Introduction to the SHA-256 hash function
Introduction to the SHA-256 hash function
This article aims to give an introduction into the SHA-256 hash algorithm. It is accompanied by a Java-implementation at https://github.com/f4tca7/Sha256 (2). SHA-256 was chosen as it's one of the most commonly used (and state-of-the-art) hash functions in existence. Also, if someone understands SHA-256, understanding the other hash functions of the SHA-2 family is an easy task.
The main motivation for this article was to give readers interested in how SHA-2 hash functions work a more "gentle" description, compared to the very formal articles that I found were predominant (e.g. at Wikipedia or NIST).
This article is aimed at people with a working knowledge of Java or a similar programming language and who are somewhat familiar with bitwise operations.
Hash Functions
- A hash function takes an arbitrary string as input. The input is commonly called "message".
- It produces an output that is FIXED in length. For SHA-256 the output is always 256 bit long. The output is commonly called "Message Digest" or "Hash Value" or just "Hash". Below, hash function outputs will be called
H(x) - Its algorithm finishes in a reasonable amount of time
- It's useful to compare two messages for equality, even if we don't know the messages themselves. Meaning that we can say if
H(x) = H(y), also message x = message y
Security Properties Of Hash Functions
The below properties aim to give an idea of what's required for a secure cryptographic hash function. It's not intended to be a comprehensive list.
- Hiding property (or Pre-image resistance): Just knowing
H(x), you cannot deductx. However, this only holds up if messagexis not chosen from a "likely" set of values. "Likely" here means that x cannot be realistically guessed by an attacker. - Collision Free: A collision occurs if for two different messages the same hash value is calculated. "Collision free" means that it is infeasible to find two messages
xandy, withx != y, so thatH(x) = H(y). Meaning it should be near impossible that two different messages result in the same hash value. Now, of course collisions will always exist because the number of possible inputs (an input can be of any size) is far larger than the number of possible outputs (an output is always of a fixed length). However, for SHA-2 hash functions, the effort require to find those collisions is enormous. - Puzzle friendliness, especially relevant for cryptocurrencies:
- Suppose we know two values
xandy.xis part of the hash function input message,yis the hash function output. - A hash function is puzzle friendly if it is infeasible to find a third value
k, so that H(k | x ) = y.k | xmeans just concatenation ofkandx(e.g. ifk = 1100andx = 0011thenk | x = 1100 0011). - We assume
kto be a random value from a very spread-out set of values. - This property is e.g. used to construct the Bitcoin proof-of-work mining puzzle. Here a miner has to iterate over
k(xis given in this scenario, it is a hash of the block that's being mined), and tries to find a valueythat is in a certain range. For bitcoin concretely,yneeds to be smaller than a specific value determined roughly every two weeks by the Bitcoin software.
- Suppose we know two values
SHA-2
- SHA stands for "Secure Hash Algorithm"
- SHA-2 is a family of cryptographic hash functions
- All members of the SHA-2 family share the same general approach and algorithm, but differ in sizes and constraints of inputs, outputs and working variables. For example, when working on a 32-bit architecture, it might make more sense to use SHA-256 instead of SHA-512, because SHA-256 works with 32-bit words, whereas SHA-512 works with 64-bit words.
Members of the SHA-2 family are:
| Algorithm | Message Size (bits) | Block Size (bits) | Word Size (bits) | Message Digest Size (bits) |
|---|---|---|---|---|
| SHA-224 | < 2^64 | 512 | 32 | 224 |
| SHA-256 | < 2^64 | 512 | 32 | 256 |
| SHA-384 | < 2^128 | 1024 | 64 | 384 |
| SHA-512 | < 2^128 | 1024 | 64 | 512 |
| SHA-512/224 | < 2^128 | 1024 | 64 | 224 |
| SHA-512/256 | < 2^128 | 1024 | 64 | 256 |
Table from 1
SHA-256
This section will introduce the SHA-256 algorithm itself. It is mainly based on the NIST description found at
http://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf (1)
High-level Overview
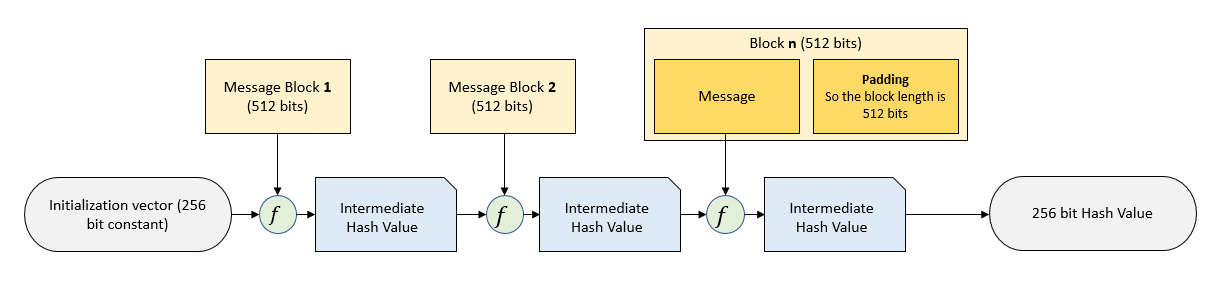
On a high level, SHA-256 works like this:
- Take the input message and make sure its length (in bits) a multiple of 512 bits. This is done by adding a padding.
- Take the passed message and parse it into
N512-bit blocks. - Iterate over all blocks from step 2:
- Initialize the message schedule, a sequence of 64 32-bit words
- Initialize eight working variables
a ... hwith the hash valuesH0 ... H7from the previous iteration (for the first iteration,H0 ... H7are initialized with constants). - Perform 64 iterations where working variables
a ... hare rotated in a certain manner. This is the heart of the hash function. In this step, the message is inserted into the hash using lots of bitwise mixing. - Compute the new intermediate hash values
H0 ... H7asH0 = H0 + a,H1 = H1 + band so on.
- Concatenate
H0 ... H7as the message digest and return it.
Step 1: Pad the input message

Before beginning to process the message, we have to add a padding. This is to make sure the message length (in bits) is a multiple of 512. The reason is that the algorithm will process the input message block-by-block, each block having a length of 512 bit.
SHA-2 uses a 10 * l padding scheme, meaning a 1 bit is appended, followed by many zeros, followed by the length l of the input message.
Padding of the message works as follows:
- Append one bit
1to the message - Fill up with zeros until the message is a multiple by 512
- Construct message length
las 64 bit number, and insert (not append) it to the end of the padding
Example:
- Message: "abc" =
0110 0001 0110 0010 0110 0011 - Add bit
1:0110 0001 0110 0010 0110 0011 1 - Add zeros so the message is a multiple of 512. In this case, the message length is 24 plus one for the bit we added. That means we have to append
512 - 1 - 24 = 487zeros:0110 0001 0110 0010 0110 0011 1 00 ... 487 zeros - Now, insert the message length as 64-bit number. Message length is 24 decimal which is
0001 1000binary. So our message will look like0110 0001 0110 0010 0110 0011 1 00 ... 00 00 .. 0001 1000. - Finally the padded message consists of:
- The message input (24bit)
- One bit
1 - 423 zero bits
- 64 bit block with the message length
- ... in total 512 bit
A sample Java implementation of padding a message can be found at (2) in method private byte[] padMsg(byte[] msg)
Step 2: Parse the message into 512-bit blocks
Now that we have the message as multiple of 512, we need to cut it down into digestible chunks.
This is rather straightforward, we take the message and split it into N 512-bit/64-byte blocks.
Each block itself is split into sixteen 32-bit words. Reason is that each of those words will be addressed during further processing.
A sample Java implementation of padding a message can be found at (2) in method private byte [][] parseMsg(byte[] paddedMsg)
Step 3: Iterate over N blocks
Perform N iterations, meaning one iteration for each block of the input message.
In the following description, index i will be used as index for this iteration
Helper functions operations and constants
- An addition
+is defined as addition modulo 2^32. Basically, this means that we cut off everything that wouldn't fit into a 32-bit word. Note that in the Java implementation at (2), regular addition is used. This is because we work with 32-bit integers here, so an addition is implicitly modulo 2^32.
A number of helper functions are referenced below. Those are described in more detail in section "Helper Functions". Basically, they are used to create bitwise mixers, where multiple inputs form one output, and it's infeasible to deduct the inputs knowing only the output.
- Sigma0
- Sigma1
- Ch
- Maj
- ROTR
Two sets of constants are used:
- Eight 32-bit words for the initial hash values of
H0 ... H7 - Sixty-four 32-bit words
K0 ... K63used in the hash computation
3.1 : Prepare the message schedule
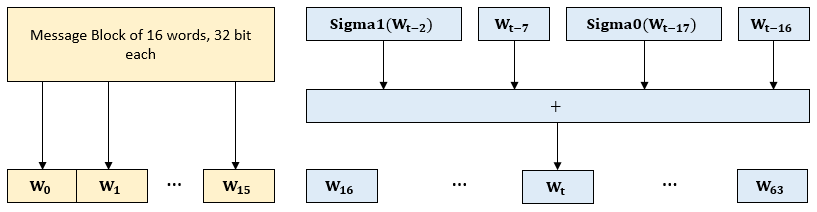
The message schedule is a sequence of 64 32-bit words which will be used in a later stage. It is constructed as:
W[t] = M[i][t] for 0 <= t <= 15. M[i] is the message block that is currently processed in the top-level loop
W[t] = Sigma1(W[t-2]) + W[t-7] + Sigma0(W[t-17]) + W[t-16] for 16 <= t <= 63.
A sample implementation of message schedule construction can be found in (2) in function private void fillWords(byte[] block)
3.2 : Initialize working variables
In this step we use eight working variables a ... h. Those variables will be used to update the hash value in one step of the iteration.
- In the first iteration,
a ... hare initialized with constants (see section "Constants" or 1, section 5.3.3). - In each subsequent iteration,
a ... hare initialized with the hash valuesH0 ... H7from the previous iteration
For a code sample of T1, T2 computation, see // 2. Initialize working variables with hash values of previous iteration in private byte[] digestMsg(byte[][] parsedMsg) in 2.
3.3 Compute the working variables
In this step, we perform 64 iterations t = 0 ... 63.
In each iteration, we shift the values of the working variables to the right, so that h = g, g = f, f = e and so on.
Additionally, we compute values of working variables a and e as follows:
e = d + T1
a = T1 + T2
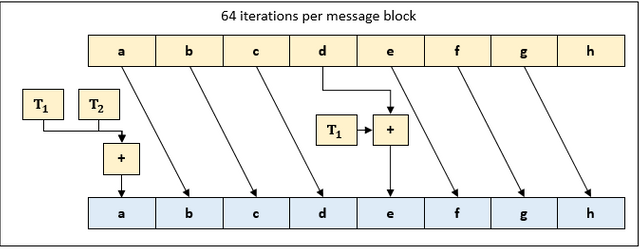
T1 and T2 are temporary values which are computed as follows:
T1 = h + Sum1(e) + Ch(e, f, g) + K[t] + W[t]
T2 = Sum0(a) + Maj(a, b, c)
T1 and T2 serve the purpose of mixing the message into the hash value. They are designed so that it's infeasible to conclude the inputs of T1, T2 if only the output is known.
For a code sample of T1, T2 computation, see // 3. Compute updated working variables in private byte[] digestMsg(byte[][] parsedMsg) in 2.
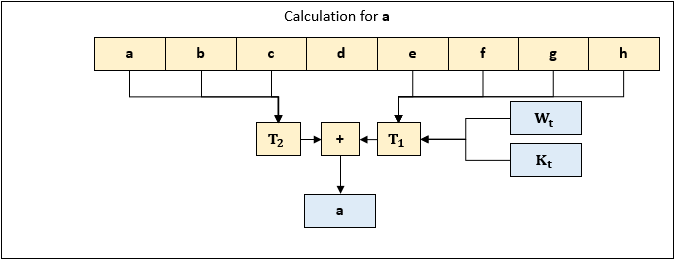
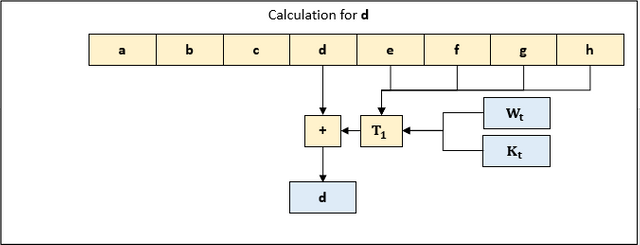
Leading to a complete iteration that looks like:
T1 = h + Sum1(e) + Ch(e, f, g) + K[t] + W[t]
T2 = Sum0(a) + Maj(a, b, c)
h = g
g = f
f = e
e = d + T1
d = c
c = b
b = a
a = T1 + T2
For a code sample, see // 3. Compute updated working variables in private byte[] digestMsg(byte[][] parsedMsg) in 2.
3.4 Update hash values
After computing the working variables a ... h, the new intermediate hash values are calculated. This is done by a simple addition to of a ... h to the hash values of the previous iteration H0 ... H7, so that H0 = a + H0, H1 = b + H1 and so on
For a code sample, see 4. Update hash values in private byte[] digestMsg(byte[][] parsedMsg) in (2).
4. Finalize the hash value
After running one iteration for each message block, the hash values H0 ... H7 are concatenated into one 256-bit hash value.
For a code sample see the bottom of method private byte[] digestMsg(byte[][] parsedMsg) in (2).
Helper functions
A number of helper functions are employed in the hash calculation. This section adds further explanation and gives examples for better understanding.
ROTR ... "Rotate Right" function
A bitwise rotate right is a right shift where the overflow is added to the left side. In the sample below, we rotate the integer 124 right by 2 bits. int the result you see that the two least significant bits 01 of the input become the two most significant bits of the output.
/**
* Sample for ROTR(2, 124)
*
* | is the bitwise OR operator
* >>> is the bitwise UNSIGNED RIGHT SHIFT operator (meaning the output will always be filled with zeros from the left)
* << is the bitwise LEFT SHIFT operator
*
*
* n: 2
* x: 0000 0000 0000 0000 0000 0000 0111 1101
* x >> 2: 0000 0000 0000 0000 0000 0000 0001 1111
* x << (32-n): 0100 0000 0000 0000 0000 0000 0000 0000
* ----------------------------------------------------
*(x >>> n) | (x << (32-n)):
* 0100 0000 0000 0000 0000 0000 0001 1111
*/
private int ROTR(int n, int x) {
return (x >>> n) | (x << (32-n));
}
Ch(x, y, z) ... "Choose" function
Ch stands for "Choose". If bit at position n in input x == 1, then bit n in result is the same as bit n of input y. Otherwise, take bit n of input z.
In the result below, you see the four most significant bits are 1111. Thus, the value of input y is chosen for the output (0000). The opposite for the four least significant bits.
/**
* Sample
* & is the bitwise AND operator
* ^ is the bitwise XOR operator
* ~ is the bitwise INVERSE operator
*
*
* x: 1111 0000
* y: 0000 0000
* z: 1111 1111
* ------------
* -> 0000 1111
*
* x & y:
* 1111 0000
* & 0000 0000
* = 0000 0000
*
* ~x & z
* 0000 1111
* & 1111 1111
* = 0000 1111
*
* (x & y) ^ (~x & z )
* 0000 0000
* ^ 0000 1111
* = 0000 1111
*
* @return
*/
private int Ch(int x, int y, int z) {
return (x & y) ^ (~x & z);
}
Maj(x, y, z) ... "Majority" function
Maj stands for "Majority". If a minimum 2 of 3 bits at position n in inputs x, y, z are 1, the majority of bits is considered 1. Thus, bit at position n in result will be 1. Otherwise 0.
/**
* Sample
* & is the bitwise AND operator
* ^ is the bitwise XOR operator
*
* x: 1101 1101
* y: 1011 0011
* z: 1101 0011
* ------------
* -> 1101 0011
*
* x & y:
* 1101 1101
* & 1011 0011
* = 1001 0001
*
* x & z:
* 1101 1101
* & 1101 0011
* = 1101 0001
*
* y & z:
* 1011 0011
* & 1101 0011
* = 1001 0011
*
* (x & y) ^ (x & z ) ^ (y & z )
* 1001 0001
* ^ 1101 0001
* ^ 1001 0011
* = 1101 0011
*/
private int Maj(int x, int y, int z) {
return (x & y) ^ (x & z ) ^ (y & z );
}
Sum0(x)
/**
* ^ is the bitwise XOR operator
*
* Sample for:
*x = 0110 1010 0000 1001 1110 0110 0110 0111:
*
* ROTR(2, x):
* 1101 1010 1000 0010 0111 1001 1001 1001
*
* ROTR(13, x):
* 0011 0011 0011 1011 0101 0000 0100 1111
*
* ROTR(22, x):
* 0010 0111 1001 1001 1001 1101 1010 1000
*
* 1101 1010 1000 0010 0111 1001 1001 1001
* ^ 0011 0011 0011 1011 0101 0000 0100 1111
* ^ 0010 0111 1001 1001 1001 1101 1010 1000
* -----------------------------------------
* 1100 1110 0010 0000 1011 0100 0111 1110
*
*/
private int Sum0(int x) {
int a = ROTR(2, x);
int b = ROTR(13, x);
int c = ROTR(22, x);
int ret = a ^ b ^ c;
return ret;
}
Sum1(x)
/**
* Sample for
*x = 1111 1010 0010 1010 0100 0110 0000 0110:
*
* ROTR(6, x):
* 0001 1011 1110 1000 1010 1001 0001 1000
*
* ROTR(11, x):
* 1100 0000 1101 1111 0100 0101 0100 1000
*
* ROTR(25, x):
* 0001 0101 0010 0011 0000 0011 0111 1101
*
* 0001 1011 1110 1000 1010 1001 0001 1000
* ^ 1100 0000 1101 1111 0100 0101 0100 1000
* ^ 0001 0101 0010 0011 0000 0011 0111 1101
* -----------------------------------------
* 1100 1110 0001 0100 1110 1111 0010 1101
*
*
*/
private int Sum1(int x) {
int a = ROTR(6, x);
int b = ROTR(11, x);
int c = ROTR(25, x);
int ret = a ^ b ^ c;
return ret;
}
Sigma0(x)
/**
* ^ is the bitwise XOR operator
*
* Sample for
*x = 0110 0010 0110 0011 0110 0100 0110 0101:
*
* ROTR(7, x):
* 1100 1010 1100 0100 1100 0110 1100 1000
*
* ROTR(18, x):
* 1101 1001 0001 1001 0101 1000 1001 1000
*
* x >>> 3:
* 0000 1100 0100 1100 0110 1100 1000 1100
*
* 1100 1010 1100 0100 1100 0110 1100 1000
* ^ 1101 1001 0001 1001 0101 1000 1001 1000
* ^ 0000 1100 0100 1100 0110 1100 1000 1100
* -----------------------------------------
* 0001 1111 1001 0001 1111 0010 1101 1100
*
*
*/
private int Sigma0(int x) {
int a = ROTR(7, x);
int b = ROTR(18, x);
int c = x >>> 3;
int ret = a ^ b ^ c;
return ret;
}
Sigma1(x)
/**
* ^ is the bitwise XOR operator
*
* Sample for
*x = 1110 1011 1000 0000 0001 0010 1010 1101:
*
* ROTR(17, x):
* 0000 1001 0101 0110 1111 0101 1100 0000
*
* ROTR(19, x):
* 0000 0010 0101 0101 1011 1101 0111 0000
*
* x >>> 10:
* 0000 0000 0011 1010 1110 0000 0000 0100
*
* 0000 1001 0101 0110 1111 0101 1100 0000
* ^ 0000 0010 0101 0101 1011 1101 0111 0000
* ^ 0000 0000 0011 1010 1110 0000 0000 0100
* -----------------------------------------
* 0000 1011 0011 1001 1010 1000 1011 0100
*
*/
private int Sigma1(int x) {
int a = ROTR(17, x);
int b = ROTR(19, x);
int c = x >>> 10;
int ret = a ^ b ^ c;
return ret;
}
Constants
// Section 5.5.3
H = { 0x6a09e667, 0xbb67ae85, 0x3c6ef372, 0xa54ff53a, 0x510e527f, 0x9b05688c, 0x1f83d9ab, 0x5be0cd19 };
K = { 0x428a2f98, 0x71374491, 0xb5c0fbcf, 0xe9b5dba5, 0x3956c25b, 0x59f111f1, 0x923f82a4, 0xab1c5ed5,
0xd807aa98, 0x12835b01, 0x243185be, 0x550c7dc3, 0x72be5d74, 0x80deb1fe, 0x9bdc06a7, 0xc19bf174,
0xe49b69c1, 0xefbe4786, 0x0fc19dc6, 0x240ca1cc, 0x2de92c6f, 0x4a7484aa, 0x5cb0a9dc, 0x76f988da,
0x983e5152, 0xa831c66d, 0xb00327c8, 0xbf597fc7, 0xc6e00bf3, 0xd5a79147, 0x06ca6351, 0x14292967,
0x27b70a85, 0x2e1b2138, 0x4d2c6dfc, 0x53380d13, 0x650a7354, 0x766a0abb, 0x81c2c92e, 0x92722c85,
0xa2bfe8a1, 0xa81a664b, 0xc24b8b70, 0xc76c51a3, 0xd192e819, 0xd6990624, 0xf40e3585, 0x106aa070,
0x19a4c116, 0x1e376c08, 0x2748774c, 0x34b0bcb5, 0x391c0cb3, 0x4ed8aa4a, 0x5b9cca4f, 0x682e6ff3,
0x748f82ee, 0x78a5636f, 0x84c87814, 0x8cc70208, 0x90befffa, 0xa4506ceb, 0xbef9a3f7, 0xc67178f2 };
Great post with good detail. I appreciated how you broke down the message padding and the block parsing. I also really appreciated the high-level concept overviews. Very helpful for newbie like me :)
Congratulations @f4tca7! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!