Réseau antagoniste génératif - Générer de fausses images à partir de réseaux de neurones

Réaliser des créations à partir d’une machine est quelques choses de complexes. Une nouvelle approche utilisant des réseaux antagonistes génératifs ont permis de réaliser cela. Ce type d’approche permet notamment de générer des images de personnes qui sont très réalistes. Vous avez sans doute déjà vu des images générées par un ordinateur, comme vous pouvez le constater avec la figure ci-dessous. Dans cet article, nous allons chercher à comprendre le fonctionnement d’un réseau antagonistes génératifs.

Source : https://research.nvidia.com/publication/2017-10_Progressive-Growing-of
GAN - Generative Adversarial Network
Dans le cas d’un réseau antagoniste génératif (Generative Adversarial Network - GAN), nous allons avoir deux réseaux de neurones, un générateur et un discriminant. Le premier, le générateur, va nous permettre de générer, par exemple, une image à partir d’un bruit généré aléatoirement. L’objectif du générateur va être de générer des images qui nous semblent le plus réel possible. Le second est le discriminant. Il prend en entrée de son réseau une image, qui peut être une image générée ou une image que nous avons dans notre base de données. L’objectif de ce discriminant va être de nous indiquer si l’image passée en paramètre est une vraie image ou une fausse image. Lorsque nous parlons de fausses images, cela correspond à une image qui a été générée par notre générateur.
Ainsi, ces deux réseaux sont en compétition. En effet, le premier cherche à générer une image la plus réelle possible afin de pouvoir tromper notre discriminant. Son objectif est donc de tromper au maximum notre discriminant. Il va donc chercher à apprendre les points faibles de notre discriminant. Quant au discriminant, il va chercher à différencier les images qui sont présentes dans notre base de données et les images qui sont générées. Il va devoir évoluer à chaque nouvelle innovation qu’il apercevra de la part du générateur. En effet, à chaque fois que notre discriminant va échouer dans sa classification, il va évoluer en apprenant de ces erreurs.
Afin de générer des images, nous allons passer dans notre générateur un bruit. À partir de ce bruit, notre générateur va générer une image correspondante. Puis, nous allons passer cette image dans notre discriminant qui nous indique si oui ou non l’image passé est une image réelle ou fausse. Il existe aussi un autre cas ou nous passons directement une image réelle dans notre discriminant. En effet, nous ne pouvons pas uniquement passé des images d’une seule catégorie (réel ou généré), sinon notre système ne peut pas apprendre et donc il ne peut pas évoluer.
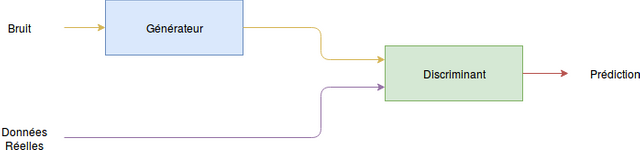
Schéma d’un réseau de neurones antagonistes génératifs.
Phase d’entraînement
Comme nous avons pu le voir, notre réseau est composé de deux éléments, d’un générateur et d’un discriminant. Notre objectif va être d’entraîner ces deux sous-systèmes pour obtenir de meilleurs résultats. Afin de rendre cela plus compréhensible, nous allons baser notre approche sur un cas d’application qui sera ici de générer des images de profil de personne.
Entraînement du Discriminant
Lorsque nous allons avoir une donnée qui est réelle, cela peut-être la photo d’un de vos amis que vous avez pris avec votre téléphone portable, nous allons chercher à ce que notre discriminant nous dise que notre image est réel. Pour rappel, le discriminant cherche à dire si une image que nous allons lui fournir en entrée est une image réelle ou non. Dans le cas contraire, lorsque nous avons une image générée, nous allons chercher à ce que notre discriminant nous dise qu’il s’agit d’une image non-réelle, c’est-à-dire d’une fausse image.
Lors d’une prédiction, notre système va associer à chaque catégorie (ici, réel ou généré) une probabilité lui indiquant à quel point il est sûr de lui. Ainsi, l’objectif du discriminant va être d’améliorer ses prévisions sur la catégorie d’appartenance de notre image. Ainsi, nous allons chercher à maximiser la prévision, c’est-à-dire la probabilité d’appartenance de notre image pour la bonne catégorie.
Entrainement du Générateur
Le générateur va, à partir d’un bruit, générer une image de personnes. Son objectif va être de rendre l’image générée de plus en plus réaliste afin que lorsque nous passons l’image générée dans notre discriminant, il ne s’aperçoit pas qu’il s’agit d’une image générée. Ainsi, il va chercher à rendre les images générées les plus réelles possibles pour notre discriminant. Afin de s’améliorer, nous allons nous servir des résultats que nous allons obtenir à l’aide de notre discriminant. En effet, c’est le discriminant qui va nous indiquer dans quelle direction modifier nos paramètres. Par exemple, si notre discriminant nous dit qu’il s’agit d’une image réelle, cela veut dire que notre générateur est plutôt performant. En revanche, si notre discriminant nous dit qu’il s’agit d’une image générée, nous devons encore améliorer notre système. De plus, le discriminant nous indique plus ou moins les endroits qu’il faut corriger sur notre image afin d’être de plus en plus performant.
L’une des questions que nous pouvons nous poser est sur la signification du bruit que nous fournissons en paramètre. Le bruit n’a pas de signification au début de notre système. En effet, il ne correspond à rien. Cependant, à force d’entraîner notre système, certaines valeurs vont correspondre à certaines caractéristiques de notre image générée. Par exemple, nous pouvons avoir une valeur correspondant à la couleur des cheveux, une autre pour la couleur des yeux… Cependant, nous ne pouvons pas les connaître à l’avance, car c’est au fur et à mesure que nous entraînons notre système qu’il arrive à développer ces caractéristiques.
Fonction de valeur
Nous allons maintenant traduire mathématique ce que nous venons de voir sous la forme d’une fonction de valeur. Ainsi, nous allons chercher à
Avec :
- Pz(z) : corresponds à une donnée ayant comme antécédent un bruit généré.
- Pdata(x): corresponds à une donnée ayant comme antécédent une image réelle.
- D : corresponds au discriminant.
- D(x) : représente la probabilité que x appartienne à nos données réelles plutôt qu’aux données générées.
- G : corresponds au générateur.
- G(z) : représente une donnée générée à partir d’un bruit.
Pour comprendre cette équation, nous pouvons remarquer qu’il y a deux termes principaux.
Corresponds à la valeur de notre discriminant lorsque il a une valeur x qui appartient à notre base de données. Lorsque D prédit une valeur est indique qu’elle est une donnée réelle pour lui, alors nous allons obtenir un 1. Dans le cas contraire, nous aurons un 0. Note : nous aurons des probabilités et non des valeurs exactes (Par exemple : 0.96). Ainsi, l’objectif pour notre discriminant, va être de maximiser D lorsque nous avons uniquement des valeurs qui appartiennent à notre base d’entraînement. En effet, ces données correspondent à des données réelles.
Corresponds à la valeur de notre générateur. Pour rappel, le but de notre générateur est de générer une image la plus réelle possible. Ainsi, nous allons fournir en entrée de notre système un bruit représenté par un vecteur z. De ce fait, G(z) correspond à une image générée à partir de notre bruit. Dans le cas où nous avons une image générée qui représente parfaitement une image réelle, alors lorsque nous passons cette donnée dans notre générateur et, dans le cas ou notre générateur pense qu’il s’agit d’une image généré, va nous donner une réponse proche de 1. Pour rappel, lorsque nous avons log(t) avec t qui tend vers 0, la fonction log tend vers -∞. Ainsi, dans le cas du générateur, nous allons chercher à minimiser cette valeur.
Algorithme - Corriger nos modèles
Pour réaliser l’algorithme correspondant à notre système, nous allons avoir à notre disposition un jeu de données d’image réelle, un ensemble de vecteur de bruit, et deux réseaux de neurones correspondant à un générateur et un discriminant. Ensuite, nous allons passer un lot de données de bruit dans notre générateur où nous allons obtenir en sortie un ensemble de données générés. Par la suite, nous allons prendre un lot de données réelles ainsi que les données générées que nous allons fournir en entrée de notre discriminant. Nous allons obtenir en sortie un ensemble de résultats nous indiquant les prédictions de notre discriminant. Ainsi, nous allons mettre à jour nos réseaux en se basant sur les résultats obtenus. Ainsi, nous allons distribuer l’erreur qui correspond à :
Quant au générateur, nous allons chercher à le corriger en se basant sur les résultats qu’aura faits notre discriminant.
Avantages / Inconvénients
L’un des premiers désavantages que nous avons avec ce système est que le bruit que nous fournissons ne nous indique pas explicitement les caractéristiques. En effet, nous ne savons pas quelles valeurs correspond à quelles caractéristiques. Pour le savoir, nous devons faire différents tests et visualiser les résultats afin de les déterminer.
Un autre problème durant la phase d’entraînement est que nous devons éviter de réaliser un sur-apprentissage sur notre générateur. En effet, cela peut-être problématique, car notre générateur nous générera des images presque identique à notre base de données. Or, nous voulons obtenir des données variées et créatives et non de simple copie de notre base d’entraînement.
Cas d’application
Les réseaux antagonistes génératifs ont divers cas d’application. Tout d’abord, vous pouvez vous en douter, on peut les utiliser afin de faire de la retouche photo. En effet, en fonction des entrées fournis, nous pouvons modifier notre image originale. Par exemple, si nous voulons modifier la couleur des cheveux d’une personne, ou bien ajouter des éléments comme des lunettes, nous pouvons les réaliser. Vous pouvez avoir un aperçu avec l’animation ci-dessous.

Source : https://github.com/ajbrock/Neural-Photo-Editor.
Nous pouvons aussi utiliser les réseaux antagonistes génératifs afin de créer des images à partir de texte. Ainsi, il vous suffira de dicter ce que vous souhaitez voir afin de le visualiser. Nous pouvons aussi utiliser ce genre de réseau afin d’augmenter notre base d’entraînement. En effet, lorsque nous faisons de l’apprentissage automatique, il nous faut énormément de données afin de pouvoir apprendre à la machine. Ainsi, nous pouvons créer de nouvelles données avec ce système. Enfin, nous pouvons aussi utiliser les réseaux antagonistes génératifs afin de détecter certaines anomalies comme pour des échanges financier frauduleux. Bien entendu, il existe tout un tas de cas d’application pour ce genre de système et vous pouvez aussi utiliser ces réseaux afin de répondre à un problème que vous avez.
Conclusion
Les réseaux antagonistes génératifs ou GAN, sont des réseaux composés d’un générateur et d’un discriminant. Le générateur va chercher à créer des données et le discriminant va chercher à déterminer si une donnée est réelle ou non. Ainsi, le but du générateur est de tromper le discriminant, alors que le but du discriminant est de détecter les données fausses sans se tromper. De ce fait, ces deux réseaux sont en compétition et chaque évolution d’un des systèmes permet de faire évoluer l’autre système.
Sources
- https://arxiv.org/pdf/1406.2661.pdf
- https://arxiv.org/pdf/1710.10196.pdf
- https://research.nvidia.com/publication/2017-10_Progressive-Growing-of
- https://medium.com/@jonathan_hui/gan-whats-generative-adversarial-networks-and-its-application-f39ed278ef09
- https://skymind.ai/wiki/generative-adversarial-network-gan
Congratulations @rerere! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Ce post a été supporté par notre initiative de curation francophone @fr-stars.
Rendez-vous sur notre serveur Discord pour plus d'informations