Apprendre le hacking #2 // Un monde invisible

Sommaire
- Présentation
- Compilation et hexadécimal
- Le déboguage
Présentation
Bonjour à tous et à toutes mes futurs hackers ! La semaine dernière, nous avons vu et appris à créer des variables, des boucles et des fonctions puis à utiliser les opérateurs arithmétique et de comparaison. Aujourd'hui nous allons commencer la partie un peu plus ardue. En effet, un programmeur, dans sa vie de tous les jours, va chercher à créer un code fonctionnel. C'est déjà un énorme boulot. Pour les hackers, l'endroit intéressant est lorsque le programme s'éxecute.
Allons ensemble dans un monde invisible pour la plupart des personnes. Un monde qui vous ferra rêver d'exploration !
De quoi vous allez avoir besoin ?
Si vous êtes des petits nouveaux, commencez donc par lire le premier article. Ce dernier va vous apprendre à installer une machine virtuelle afin d'avoir Linux. Vous devrez ensuite lire mon second article pour installer un éditeur de texte et créer votre premier programme puis prendre quelques bases au passage.
Pour les autres, vous aurez besoin de rien de plus que d'allumer votre machine virtuelle et ouvrir grand les yeux !
...
Pardon, vous aurez aussi besoin de vous placer dans le répértoire créé dans l'article précédent.
Nous voilà prêt à entrer dans une toute nouvelle dimension !
Compilation et hexadécimal
Comme j'ai pu le dire dans la présentation, le code source n'est qu'une petite partie de ce que nous pouvons faire d'un programme. Quand nous compilons notre code, ce dernier est transformé en un fichier binaire exécutable. Le fameux a.out. Dans ce fichier, ce sont des instructions que seul votre processeur peut comprendre. C'est donc aux travers de ce petit fichier que tout va se passer. En effet, le programmeur ne va pas chercher plus loin, tant que son programma fonctionnne, il va, dans la plupart du temps, s'arrêter là.
A nous de comprendre ce qu'il se cache derrière ce fichier. Avec une bonnne compréhension du processeur, vous pouvez être capable de manipuler un programme. Grâce à Linux, nous allons pouvoir voir à quoi ressemble ce nouveau monde.
Vous vous souvenez de ce petit programme ?

Il incrémentait de 100 le nombre de mes abonnés tant que ce dernier était inférieur à 1000. Je vous propose de regarder de quoi est fait le fichier a.out de ce code lorsque le programme est compilé. On va pour cela se servir du programme objdump que nous donne linux. Grâce à la commande suivante objdump -M intel -D a.out | grep A20 main.:, nous allons pouvoir lire le code machine des 20 premières lignes de notre fonction main().

Nous voyons sur la photo ci-dessus, 3 colonnes. Ces dernières vont nous aider à examiner notre code. Pour la première colonne (tout à gauche), nous voyons des notations en hexadécimal. C'est donc à partir de là que nous devons clarifier un truc !
C'est quoi de l'hexadécimal ?
Nous, humains, pour compter nous utilisons 10 chiffres, (de 0 à 9). Nous sommes donc en base 10 et nous ajoutons plus 1 à chaque fois. Nos ordinateurs eux comptent en base 2, seulement avec des 0 et des 1. Comme nous le voyons dans nos colonnes de la dernière photo, nous avons que des octets. Un seul octet prend 8 bits. Chaque bits peuvent donc prendre comme valeur, 1 ou 0. Donc, 1 octet peut prendre 2^8 valeurs soit 256 valeurs. Chaques octets va être écrit à l'aide de deux chiffres hexadécimaux.
Revenons à notre notation hexadécimal, pour écrire en hexadécimal nous utilisons les valeurs 0 à 9 pour représenter les valeurs 0 à 9 et nous utilisons les valeurs A à F pour représenter les valeurs 10 à 15. Ainsi, au lieu de donner la notation suivante : 11001001 pour l'instruction leave, nous utilisons sont hexadécimal : c9, qui est bien plus simple à retenir et à lire.
Le côté hexadécimal peut être un peu sombre aux premiers abords mais reste très largement compréhensible. Surtout avec le temps.
Revenons à présent à nos moutons. La colonne de droite donc est de l'hexadécimal et représente des adresses mémoires. Lors de la compilation, nos instructions en code machine doivent être stockées dans des cases mémoires. Chaque octets y est stockés et avec une adresse différente. Un peu comme dans une rue, chaque maison contient des personnes et possèdent une adresse unique. Comme quoi, quand je vous dis que la programmation est similaire au fonctionnement humain !
La colonne du milieu, toujours en notation hexadécimal, représente les instructions en langage machine de votre processeur. Normalement en binaire, comme expliqué plus haut, il est plus facile de lire de l'hexa que du binaire !
Enfin, la colonne de droite représente les instructions en langage assembleur. Nous ne verrons pas, ou très peu, dans ce cours, comment fonctionne et comment écrire en langage assembleur. Je vous invite à vous renseigner de vous même. Cependant, vous verrez que lire du langage assembleur n'est pas impossible. En effet, ce langage est constitué d'opérations et parfois d'arguments pour connaître la destination et la source d'une opération. C'est donc le seul travail d'un processeur.
Tout comment en programmation ou en script, le processeur possède lui aussi sont lot de variables spéciales. Ce sont des registres. Ces derniers sont important si l'on veut comprendre comment fonctionnne les instructions.
Le déboguage
Les registres sont donc des sortes de variables internes propres au processeur. Pour les observer, nuos allons déboguer notre programme.
Ca veut dire quoi, déboguer ?
C'est tout simplement le fait d'exécuter un programme pas à pas, d'examiner la mémoire et aussi et surtout, afficher les registres du processeur. Une fois notre programme compilé, nous pouvons exécuter le commande suivante :

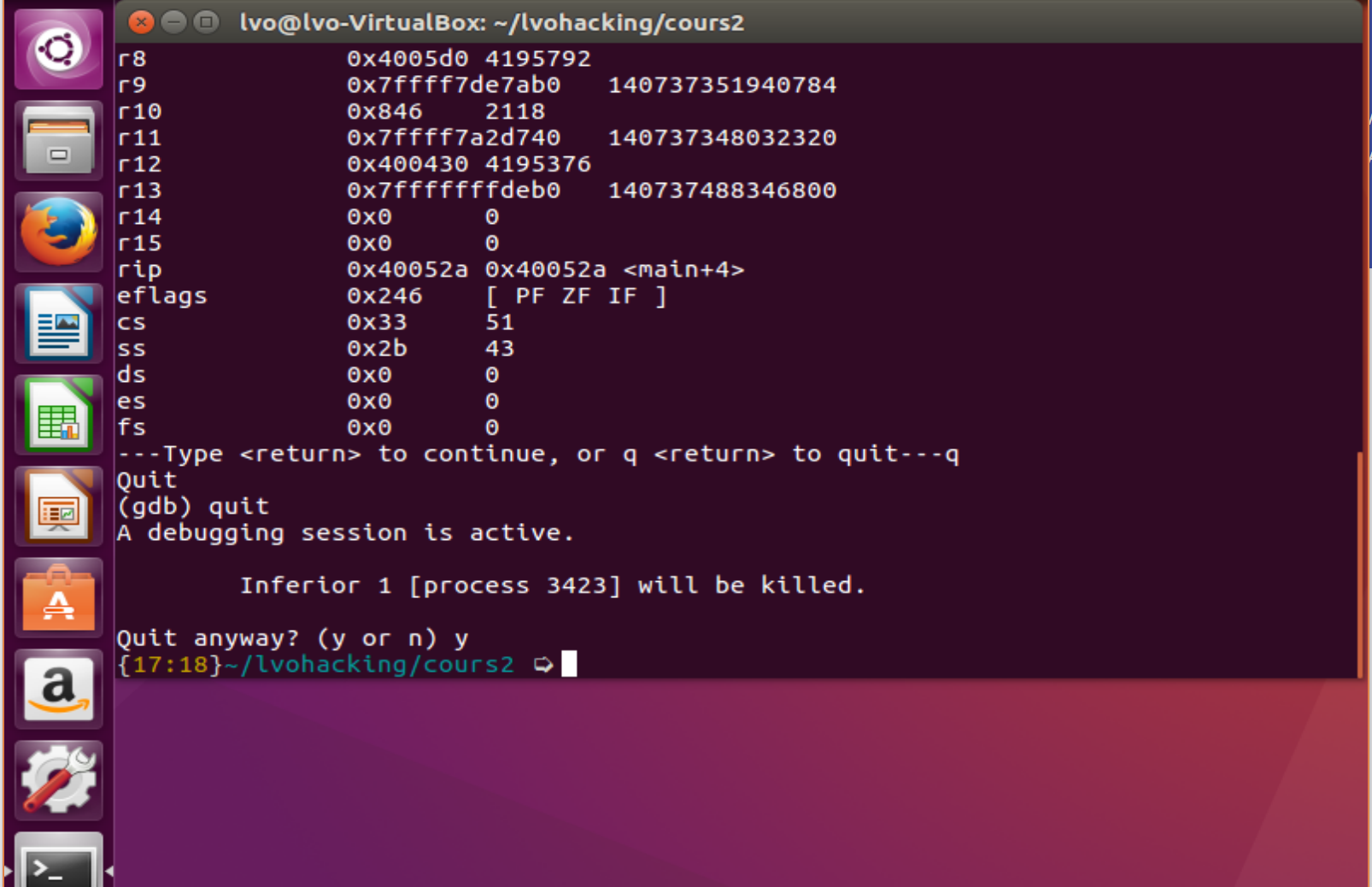
Ce que nous avons fais est très simple ! Nous avons lancé gdb puis avons placés un point d'arrêt sur main(), ainsi, nous allons exécuter le programme jusqu'à la fonction main(). Il va s'arrêter avant ! On demande ensuite à gdb de nous afficher les registres.
Petits points important sur nos registres
Nous parlons registres depuis tout à l'heure mais il va falloir commencer à pouvoir les distinguer. Les premiers registres qui arrivent lorsque l'on lance gdb sont des registres généraux. Je parle ici de RAX, RBX, RCX et RDX (Accumulateur, Base, Compteur, Données). Ce sont des variables temporaires pour notre processeur.
Ensuite vient RSP, RBP, RSI, RDI (Pointeur de Pile, Pointeur de Base, Indexe de Source, Indexe de Base). Ceux-ci se séparent en deux, les deux premiers sont des pointeurs (clin d'oeil à ceux qui connaissent la programmation), ils servent à stocker des adresses. Les deux derniers peuvent aussi êtres vus comme des pointeurs. Ils désignent une source et une destination lorsque les données doivent êtres lues ou écrites.
Vient ensuite RIP qui est le Pointeur d'instruction. Il dit l'instruction en cours de lecture par le processeur. Nous allons souvent en avoir besoin.
Et enfin le registre EFLAGS. Celui-ci est utilisé pour les comparaisons et les segments de mémoire. C'est à dire que la mémoire réelle est décomposée en plusieurs petits segments.
Hey ! J'éspère que cette série te plaîs ! N'hésite pas à me le dire en commentaire et aussi à me donner des conseils de rédaction, j'aime partager et apprendre des autres !


Merci pour l'article !
Et merci à toi !