AI Introduction Part 2 - Images && Convolutional Neural Network
Hi guys!!
In this post we will discuss how to train a Neural Network on images.
Theoretically an MLP can learn to solve image related tasks, but the architecture is not properly equipped to take advantage of spacial locality of pixels within the image.
Convolution Neural Networks (CNN)
- CNN's are inspired by biological (visual cortex) processing consisting of several layers.
- CNN's are used in applications in image and video recognition, recommender system, and natural language processing.
- Pioneered by Yann LecCun director of AI research at facebook.
- Success - beat human at image recognition, Imagenet top winners are CNN
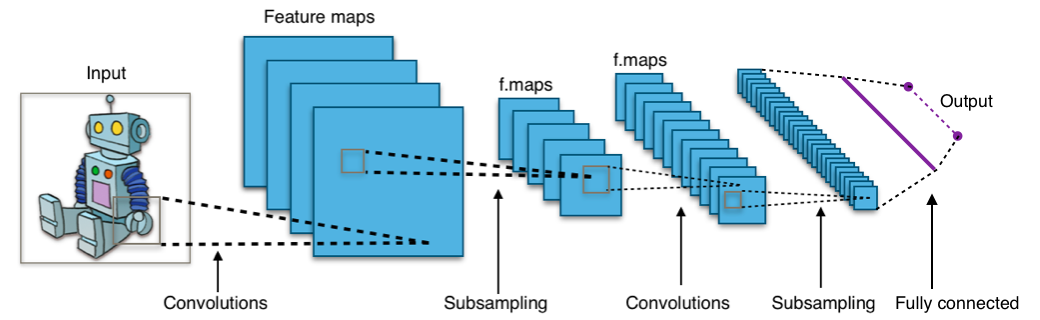
The core of CNN is a layer which performs the convolution mathematical opertaion. Parameters within the network are a set of learnable filters/weights/kernels, which have a small field, but are applied on entire input depth wise. During the forward pass, each filter is convolved across the width and height of the input, computing the dot product between the entries of the filter and the input and producing a 2-dimensional map of that filter. As a result, the network learns filters that activate when they see specific features at some spatial position in the input.

Stacking the maps of all filters forms the full output of the convolution layer for the next layer. Every entry in the output volume can be interpreted as an output of a neuron that looks at a small region in the input and shares parameters with neurons in the same activation map.

This is how a filter typically looks after the first Convolution layer. The color/grayscale features are clustered because the net contains two separate streams of processing, and an apparent consequence of this architecture is that one stream develops high-frequency grayscale features and the other low-frequency color features.
When dealing with high-dimensional inputs such as images, fully connected networks are impractical because they don’t take the spatial structure of the data into account.
Convolutional networks exploit spatially local correlation by enforcing a local connectivity pattern between neurons of adjacent layers. Each neuron is connected to only a small region of the input volume. The extent of this connectivity is a hyperparameter called the receptive field of the neuron. The connections are local in space (along width and height), but always extend along the entire depth of the input volume. Such an architecture ensures that the learnt filters produce the strongest response to a spatially local input pattern.
Since there are so many weights to be learned the Neural Network performs a pooling operation (i.e sampling) in order to reduce dimensionality. The most common pooling operation is max pooling.

CNN Layer Patterns
CNN architecture stacks a few Conv-ReLU layers, follows them with POOL layers, and repeats this pattern until the input has been merged spatially to a small size. At some point, it is common to transition to fully connected layers. The last fully connected layer holds the output (i.e. class or scores).
Advantages of the CNN include:
- Sharing weights/filters throughout image vs weight per pixel in fully connected which saves computation on feed forwarding.
- Spacial locality of pixels used therefore a CNN can detect objects in images in different orientations.
Example CNN - VGG
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
CNN Video Explanation
CNN Example Code (Keras) on the MNIST Dataset
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
We Hope you enjoyed this tutorial.
Happy AI blogging!!
Make sure to up vote if you enjoyed.
From neurallearner :)
I'm here, man ;-) !
Happy to see people writing about AI.
I'm a poet but enjoy trying to understand the numbers and right angles.
Neural nets are akin to decision trees.
Take a pattern of bits, apply some math to them, some of that may depend on what is next door to them, etc and arrive at a number.
Take that number and push it onto a layer as they call it. You can have one or more hidden layers as well as input and output layers which accept the input and operate or provide the result vector.
You vary weights of the layer nodes, decision points, and train them by iteration.
You can operate on images this way but they are hard to train and you need to iterate all layers and pixels. Can be done in hardware of course also.
Operators akin to Sobel can be used to locate edges, gradient, and slope direction to get features out of the image space.
Find a bridge for instance. Long straight line and quick change in color or shading etc.
https://en.wikipedia.org/wiki/Sobel_operator
In this case we can look at machine lever or arm and see the edges and say it is moving... or it is still.
However we might miss fact it is broken and moving or broken and static.