution for everything - and this is precisely the basis of this technique: The more differences there are between compilers and flags, the more one can gain through hybrid solutions.
Conclusion
As long as there are differences in speed between flags, compilers, etc, one can utilize multiple compilers and flags to "arbitrage" these differences and make the fastest binary possible. One can do so by manually tweaking the Makefile and provided they have multiple compilers installed.
I didn't know you were a software engineer :). Awesome information, I've never used anything but Microsoft's C++ compiler packaged with Visual Studio. Thanks for giving me some insight into GCC, Clang and makefiles.
I'm not :) I'm just a "power user" :P
lol right... :P
As a non programmer - I understood nothing of what I saw....but I can tell this post is educationally value add so upvote city! :-)
Thanks :D I will try to explain it in simple terms even for non-programmers.
When a programmer writes some code, like
"IF temp_sensor > 150 THEN shutdown" (when the temperature rises over 150, then activate a shutdown routine),
...this then needs to be translated from human-readable language to machine language that our CPU can understand.
The machine language is generated by a "compiler". A program that converts our language to the language of the cpu.
Each compiler may take the human-readable code and create different machine code. If you have two compilers, you may have one which creates machine code that takes 1 second to perform the desired function, and another compiler producing more inefficient machine code which takes 2 second to perform it.
So what you want to do is to find the best possible compiler for your speed-critical operations, in order to waste as little time as possible. And this can be done by editing a text file (known as Makefile) which dictates how a program will be compiled file-by-file. So some files you send through one compiler, and some others through another compiler, trying to reduce the time wasted by inefficient machine code.
For example, a web browser consists of thousands of program files. Some are very speed critical - like video algorithms. If these are slow, then your experience in watching youtube suffers. You want the best possible compilers on the job to get the smoothest video possible.
I've officially entered the matrix! :-)
Thank you for the explanation - that made sense.