Scaling, Decentralization, Security of Distributed Ledgers (part 2)
Click Here to read Part 1 of this blog.
Directed Acyclic Graphs (DAGs)
The following other than the new section on Hashgraph was originally written November 2016 and August 2017 and I haven’t checked if of these findings have changed hence. Likely not.
Transaction or block DAGs are composed of descendant transactions or blocks which back-reference to antecedent transaction(s) or block(s) which were each formerly a tip (aka leaf) branch of the DAG as illustrated below:
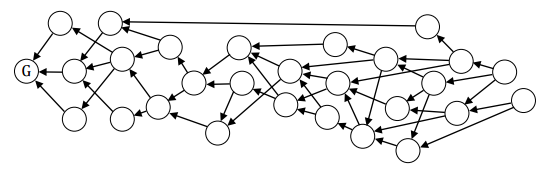
Figure 1: Partial orders of an unsynchronized DAG.
Byteball

Byteball and Hashgraph’s Swirlds are the only transaction DAG designs which are somewhat sound yet with some flaws.
Both are nondeterministic Byzantine fault tolerant (BFT) consensus systems with 100% probability of finality (aka “non-asymptotic”) within the liveness and safety tolerance thresholds.
The validators (named “witnesses” in Byteball and “members” in Hashgraph) act independently, nondeterministically, and devoid of any probabilistic algorithm. Contrast this with Byzantine agreement which employs a deterministic algorithm for voting in epochs—or probabilistic BFT (PBFT) which employs a probabilistic algorithm—that validators implement to express their vote on the consensus agreement. Nakamoto proof-of-work which also has nondeterministic miners as validators but only (hopefully asymptotic4) probabilistic finality.†
4 Except Satoshi meticulously designed hashed public-key addresses to protect private keys against quantum computing thus surely knowing Nakamoto proof-of-work is vulnerable to a long-range attack by future quantum computers but never mentioned it. See also some further discussion.
† My analysis of OmniLedger provides an informal explanation which distinguishes BFT consensus systems with 100% probability from those with probabilistic finality such as Nakamoto proof-of-work.
Byteball’s “Stability Point” Total Order
Here’s my attempt at the most straightforward and succinct possible explanation of how Byteball’s consensus system works.
Payers publish signed transactions to the peer-to-peer (P2P) network spontaneously without any permission or reliance on any other node or participant. The published transactions are the vertices in Byteball’s directed acyclic graph (aka DAG) which are named “units” in the whitepaper. Unlike Nakamoto proof-of-work or the many variants of proof-of-stake, there’s no miners nor validators which must receive the transactions and insert them in a block. There are no blocks.
Each newly published transaction back-references the antecedent transaction units chosen by the signer of the new transaction. The chosen ancestors thus become parents of the new transaction.
The §2. Database structure on pg. 5 of the Byteball whitepaper explains that the transitive referencing of ancestor units in the Byteball DAG is conceptually analogous to TaPoS5, except that due to providing unbounded participation in the BFT consensus with no synchronous requirements on the network (i.e. no bound on the time taken for witnesses to publish their observation units), the transactions aren’t strictly required to reference a total order. Yet to be relevant in the “stability point” total order created by the majority of witness observations, transactions must be eventually consistent in referencing the said total order.
The stability point algorithm is able to achieve BFT with non-asymptotic, 100% probability of finality6 (i.e. eventual within bounded but unspecific time with a probability of 1 if the fault tolerance is not exceeded for unbounded time; otherwise never completes) with only ¹/₂+ quorums because the ordering of the published witness observation units (which are analogous to validator votes) is orthogonal to (i.e. no dependencies on) those of the other witnesses. Whereas, the §Math of safety & liveness7 for deterministic Byzantine agreement requires +²/₃ quorums because validators coordinate by voting in quorums wherein each validator can legitimately vote in more than one quorum because they can legitimately claim the unresponsiveness of the other validators in forming any instance of a quorum. Whereas, in Byteball witnesses are only allowed to vote once per stability point quorum.
5 Key design decision prompted by myself and another summary.
6 The reformulation of BFT has been proven for ≥ (N + 1)/2 (aka “¹/₂+”, “50+%”, or erroneously “51%”) responsive nodes in the case where all nodes that communicate do so correctly and otherwise ≤ (N - 1)/3 (aka “-¹/₃”) unresponsive and/or incorrect nodes, where N is the total number of nodes.
7 C.f. also footnote ² in Minimal Slashing Conditions which is related to this and fork*-consistency. Tangentially, my explanation of the proposed Proof-of-Approval proof-of-stake consensus system is an example of the application of that BFT math to vulnerability analysis.
Byteball’s “Stability Point” Rule
Witnesses create and sign transaction units (i.e. vertices in the DAG) which are observations of valid ancestor history. Witnesses must validate every transaction and check for double-spends in the ancestor lineage of the parents of the observation unit the witness has created. The witness will not include any parent that has violations. So that the stability points consensus moves forward and doesn’t degenerate to competing branches, witnesses must also follow the rule that they include their prior observation units in the lineage of every new observation unit they publish. Any honest observer can re-validate the witness observation units to check that witnesses are obeying the rules. Any witness that disobeys the rules must be ignored by all participants when computing the stability points.
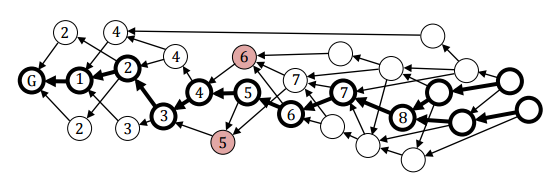
Figure 2: Byteball’s “stability points” with genesis unit labeled “G”.
The total order is defined by a rule which selects a unique, deterministically stable (i.e. final, total) path through the unbounded plurality of possible (partial orders) paths in the DAG. One choice for a total order definition is walking the DAG from the initial “stability point” of the genesis unit while counting the number witness observation units visited. But not counting the same witness twice for the same stability point candidate; and not counting any observation unit which (transitively) references the prior observation unit of the same witness when the said prior observation unit would form a competing candidate path. When a majority of the witnesses have been counted via this rule, a candidate for the next stability point is identified as the last witness observation unit counted that attained the said majority. The chosen unique stability point is the candidate with the longest path from the prior stability point, with a tiebreaker being the lesser of the hashes of the candidate units and if those are equal then the lesser witness id. However, for the reasons stated in #2 below, it might be desirable to increase the safety of the stability point algorithm to count to a threshold of +²/₃ of the witnesses.
The longest path is an arbitrary rule choice that maximizes the number of paths (aka branches) of the DAG visited by stability points, in order to make transaction confirmation finality greedy and fast as possible. As shown by the ascending numeric labels in Figure 2 for the double-spend labeled with colored units, all units of the DAG have a stable, total ordering finality (of transaction confirmation) which is that of their lowest numbered, descendant stability point. The longest path rule is unambiguous within BFT once any path can be found from a prior stability point to observation units of a majority of the witnesses, because:
Because of #2 it’s not possible to find another such majority which does not also pass through those same observations; and there is no way to insert an observation into that said path as illustrated by observation ⑨ in Figure 3.
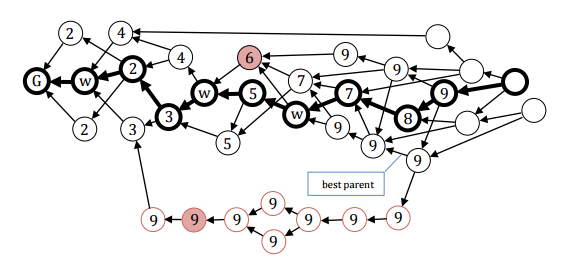
Figure 3: Majority of witness can censor a partial order (even if it’s not a double-spend).Witness units which do not transitively reference their prior unit in their ancestor path* are provably misbehaving and ignored thus can’t do any harm other than if the majority does. If the threshold of the count for the stability point is only the majority, a single witness could make finality ambiguous by signing two conflicting observations which (transitively) reference their same prior unit without one of the the observations (transitively) referencing the other. The faulty witness could publish one of the conflicting observation units after delay, possibly enabling the reversal of finality for some conflicting transactions. But this requires the minority of witnesses which didn't reference the first to then reference the delayed observation unit― which seems to require a majority (aka “50+%” or “
¹/₂+”) attack even if the delay was within ambiguity due to propagation delay because all (which is not random) of those minority have to join the attack. To increase the safety of finality, the said threshold could be increased to+²/₃of the witnesses so that reversing finality would require+¹/₃to sign conflicting observation units and in all likelihood+²/₃to be malevolent. Thus would reduce the liveness threshold from¹/₂+to+¹/₃. Note essentially this just means we increase the safety to attackers needs+²/₃at the cost of liveness reduction. Yet due to lack of a Schelling point that applies in Proof-of-Approval, there may be some nuanced reason for needing the additional safety margin. This needs further study.
Units aren’t yet final until they’re included in the antecedent lineage of a stability point. Thus, a tip of the DAG doesn’t become final until a majority of witnesses published an observation unit which (transitively) descends from the said tip and the prior stability point.
* Note contrary to the erroneous implication in the Byteball whitepaper, the said objectivity precludes any need or benefit for transactions to obey the same rule, which is further explained in the Liveness risk sub-section of the subsequent Byteball’s Flaws section.
Byteball’s Flaws
Yet Byteball suffers the following flaws as compared to the CRED design:
Centralized consensus: the set of witnesses for the quorum-required “Stability Point” Byzantine agreement consensus algorithm are effectively anointed (not permissionless). Election of delegates (which btw is also the case for DPoS) is always a political-economics power vacuum which is effectively controlled by the greatest power.
The set of witnesses in Byteball is either very difficult to change or it can proliferate into the chaos of too many witness sets. There’s no protocol mechanism to retire and replace the set of witness by stake vote, analogous to a DPoS election. Instead there’s a complex mechanism wherein (a complex interaction of transaction and witness observation) units compete to change the set of witnesses very slowly which seems to have very low odds of successfully making changes to the set because it lacks a Schelling point (c.f. also Vitalik explain what is a Schelling point). The danger is an entrenched set of witness could censor some or even stall all of the transaction confirmations, requiring a politically contentious hardfork to rectify. It is likely that the set of witnesses will become an entrenched monopoly because politics is a power vacuum that attracts the most cunning, ruthless, best liars. The §17. Choosing witnesses on pg. 20 of the whitepaper explains that Byteball will depend on some trusted community servers advising light clients on which witness to favor. Otherwise if the witness sets can proliferate as aforementioned, an irreconcilable partitioning chaos results also in all transaction confirmations being stuck (i.e. loss of finality).
Liveness risk: the anointed (not permissionless) set of witnesses for the quorum-required “Stability Point” Byzantine agreement consensus algorithm can censor some or all of the transactions (from the stability points they define which indicate a transaction is final and acceptable to the payee). If
50%(or33%if more secure as discussed in #2 above) of the (necessarily limited to only) 12 witnesses stop responding (making Byteball fragile w.r.t. to‡ DDoS and network isolation attacks), i.e. insufficient quorum, the stability points and thus the consensus for transaction confirmations become stuck, don’t move forward, and require a hardfork to become operational again. Tendermint and Ethereum’s Casper (and any other plausible 100% final BFT consensus system) also have this same flaw, because is an irremediable attribute of any BFT consensus system which has 100% probability of finality (within the liveness and safety tolerance thresholds). I had discussed these flaws with @tonych (real name Anton Churyumov) the creator of Byteball.The censorship of the aforementioned “some” case is not possible in Byteball if all transactions (or let’s say not probably plausible if a significant minority or a majority) back-reference each other although potential censorship of the “all” case remains regardless. But there’s no mechanism in Byteball to encourage that wide-scale back-referencing, so I presume the censorship of “some” (when attacker doesn’t want to censor “all”) is plausible.
Censorship of finality for some but not all transactions could be a more insidious attack because not the entire set of transacting participants would necessarily be motivated to not be apathetic about replacing the offending witnesses.
Additionally, competing witness subsets would create competing candidate stability point partial orders that are irreconcilably partitioned and can’t finalize on a stability point total order— i.e. the forward progress of consensus would be stuck until there’s a hardfork to replace the offending witnesses. Competing witness subsets would be thwarted if all transaction units (not just witness observation units) follow the rule of always back-referencing their prior unit in their ancestor path and the transactions synchronize on which of the competing candidate orders they back-reference. This theoretical protection is implausible in practice because it would require synchronizing (e.g. conflating) transacting with the total order analogous to Nakamoto proof-of-work, which paradigmatically incongruent with the aforementioned benefits of the “spontaneous” orthogonality of an asynchronous DAG. Hashgraph attains this synchronization by allowing only the permissioned “member” set to publish to the DAG.
Unscalable transaction fees: fees increase as the price of the token increases. There is no fee market so fees can automatically adjust. The constant fee design (denominated in byte tokens) makes it uneconomic to issue some transaction events when the exchange price (and thus market capitalization) is too high or inadequate spam resistance when the exchange price is too low.
Inadequate validation insecurity: analogous to the flaw of delegated PoS (DPoS), only the bounded set of (necessarily limited only 12!) witnesses do validation. The other unbounded transacting users necessarily being light clients for scaling aren’t doing validation, because they can’t be online always so they must trust “proofs” from witnesses.
Limited scaling: there are no shards. After the permissionless, fully asynchronous proof-of-publication to the ledger (a capability which Hashgraph removes) the transaction confirmation finality has to all be funneled through the permissioned set of 12 witnesses similar to DPoS.
Given that these limited number of permissioned witnesses are top-down required to run sufficiently powerful servers on the highest performance connections, it’s possible with dubious antifragility to attain very high TPS (and even low confirmation latency) as Facebook can also do with its centralized servers. Centralization is a solution for scaling, but not for antifragility and trustlessness. The degree of coordination and consistently high performance required from these witnesses is forsaking some antifragility.
But even that isn’t scaling, because all these witness servers have to receive and validate every transaction. Adding more witnesses won’t increase the TPS at all, and is more likely to reduce TPS throughput. There’s no plausible way to increase from the antifragile, dubious hundreds of thousands to many millions of TPS, without sharding. A hundred million social networking users will require many millions of TPS. IoT will require billions of TPS.
Adding antifragile, permissionless, trustless, decentralized sharding to any BFT consensus system will drastically reduce the scalability and increase the transaction confirmation latency. An antifragile implementation similar to OmniLedger achieves only thousands of TPS per shard at best on real world network assumptions. And the antifragile randomization of OmniLedger’s shard validators requires Byzcoin proof-of-work which limits the maximum number of shards because proof-of-work limits the number of validators (it’s not a one vote per computer concept). For example, it appears the combination of Byzcoin with OmniLedger is incompatible with pools at least in the sense that the pool can’t delegate the shards validation to individual miners in the pool. The proof-of-stake variant of OmniLedger is power-vacuum that must be filled by a cartel/oligarchy as is the case for the DPoS which powers EOS and
STEEM. The bottom line is that consensus systems can scale if we centralize them, but then what is the point of that? Just use Facebook. We already have multiple “competing” centralized systems, e.g. Facebook, Twitter, Google, etc.. Except they all bow down to the powers-that-be (e.g. the government and politics) because they’re centralized and thus not antifragile.Not real-time confirmation: transactions are confirmed by the validating witnesses who sign “stability points”, with reach round of the quorum completing in roughly “~30 seconds”. Sub-second transactions are implausible. Quoting what I wrote in part 1 of this blog about the witness set confirmations for the DPoS in EOS:
Whereas, the DPoS-variant in EOS also barely obtains 0.5 second latency which requires forsaking antifragility and decentralization (and note that distributed isn’t the same as decentralized).
‡ Byteball (and the CRED) aren’t vulnerable to the “forward secrecy” issue because of the TaPoS (TaPoW) which effectively locks the history against long-range chain reorganizations. I helped Dan Larimer invent TaPoS in 2013.
Compared to OmniLedger
OmniLedger has permissionless participation in validation (i.e. can’t get stuck) and scalable sharding. Yet it also lacks sub-second real-time confirmation same as for Byteball and Hashgraph. All of these consensus systems suffer winner-take-all centralization. See the other comments in the Limited scaling section above.
Hashgraph Swirlds
The §1 Introduction on pg. 2 of the Hashgraph Swirlds whitepaper mentions the same fully asynchronous model as I explained is the case for Byteball in the Byteball’s “Stability Point” Total Order section. Because of the FLP impossibility theorem, both Hashgraph and Byteball require that the communication over the network eventually succeeds although there’s no specific bound as would be the case in partially asynchronous consensus systems such as the block period in Nakamoto proof-of-work and the expiration of an epoch for quorum voting in Byzantine agreement.
Hashgraph’s “famous witnesses” are analogous to Byteball’s stability points except they’re generated algorithmically instead of by prerogative of the witnessing “members”.
The major difference is that the Hashgraph “members” are a permissioned set (as are Byteball witnesses) and only they may publish transactions to the DAG and set the back-references of the DAG. So transactions created by non-members must be sent to a member for publishing to the DAG.
Unlike Byteball witnesses, Hashgraph members have no leeway to designate the “famous witnesses” DAG vertices they observe (unless +²/₃ of the members are colluding for attack, i.e. exceeding the BFT safety threshold). Thus the Hashgraph design eliminates the possibility for competing subsets (of members) vulnerability that is described in the Liveness risk sub-section of the Byteball’s Flaws section.
Hashgraph’s Flaws
The tradeoff is that it’s not possible to objectively prove that transactions have been censored from publishing to the DAG if +²/₃ of the members are colluding. The P2P network has no bearing on the fact that a transaction is not objectively published until the transaction is confirmed by a descendant “famous witness” point, because non-member transaction signers can’t set back-references in the DAG. So this makes it impossible to objectively prove which members are colluding or that they’re colluding. Community evidence can be employed but can become a “he said, she said” dilemma. Propagation order and responsiveness can’t be proven nor disproven (c.f. also and also) in an asynchronous network.
Other than the differences above, Hashgraph has all the same Centralized consensus, Liveness risk, Limited scaling, and Not real-time confirmation flaws that are listed in the Byteball’s Flaws section. Replace “witness” with “member” and “famous witness” with “stability point”.
The Hashgraph whitepaper is misleading because it seems to imply by omission of details (and mentioning members that are live and not live) that members can come and go from the member set. This is not possible in 100% final BFT consensus. There must be some permissioned mechanism for selecting and changing the member set, such as authorized by a prior consensus round or a proof-of-stake election. Also the members can only be those with high performance servers with very fast connections, otherwise the TPS will suffer. I independently arrived at this conclusion before discovering the following confirmation.
Wikipedia says:
Emin Gün Sirer notes that “The correctness of the entire HashGraph protocol seems to hinge on every participant knowing and agreeing upon N, the total number of participants in the system,” which is "a difficult number to determine in an open distributed system.” Baird responded that “All of the nodes at a given time know how many nodes there are.”
Baird is incorrect and frankly he’s being deceptive because surely he knows that can’t be objectively known in a 100% final BFT consensus system if the nodes are free to come and go without some permissioned consensus on changes to the member set. Or maybe he’s just deceptively agreeing that the member set is known because it is permissioned.
SPECTRE

SPECTRE* is a block DAG:
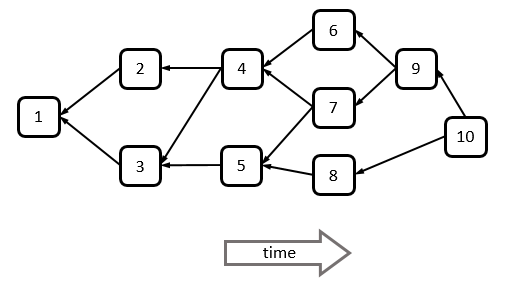
A Block DAG. Each block may refer to several predecessor blocks by including their hash in its header.
There’s also a blog intro and the 2016 version of the paper.
SPECTRE is notable because of its rigorous mathematical analysis of an unbounded plurality of pairwise partial orders to provide some of the properties of probabilistic consistency, safety, progress, and liveness that we normally expect from the single total ordering of Satoshi’s PoW longest-chain rule.
Yet afaics, it suffers the following flaws as compared to the CRED design:
No total ordering: the system is unable to totally order conflicting transactions; thus for example can’t be used for smart contracts (such as those of Ethereum) which mutate a global state.
Weak Liveness: if a payee issues a conflicting transaction such as to increase the transaction fee (unless accept traceability) or to employ the system as a synchronization oracle, the transaction can become indefinitely frozen (even for perpetuity) in unconfirmed state, because the system is unable to totally order conflicting transactions.
Throughput contention: throughput can’t scale proportionally to the increased volume of blocks produced unless there is a significant backlog of transactions (which is a result of the requirement that throughput be constrained (alternative link)), because otherwise (the necessarily uncoordinated) blocks have a higher probability of including duplicate copies of the same transactions.
Not real-time confirmation: approximately 5 seconds confirmation if no backlog, but backlog is required for avoiding throughput contention. Much faster than Bitcoin, but far too slow for recording every user action in applications on a blockchain a la Steemit.
Scaling centralization: throughput constraint (e.g. 1 MB per 10 minutes) is hardcoded in the protocol in order to both avoid throughput contention and to contain the synchrony assumptions “
𝐷” (via “𝐵kb”) of the probabilistic confirmation. To increase the throughput requires a centralized hardfork.O(n²) doesn’t scale decentralized: presuming miners have an incentive to maximize the breadth of their leaves of the DAG they reference, then every honest node has to receive and validate every transaction. Thus lower hashrate miners have to expend the same bandwidth and validation costs as higher hashrate miners that win more blocks, which thus drives hashrate share centralization to the larger hashrate miners over time, unless an acceptable lower bound on transaction fees coupled with the upper bound on number of miners renders the costs insignificant. The total bandwidth requirements of the system scale ϴ(n²) thus limiting the number of miners.
Perpetual inflation required: ditto Dysfunctional if Significant Transaction Revenue flaw applies.
Lacks game-theoretic analysis: for example, I have some doubt whether the DAG converges given that miners are paid for blocks even if they don’t maximize the number of leaves referenced. If transactions fees become significant, then Dysfunctional if Significant Transaction Revenue flaw applies. One might presume that miners have an incentive to maximize referenced leaves in order to maximize the value of the tokens they mine, but that is presuming there aren’t other countervailing incentives around for example minimizing validation and bandwidth costs.
Obscure doubt about fungibility: this is the most debatable of my criticisms yet I want to keep it on record. I think it’s a valid concern and a vulnerability that must be weighed. It’s not just a concern about fungibility but also about whether the incentive to not double-spend is weakened. More explanation of the concept.
SPECTRE is a very complex system and I don’t know of anyone other than the authors who has completely digested all of its proofs, algorithms, and even game theory that doesn’t appear to be analyzed in its paper. I digested a sufficient amount of the paper to understand that the (inherently irreparable in such a non-total ordering design) deficiencies enumerated above make it uninteresting for me to analyze further.
* Spectrecoin is not based on the SPECTRE consensus algorithm.
IOTA and DagCoin

IOTA and its research proposal predecessor DagCoin don’t record any form of objective transaction finality (such as Byteball’s stability points) for the unsynchronized partial orders of transactions in the ledger!
As I first conceptualized in 2016, transactions include some PoW so that tips (leaves) of the DAG branches are extended with probabilistically more cumulative PoW as new descendant transactions are issued, but there is nothing forcing these unsynchronized partial orders to converge on a single-total ordering, i.e. there is no probabilistic finality of transaction confirmation. In fact, (in the absence of IOTA’s “Coordinator” centralized servers) the partial orders will have conflicting orders due to double-spends, and there is no leadership election process nor witnesses set to decide on the ordering of the conflicts. Although the transaction nodes of the graph are accepted by payees which have an incentive to insure their funds are in a single total ordering of the DAG, it is impossible for them to coordinate such autonomously. Therefore, defection from the Monte Carlo model presumption by some transactions breaks the convergence to a total ordering. That is a prisoner’s dilemma which (except in “pure strategies”) is the antithesis of a non-degenerate Nash Equilibrium.
The (load of misleading technobabble bullshit) theory of their convergence to a single total ordering—which was based on either network propagation order (which experts know can never be provably consistent for all nodes without some synchronization algorithm) and/or a model requiring enforcement of the Monte Carlo algorithms employed by the payer and payee—are inherently insecure without the centralized Coordinator due to natural unconstrained divergence. IOTA employs centralized servers named “Coordinator” (apparently not mentioned at least in the early revisions in the whitepaper) to enforce the whitepaper’s Monte Carlo strategy on all participants. IOTA has been challenged numerous times by numerous people (including myself challenging @Come-from-Beyond the developer) to remove their Coordinator centralized enforcement in order to prove that IOTA will function decentralized, and afaik they have never done so. The was further elaborated here and here.
I was threatened with a lawsuit by the “IOTA Founder” @iotatoken (real name is David Sønstebø) if I attempt to publish these truths.  Note since I originally wrote this in August 2017, I have seen a post on
Note since I originally wrote this in August 2017, I have seen a post on bitcointalk.org with a disclaimer from @iotatoken admitting the centralization of Iota’s Coordinator and no certainty it can ever be removed.
Update Dec 15 2019: As explained above the Tangle didn’t just require an honest majority and steady stream of their transactions. The recent proposal to remove the Coordinator admits I was correct since 2015 that Iota was intentionally centralized from its inception. The proposal essentially hopes to replace the Coordinator with proof-of-stake (PoS), lol. The natural Tangle divergence (away from consensus) I blogged about above, will be ameliorated by PoS voting. And sheepeople bought into this FOMO crap. Pitiful.
In addition to the other egregious flaws of PoS, the following Iota claim is another deception, “Since our Coordicide solution does not rely on a longest chain wins rule, our Sybil protection mechanism is not affected by these problems.”
Blockchain-Free Cryptocurrencies
Boyen’s Blockchain-Free Cryptocurrencies incorporates a monetary incentive which is posited to not be resistant to selfish and stubborn mining via orphaning of branches and also appears to have corner case issues around variable proof-of-work difficulty and network topology for scaling.
Radix
Click Here to continue reading Part 3 this blog.
The linked webpages and whitepapers cited in this blog have been archived at archive.is and/or archive.org.
MaidSafe’s blog about their new PARSEC consensus system, agrees with my assessment of Hashgraph:
They also claim that in addition to
⅓liveness threshold, that a sufficiently sophisticated adversary with less than that threshold could stall the progression of finality:However this alleged sophisticated attack that reduces liveness could be rectified in theory with a “common coin” algorithm that introduces randomness into the consensus process so that the sophisticated attacker is foiled. But such “common coin” algorithms are a trusted multiparty cryptographic scheme of which the key setup (analogous in some respects to Zerocash’s key setup ceremony) is impractical for a system where nodes are churning in and out of the validators set rapidly. Thus the claim that Hashgraph can’t handle such churn and it’s node set being less changeable if it employed such a “common coin” algorithm.
The quote above could be considered incorrect by associating churn with permissionless. A consensus round is required (for both PARSEC and Hashgraph) to add or remove validators from the set for validators. Thus for both systems exceeding the liveness threshold of the elder set of validators can lead to a stuck chain that doesn’t confirm any more transactions. However I think the point the above quote is making is that without churn then since Hashgraph has a less adaptable validator set, then it is more prone to problems of an entrenched validator set. Well I would mostly disagree with that assessment been always (i.e. generally) true because as whether the liveness threshold is exceeded depends on other factors too, not just whether the validator is not changing (much). IOW I think MaidSafe’s PARSEC is also permissioned in some sense. The devil is in the details of the holistic game theory of the system in which the consensus algorithm is deployed.
You have a minor misspelling in the following sentence:
It should be therefore instead of therefor.Great work doing this post!
An earlier comment (and another) I made about Iota which I had forgotten to incorporate into this blog.