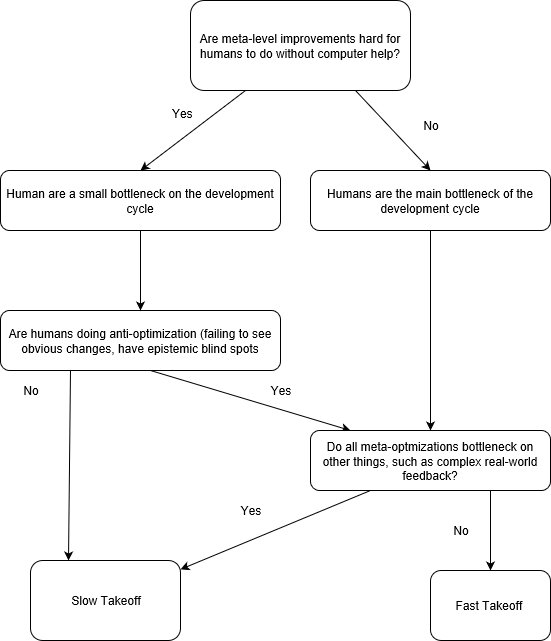
Double Cruxing the AI Foom debate
This post is generally in response to both Paul Christiano’s post and the original foom debate. I am trying to find the exact circumstances and conditions which would point to fast or slow AI takeoff.
Epistemic Status: I have changed my mind a few times about this. Currently thinking that both fast and slow takeoff scenarios are plausible, however I put more probability mass on slow takeoff under normal circumstances.
Just to be clear about the terminology. When we say "fast take-off", we talk about an AGI that achieves a decisive unstoppable advantage from a “seed AI” to a “world optimizing AGI” in less than a week. That is, it can gather enough resources to improve itself to the point where its values come to dominate human ones for the rest of the future. That does not necessarily mean that the world would end in the week if everything went badly, rather that the process of human decline would become irreversible at that point.
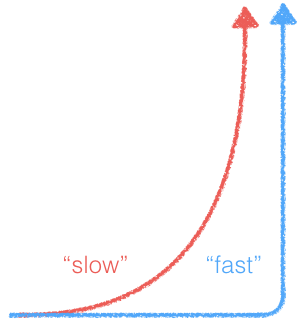
When we talk about slow takeoff, we are talking about a situation where the pace of economic doubling is being gradually reduced to less than the current rate of 15 years, potentially to 1-2 years. Note, this “slow” is still a fundamental transition of the human society on the order of the agricultural or industrial revolution. Most people in the broader world think of significantly slower transitions that what the AI community considers “slow”. “Middle takeoff” is something in between the two scenarios.
There are several analogies that people use to favor slow take-off, such as:
a) Economic Model of gradually replacing humans out of the self-improvement loop
b) Corporate model of improvement or lack there of
c) Previous shifts in human society
There are several analogies that people use to favor fast take-off, such as:
a) Development of nuclear weapons
b) The actual model of how nuclear weapons work
c) Development of human brains compared to evolution
There are also several complicating factors, such as:
a) The exact geo-political situation, such the number, sophistication and adversarial nature of the players.
b) The number of separate insights required to produce general intelligence
c) Whether progress occurs in hardware or software or both
d) Improvement in human-computer interfaces compared to improvement in stand-alone algorithms.
The exact scenario we are considering is the following. Sometime in the lab, we get an insight that finally enables AIs to have an economical way to remove humans out of the loop of optimizing AIs. So, while before a human was needed to train AIs, now we no longer need the human and the optimization can occur by itself recursively.
The fast takeoff scenario in this hypothetical says: humans are out, progress can speed up at the pace of that was previously bottlenecks by human limitations.
The slow takeoff scenario in this hypothetical says: humans are out, but by this time they were a small portion of AI-improvement pipeline anyways, so we just sped up a 10% portion of a process.
So, the first crux is: what portion of an AI-improvement process did humans take up before the transition to recursive self-improvement (RSI)?
I can come up with two detailed scenarios where the answer goes one way or another.
1st – Humans are a small portion of work. In this case, let’s say we only have two real AI researchers. They are careful about their time and work on automating all work as they can. The research proceeds with kicking off very complex programs and leaving them alone, where the researchers check in only in-frequently on them. This keeps producing more and more economically powerful AIs until one of them can take over the researcher’s work kicking off the complex programs. However, the actual improvement in improving the running those programs is still hard even for the researchers or the AIs themselves. In this scenario, the takeoff is slow.
2nd – There are many people who are all working on RSI capability and that’s the only thing they are working on. Simple models of RSI work on below human intelligence AI. The humans all have a lot of jobs that involve coming up with and evaluating arguments and experiments, which are fast to run. At some point, there is a breakthrough in brain-scanning technology that can to transmit all the researcher’s brains into software at cost. Everyone gets uploaded, runs 100 times faster and is able to both apply RSI to themselves and improve AI research at a faster pace.
Neither scenario seems prohibited by physics or economics. The fast take-off scenario usually needs a few more pieces to be plausible, such as one of ability of the AI to rapidly acquire more hardware OR speed up hardware research and deployment OR have its existing algorithms very far from optimality.
This brings me to the general worldview that both “fast” and “slow” takeoffs are plausible models of AI development in the future.
I am going to consider a few hypotheticals and examine them considering this model of the first crux.
a) Evolution of humans and civilization
In Surprised By Brains Eliezer says that humans are an example of foom with respect to evolution, while the creation of the first replicator is an example of foom with respect to the non-optimization of stars.
I partially disagree. From the perspective of humans, nice civilizations and concrete buildings are what we care about and we develop those a lot faster than evolution develops ecosystems. So, from our perspective, we are good at fooming.
However, it’s important to keep in mind that human society does not yet do things that evolution considers an example of a “fast foom.” To the extent that evolution cares about anything, it’s number of individuals around. Perhaps it’s "interested" in other metrics, such as ability to change the genes over time.
From the perspective of evolution, humans are exhibiting a slow takeoff right now. They are exponentially rising in population and they exist in many climates, but this is still a continuous process implemented on genes and individuals, which are working in evolutionary scales.
Humans could begin to do things that look “discontinuous” from evolution’s perspective. Those thinks are gene-editing on a large scale (discontinuous changes in gene frequency), rapid cloning (discontinuous changes in number of people) and rapid movement across the galaxy (probably still continuous, but a large ability to overcome carrying capacity).
However, this may or may not happen in the future. The point is that, instead of providing an example of fast takeoff, because humans can design wheels faster than evolution, this points to slow takeoff where humans are subject to evolutionary tools to a potential, but not yet certain, fast takeoff where humans can direct evolutionary forces in a more discontinuous manner. Once again, this gene editing might be a bad idea. This minor fast foom, already happens with artificial selection of plants and certain animals, such as dogs. So, humans can make things happen to other entities that rapidly change the structure of optimization, but not to themselves, in part because there is lack of certainty about whether this is a good idea or not.
If we analogize this to AI, the strongest AI might have a very easy time replacing humans in the loop of optimizing weaker AIs, but that’s not the same as replacing humans in the loop of self-optimization.
b) Another important evolutionary intuition pump is the difference between chimps and humans. The main argument is simple: human brain is not much larger than chimp’s, it’s algorithms are probably more sophisticated, but they might not have that many underlying algorithmic tricks. If we have an AI that is equivalent to the power of 1million chimps, we could one day discover a couple general purpose tricks, which create an AI that is equivalent to the power of 1million pre-historic humans.
1million pre-historic humans could in theory organize themselves to better perform a set of cognitive tasks, including their own training.
I think this is one of the best pro-fast foom intuitions.
Let’s break this down a bit.
The first part talks about the ability of small algorithmic changes to have larger profound effects down the line. Imagine a company which operates large neural networks without back-propagation and trains them too slowly discovering back-prop. Large conceptual breakthroughs are extremely profitable, but that does not mean that they can occur quickly. If there are a lot of “ai-supporting” technologies, such as extra hardware without conceptual breakthroughs, that can create a situation conducive to fast takeoff. In other words, the thesis here is that instead of a long process of “refinement cycles” for AI, there is a single simple set of code changes, which, when run the hardware at the time creates a stronger self-improvement cycle.
It could be the following graph:
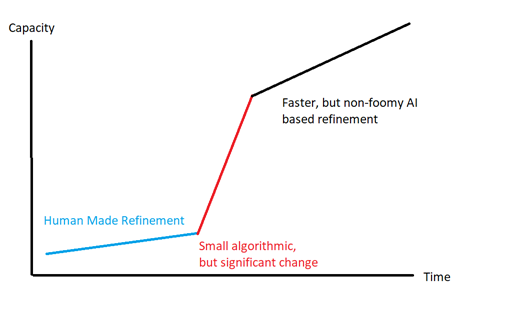
First slow takeoff, then a single change that breaches a barrier, then refinement cycle that is faster than the previous slow takeoff, but slower than “fast foom.” Think AlphaGo here. First, we have a semi-continuous improvement in go play [slow changes at first], a couple general algorithmic changes that move the needle a lot forward, which then create a strong ability to learn from self-play [analogous to RSI]. However, once that ability has been established, the improvement once again proceed more gradually.
Small changes to algorithms can have a large profound effect, however the crux here has to do with the search algorithm that is used to produce those changes. Just because an algorithmic change is “small” in terms of bits does not necessarily mean that it “easy” to find. If the human researchers have a difficult time finding these changes and only come up with one 50% improvement breakthrough every few months or so, and the newly designed artificial researchers can come up with one breakthrough 50% faster, then we are still going to have a slowish foom, even though completely human-less recursive self-improvement is happening.
So, while small changes being able to produce large returns is somewhat of an argument for fast foom, however it does not change the first crux - how much of the development cycle are you able to automate away.
The second part of the chimp human intuition is the question about the ability of the “pile of human-powered” algorithms to accomplish a set of tasks that are done by humans well enough to replace them. This easily happens in some domains.
a) Calculators can do many more calculations than humans trivially, once chess engines beat humans, they never looked back. Etc, etc.
b) An algorithm running 1 million cavemen minds may or may not be able to take over the world.
c) A set of algorithms simulating an individual human connected in non-productive ways might not be accomplishing the relevant tasks well.
The question here is how long does it for researchers to develop algorithms to traverse the range of human skill and approach organizational skill in any task? In other words, given a simple human-level scientist algorithm, how long does it take to turn it into a world-class researcher? This, of course depends on the range of human abilities in this area. In other words, the amount of time it takes an average human-level algorithm to become a world class persuader or researcher might be longer than it takes a “human level algorithm” in chess to become a world class chess player. So, while the difference within humans is still a lot smaller than between humans and chimps, it’s possible that there would need to be a key set of breakthroughs in either understanding “organization” of intelligence or human differences that occurs between “human-level” and “able to replace humans.”
So, to review the first crux – how much of the human intervention exists in the loop in improving AIs.
This somewhat has two different images of the development cycle. Image A is the cycle of humans having ideas that are mostly wrong and testing them using a lot of hardware. Image B is the cycle of humans having ideas that are mostly right but are slow to generate and generally require arm-chair debates and thinking without a significant intervention of computers.
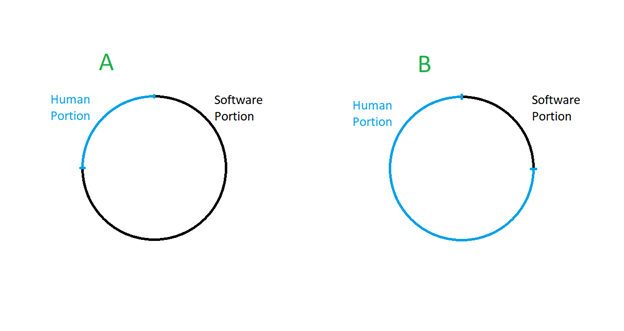
If you replace humans in Image A, you have a slow takeoff. If you replace humans in Image B, you could have a fast takeoff - with a couple caveats. If humans are a small part of the overall process in, BUT they are disproportionately slowing it down, then it could be the case that replacing them could remove a significantly larger portion of the overall process. This could happen for several reasons, such as financial incentives of the people involved do not create the necessary conditions for rapid progress or insights exist in epistemic blind spots.
However, if we ignore this caveat, we can wonder about the process of AI research and development in each image. To me the first crux reduces to how much can people “think of” AI without using evidence of outcomes of complex computations.
Basically, in Image A, where a group of researchers draw from a large sample of potential improvements to the code of AI, or the training process or a development process, they must do a lot of computational work to verify whether the idea is good or not. It’s possible that the more meta the idea, the more work they need to do. If there is a powerful narrow AI that is already deployed and functioning on the real-world, you might need to run real-world tests, which could take weeks if not more. I encounter this situation in my current work and it’s not clear that this will get any easier.
In Image B, a group of researchers can use their reasoning capacity to make improvements which are easy to verify. The ease of verification depends on availability of test environments. Alpha-Go is an interesting case study. If a general-purpose intelligence breakthrough happens to improve an existing go-playing algorithm over the standard baseline, then it’s easy to verify. If we go up a meta-level up and there is an intelligence breakthrough that enables a general-purpose intelligence to better train narrow intelligences and they are measured by playing go, that also easy-ish to verify. Even that could take weeks of datacenter time today, but that is likely to be reduced in the future.
This brings me to the second crux – how easy is it to verify improvements, especially “meta” improvements for the people involved in AGI development. Verification has many types, such as ability to test ideas in simple environments and ability to quickly reject ideas based on other forms of supporting evidence, simply due to the strength of the researcher’s rationality. This has been pointed out by Robin Hanson as a problem for the AI itself for fast foom proponents in this piece.
“Merely having the full ability to change its own meta-level need not give such systems anything like the wisdom to usefully make such changes.”
However, keep in mind, we are considering this in the view of whether human researchers have the ability to make these meta-level changes.
I highly doubt that AGI insights can be easily tested in small standard environments. And from the history of AI, to my current work, to the discourse around AI in popular culture, it seems to me that rationally navigating the space of AI improvements is extremely hard for nearly everyone. It is theoretically possible that we, as a society, could get better in training researchers to better navigate the search space of improvement ideas, but I do not assign a very high probability on this.
The second crux could be examined considering another analogy, brought by Robin Hanson in the original foom debate here
Why don’t companies manufacturing productivity tools “go foom”? If they can work on making better tools, they get better at making tools and they can go on improving this process for a long time.
The company analogy is not perfect for several reasons that have been pointed out already. Companies have a tough time aligning all the sub-processes to work together, they have a tough time keeping insights out of the hands of competitors, and as employees get richer, it becomes harder to keep them. However, there is a key piece of the analogy that does bear repeating – companies (and individuals) do not necessarily have the wisdom to know whether a particular meta-optimization is a good idea or not.
Do agile development, open office plans and hiring consultants improve or hinder things? It’s hard to run A/B tests on these development and different people will give different opinions on the effectiveness of these interventions, partly due diverging incentives.
While one can think that algorithms don’t necessarily suffer from political problems (yet!), there are several issues that arise the moment one steps a meta-level above the current ML paradigm. I can think of several key problems:
a. Defining better metrics or sub goals is a hard process to systematically measure
b. Space of actual improvements is potentially rather small compared to space of possible changes
c. Sequential improvements could be anti-inductive in nature. Because a set of tricks worked in the past, may, in fact, be counter-evidence to them working in the future. This can trip up both people and algorithms. This is the fundamental problem of simply counting “returns” on cognitive re-investment.
d. Real world feedback could be a hard-to eliminate bottleneck
Summary of all the above reasons leads me to believe that it’s possible that negative spirals can dominate the improvement landscape. The model is simple - if we have 1% of plausible changes are improvements, and the measuring system can recognize them all, but also labels 3% of the rest as false positive improvements, then on average the system will get worse over time. (I am assuming all changes are the same magnitude). “Development hell” is the company analogy of this, as additional features move the product farther away from shipping.
Note, that these problems apply to both human and artificial researchers alike. The way this relates to the fast / slow takeoff debate is still whether the way that the human researchers solve this. If they solve this through using a large amount of computation and real-world testing, then their reasoning and idea generation is not the bottleneck of the process and takeoff will be slow, if they solve this through using more and more advanced math to produce better and better abstractions, then their reasoning is the bottleneck and takeoff could be fast. Of course, if the problems are sufficiently advanced we may end up in a situation where even the fast takeoff requires a large amount of computation or we might not have a takeoff at all. The last possibility can arise if misaligned narrow AIs cause severe problems in the civilization to prevent further development. The simple example is that an AI can design the world’s most addicting video game, which then everybody plays, and the real-world economy collapses. This, by itself, is a form of civilizational, though not existential risk.
The last analogy that is worth pondering is the example of difference between nuclear weapon development and nuclear weapon explosion.
An important interplay in the nuclear weapon example is a simultaneous combination between self-enhancing takeoff / explosion and self-limiting / anti-inductive takeoff explosion. As the nuclear weapon explodes, it initially creates more and more relevant particles causing more and more explosions. This is the self-enhancing piece. It also consumes more and more of the material present in the bomb. This is the self-limiting piece. So, while the nuclear weapon explodes a lot faster than the speed of nuclear weapon development, it is not exempt from eventually being over-ruled by a lack of key non-renewable resource. Of course, when applied to an AI, this idea of a “fast foom” followed by a “slow foom” might still be incredibly dangerous.
Summary:
My current opinion on the second crux is that in practice, meta improvements are hard to do for people without an assistance of a large amount of computing resources. This points to a slow takeoff, however this situation could change in the future, so I don’t want to completely rule out fast takeoff as a possibility.
Graphical Summary: