[논문 소개] Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning
- 논문 정보
- 논문 제목: Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning
- 논문 링크: https://www.nature.com/articles/s41551-018-0195-0
- 저널: Nature Biomedical Engineering
2016년 JAMA라는 좋은 저널에 안저영상으로 당뇨성 망막병증 진단으로 논문을 내서 이슈가 되었던 Google Brain 팀에서 이번에 안저영상을 통해 심혈관 위험인자를 예측하는 연구를 Nature Biomedical Engineering에 발표했습니다. (그룹에 의료쪽으로 하시는 분도 계시지만, 다른 분들에게는 그닥 도움이 안 되는 논문일 수 있습니다. 물론.. 저따위에게도..)
일단 이 분야에 계신 분이라면 데이터에 대해서 가장 먼저 궁금해 하실건데, UK Biobank (http://www.ukbiobank.ac.uk/about-biobank-uk)와 EyePACS (http://www.eyepacs.org)에서 28만명 이상의 환자의 학습 데이터와 각각 12,026명과 999명의 환자의 검증 데이터 셋을 확보했습니다. 좋은 데이터가 좋은 알고리즘과 논문을 만들어 내는 거 같네요. 특히 UK Biobank가 잘 되어 있는 이후 런던쪽 학교와 구글에서 좋은 연구가 더 잘 나오는거 같습니다.
이제 연구 내용은 안저 영상을 통해 몇몇 심혈관 병증의 요인이 보인다고 합니다. 그리고 구글브레인은 안저영상을 잘 해 본 경험이 있기에 안저 영상을 통해 이런 인자들을 예측해 봅니다. 나이, 흡연의 유무, 등등등 뭐 어떤 건 잘 되고, 어떤건 예측이 잘 안 됩니다. 그런 과정을 통해 안저영상에 딥러닝을 적용하여 이러한 요인들을 예측할 수 있는지를 분석하고 두개의 데이터셋에서 그것을 분석합니다.
또한 그러한 인자 예측을 통해 5년 내에 심혈관 이상 이벤트가 있을지 예측해 보니, 70% 이상으로 예측할 수 있었다는 결과를 말하고 있습니다.
음.. 여기까지가 논문 내용 요약이구요.
재밋었던 점은 논문의 한 테이블의 이름이 "Table 6 | Percentage of the 100 attention heat maps for which doctors agreed that the heat map highlighted the given feature" 입니다. 딥러닝 알고리즘이 어딜 보는지 attention heat maps으로 대략적으로 확인하고 그걸 가지고 의사들이 다시 봐서 얘들 이렇게 놀고 있구나~ 하고 확인한거 같습니다.
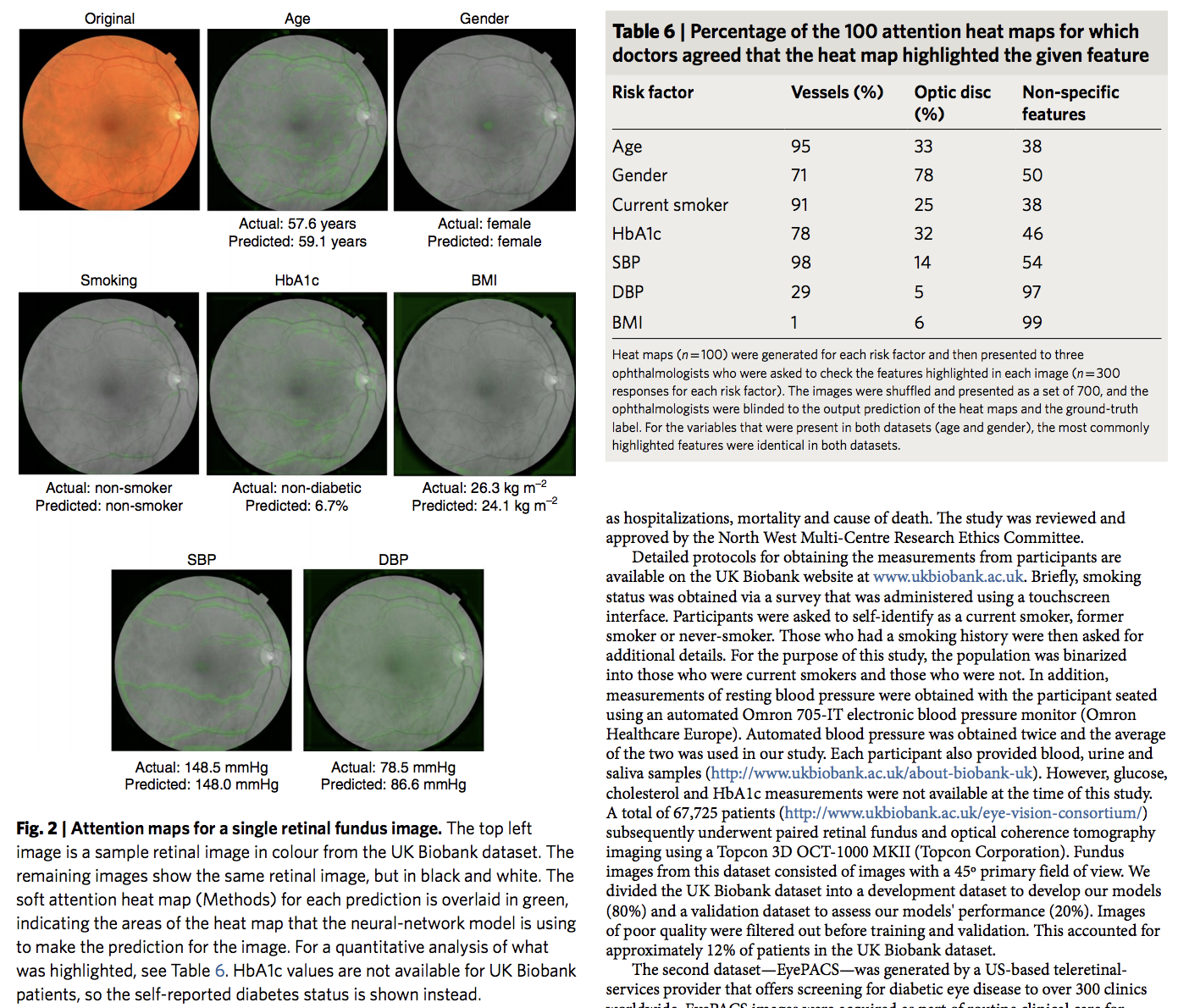
그런데... 음.. 이 논문은 Nature에 나왔지만, 구글이라서 되었을거 같다는 생각이 강합니다.당뇨성 망막변증을 안저 영상으로 진단하는 JAMA 논문을 낸 팀의 논문이고, 나름 의미가 있지만.... 이 논문의 결과를 가지고 많은 신문, 블로그에서 "망막 스캔으로 심장질환 발병가능성을 진단하는 AI 기술"처럼 뭔가 진단할 수있는 혹은 임상에 적용할 수 있는 기술이 이미 나와 혁신을 한것인냥 보도가 나옵니다. 그러나... 이 논문 깔게 아직은 너무 많습니다.
HbA1C, 고혈압, 고지혈증, 고령, 남성, 비만(BMI), 흡연 등은 논문에서 최종적으로 예측하려고 하는 major advere cardiovasc event(MACE)의 predisposing risk factor입니다. 이들 위험인자(특히 당뇨)들이 오랜 기간 지속되면 동맥경화로 macro- and microvascular complication을 일으키고 최종 진행단계에서, 결국 TOF(target organ failure)가 발생하는데, MACE는 심장혈관의 TOF입니다. 그러므로 논문의 내용은 TOF에 해당하는 안저소견으로 predisposing factor를 예측하는 것은 '결과'로 '원인'을 예측하는 격이 됩니다. 당연히 관계는 있으므로 유의한 상관관계는 얻을 수 있겠지만, 인과관계가 뒤집힐 수 있어 해석상의 오류 가능성이 높습니다.
그리고 예측하는 risk factor 여부는 환자에게 질문하면 얻을 수 있는 것들이 대부분입니다. 한마디로 안저검사까지 할 필요는 없죠. 기사에서는 혈액검사만큼 좋다고 나오는데, 논문 결과로 보면 혈압, BMI, gender, 나이, 흡연여부만 넣어도 72%입니다. 참조 논문이나 다른 임상 논문을 다시 혈액이나 기본적인 검사만으로도 80%이상이구요. 물론 MACE를 위해 가기 전단계의 과정으로 학습 (뭐 멀티 테스크 러닝 정도의 이유로..) 했다 하더라도 인과관계가 뒤집힐 수 있는 상황이니 그건 무리수구요.
결과에서 당뇨 여부와 상관없이 결과가 안정적으로 나온다고 주장하였는데, MACE의 매우 중요한 위험인자 당뇨 유병기간, 공복혈당, 혈당조절 상태(HbA1C) 등 당뇨에 관한 변수가 완전히 빠져 있습니다. 또한 데이터베이스 구성에서 보면 전체 환자의 55% 만이 HbA1c 정보를 갖고 있었고, 심지어 '환자 말'만 듣고 당뇨 진단 내린 경우들도 있어서, 당뇨 변수 정의나 진단 자체를 신뢰하기 어려운 데이터입니다. 그런데 당뇨와 관계가 없다고 하는건 좀 무리가..
그리고 데이터 베이스를 아예 독립적으로 가져가지 않고, 결국 두 데이터 베이스 다 학습에 일부 썼습니다. 일단 external validation이 안 되어 있다고 보입니다. -_-..
당뇨와 관계 없다고 하지만, 학습 데이터 대부분이 당뇨환자인 데이터베이스가 주이므로 코호트가 바이어스되었고, 전체 환자의 16% 만이 MACE(primary endpoint) 정보를 갖고 있었으므로, 결국 MACE 모델링에는 레이블을 가진 16%의 환자만 포함된 제한적인 환경에서 이루어졌습니다. 데이터베이스의 양과 두 데이터베이스란 점을 주장했지만 여전히 문제가 많아 보입니다.
등등등등 깔게 많은데요.
그럼에도 불국하고 네이쳐에 나왔으니, 그리고 여기저기서 의료 혁신을 이루었다고 광고하니 만약 어느 스타트업에서 했으면 투자 받기 딱 좋은 연구 같습니다.
그런데 제가 보기엔 JAMA를 쓴 구글에서 했고, 대규모 데이터베이스를 쓴 점이 아니라면 이런 저널에 억셉이 되었을까 싶습니다. 그럴싸한 논문과 현실과 차이가 엄청난데 논문 하나 좋은데 되었다고 문제를 해결했다고 하는 식의 기사는 그냥 마케팅 기사같아 보이고요.
논문에서 이때까지 이런 논문에서 시도 안 한 방식의 실험 검증이 나와 좋게 읽었으나 여러 기사들을 보니 우리 그룹에서도 논문이 네이쳐~ 라고 하면 비판이 너무 없는게 아닌가 해서 제가 읽고, 그리고 같이 읽은 분들이 비판 내용을 조금 공유드립니다. 뭐 구글이 하면 좋은데 실리고 기사에서 마케팅도 해주고 좋으나... 그렇다고 뭐 다 좋은건 아닌데..
그리고 많은 스타트업들이나 기업들이 문제를 해결하기 위해 제대로 해야 할건 안 하고 광고하기 좋은 논문을 내고 그걸로 투자 받기도 하시는데.. 그럴 때마다 이 분야를 열심히 공부하시는 분들이 더 비판적으로 읽고 까야 제대로 하지 않을까 싶네요.