📡🕸⛏ On Web Scraping and Beautifulsoup: An Interesting Exercise with SteemSTEM Distilled Posts

📡🕸⛏ On Web Scraping and Beautifulsoup: An Interesting Exercise with SteemSTEM distilled posts
By Enio
Steemit users are probably somewhat familiar with HTML, because we have probably used the HTML editor when writing a post on Steemit. It is a language that we can talk about extensively in another article. However, we can define it right now as a computer language that allows structuring and denoting content through a collection of descriptors called tags. In this way, it is common for us to create paragraphs (<p>...</p>), group them with divisions (<div>...</div>) and format them with bold (<b>...</b>), italics (<i>...</i>), etc.
As the Internet has developed, this important standardized language has done so as well, becoming the 'skeleton' of most of the content commonly accessed by all network users. Version 5 of the language (HTML5), for example, has tried to contribute more to the semantics of the content described with HTML. The idea is to make the description of the content more understandable, not for the flesh and blood reader (the human user), but rather for the 'artificial readers', that is, a series of programs that are constantly downloading and analyzing web content to extract data.
Indeed, the hypertext information is first consumed or 'predigested' by millions of computer programs before us, the human users. Even the web browser that you're probably using now is one of those programs that is downloading and analyzing HTML content (and other files), joining pieces and finally, rendering them (presenting them) very elegantly on your screen.
But there are many other programs that are quieter than the web browser and are constantly downloading and analyzing content, and some of them even track you; programs such as bots and, notably, web spiders. You can infer the existence of these programs in your daily experience by the fact that many websites require the user to overcome a little challenge ('captcha') that proves that for certain things he/she is indeed a person and not a 'robot'. (By the way, in case you did not know, 'captcha' is the acronym for 'Completely Automated Public Turing test to tell Computers and Human Apart').
Perhaps one of the best examples of these diligent programs is the Google spider, a powerful program that the company behind the search engine uses to automatically inspect millions of websites and index them, that is, to add them to a database in such a way that the information contained in those sites is easily recognisable and retrievable by the search engine when it operates. The fact that it's called 'spider' is a reference to the fact that it's examining the web (in Spanish, 'web' is not translated, so clarifying it's useful).
This is where Web Scraping comes in. It is a programming technique to extract information contained in HTML files, which is useful when it comes to collecting very specific information. The idea behind this technique is to analyze structured text with HTML and select only those sequences of characters that have the information you really want (hence the 'scraping').
For example, there may be a bot that periodically visits a meteorological institute website and only wants to monitor a few indicators published on that website. The bot will analyze the HTML document of the webpage and extract the characters that have that information, disregarding the rest of the document, as it is a focused search (scraping). Later, it will use that data for different purposes.
When an HTML document is sufficiently significant, meaning, when it has enough tags and atributes that appropriately describe the information they wrap, doing web scraping will be very simple as information is selected according to its description. In the aforementioned example, the climate indicators to be searched would be significant values if in the HTML document they were wrapped with a division element (div tag) that has an attribute describing that information (example: class = "indicators" ). With this, the bot can focus on finding the HTML element with that specific attribute, facilitating its work.
However, in other times this won't be enough and you will need to (also) apply lower level methods (i.e. more rudimentary) when extracting data; methods such as searching by character patterns (regular expression).
That said, as is often the case with the online world and IT sector, web scraping is not exempt from being associated with some legal controversies. There are websites that prohibit the application of web scraping on them, but the regulation of this field is complex since the Internet has no conventional borders and the laws of the countries vary. In addition, this would only make sense when it comes to 'intellectual property' (the almighty argument that some want to raise for any reason) and not information of public interest. The case of LinkedIn was notorious, as a federal court in the United States prohibited this company from blocking a startup from accessing part of its public data.
However, we must make the disclaimer that web scraping is just a 'technique' and like any technique -as Morin, Bunge and many others would say- does not cease to be ethically ambiguous, since it can be good or it can be bad (contrary to science that is not ambiguous because it is always good 😉).
Well, so far the concepts are clear, but how do you implement web scraping? Let's find out.
Beautifulsoup
We become a little more technical now. When implementing web scraping, sometimes it may be enough to use what is offered by the standard library or the native functions of the language used, especially when the involved task complexity is low. However, it will generally be more sensible to resort to the use of a specialized web scraping library, such as Beautifulsoup of the Python programming language.
This is one of the most famous and powerful Python libraries for web scraping. The word "soup" in the library name may be understood as an allusion to the fact that HTML source code can be intricate and confusing (hence the metaphor of 'soup'). As an exercise, try to access the sources of this page you are reading. If you are on a desktop browser, then right click on this paragraph and locate an option like 'view page source'. You will see the HTML source code of the post and it may look like a 'grapheme soup' compared to this view of the page.
However, the word 'beautiful' could be a reference to the fact that the HTML document will be 'beautifully' prepared to be used for programming purposes. Indeed, the library has a parser that runs through the entire text of the document and associates each of its parts with respective data structures. By far this will make eassier to operate with the document content. The use of this library will be shown bellow.
In this regard, we are going to resort to some posts of the @SteemSTEM account, specifically those referred to as 'SteemSTEM Distilled'. These posts are weekly reports where the community management team usually refers to some posts curated during the week which have been manually chosen ("distilled") to be specially recognized. So, we are going to use 90 of these reports (from the 1st edition to the 90th edition). All of them contain the title and URL of each picked post. The idea is to make a script to extract these titles and URLs by means of web scraping. Here is a description of the procedure followed:
Part 1: The HTML content of each post is downloaded and stored.
- A script was written specifically for this first phase
- It was noted that almost all report posts have a URL similar to this one:
https://steemit.com/steemstem/@steemstem/steemstem-distilled- [number_of_report]
However, a few posts didn't follow this pattern. To determine which ones did not, the string"PostFull__body"was searched within the HTML document of each post. Those posts which did not contain this string were practically empty webpages and since there were very few cases, the report number attached to these webpages URLs was used to manually locate the missing "distilled" reports in the @steemstem blog and thus determine the correct URLs and download the HTML content of those posts as well. (Note: I could certainly have used the Steem API, but my intention was to do all of the web scraping without it). - Once the HTML files of all of the posts were downloaded, they were stored for easier further processing. The download was executed with
request, a library that is also part of the whole technique.
Part 2: A function was written to apply filters and extract a list of titles and URLs from the distilled posts. This function is shown in the following image and is commented as follows (see image).
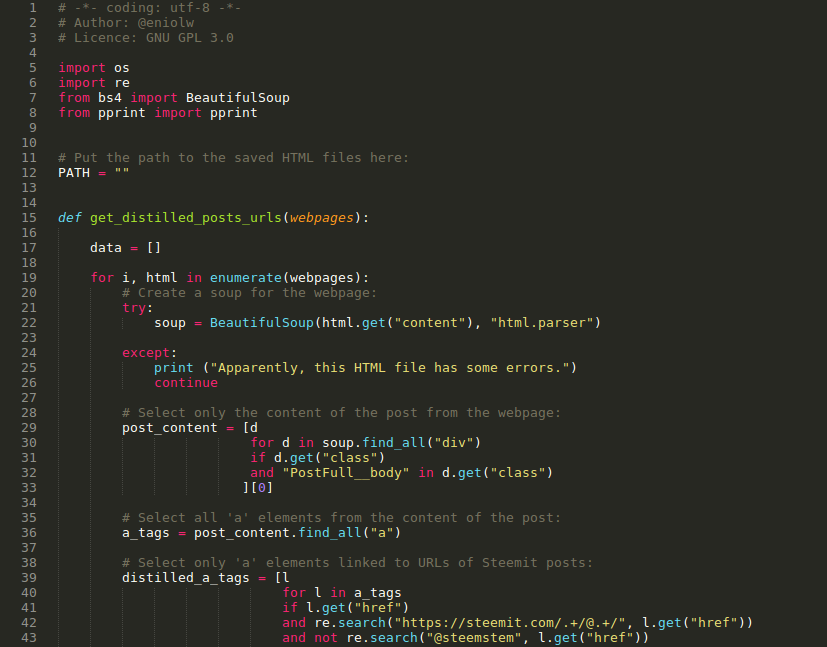
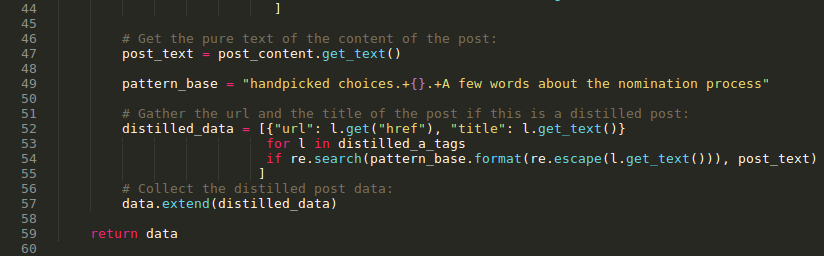
⬆️: function that applies BeautifulSoup to extract titles and URLs of distilled users. Author: @Eniolw License: CC BY 2.0
The script shown has comments that describe what is being done and is probably quite understandable for computer scientists and programmers. It basically does the following:
- BeautifulSoup is applied to each HTML file.
- For each instance of BeautifulSoup, it is extracted the division element (
div) whose class is"PostFull__body", since it's there where the post content itself and the data we are interested in are located. - The
aelements are extracted from this division and only those that meet the following criteria are chosen: - 1) The
hrefattribute matches this format"https://steemit.com/.+/@.+/", so we can be sure it's a Steemit post URL. - 2) The
aelement has to be located after the string:"handpicked choices"and before the string"A few words about the nomination process". This restricts the context of the search to the part of the report where the distilled posts are announced. - 3) The
hrefattribute doesn't contain the string@steemstemin order to prevent a ordinary or protocol post from @SteemSTEM mentioned in the context of the search to be picked. - From the resulting
aelements, the text andhrefattribute value are extracted, that is, the posts' title and URL. - In the end, a list with 601 results was obtained which is what the created function returns.
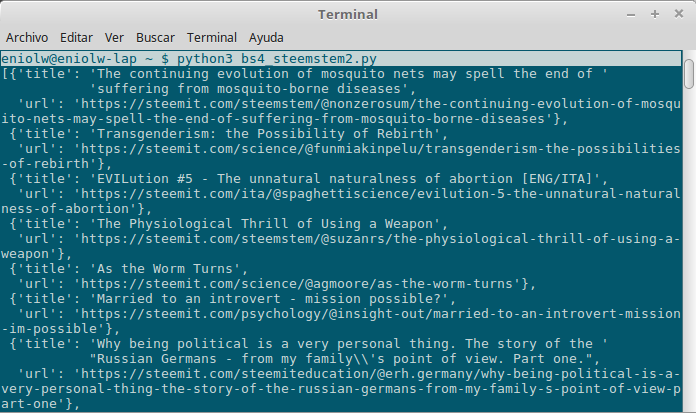
Since the results are many, they are not being posted here but in this shared document. However, I do post an image with the partial output of the script (see next image).
Also, to show the usefulness of this technique and exercise, I will add some other curious results that can be extracted from this data and experience:
Number of SteemSTEM Distilled reports examined: 90
The only report which format number differs from the others is this: SteemSTEM Distilled #5x13. For some reason the writer didn't put "65" instead of "5x13" there.
Number of distilled posts: 601
Number of different users with distilled posts: 252
|
|
10 Frequently Used Tags According to the Distilled Reports:
|
|
Summing up
Throughout this article we have exposed some small notions of IT about the functioning of certain aspects of the web that could be more relevant than we might expect, because, as you can see, we are active users of HTML on Steemit. After having read this publication we can infer that the way we structure our posts could be sensitive for the millions of readers who visit them daily and who are not precisely carbon-based life forms (human beings), but virtual entities built on silicon (software). Yes, many computer programs visit your blog daily and try to understand in their own way the content you publish.
We have talked about web scraping as a programming technique and created a Python script to apply it. The algorithm developed has combined the search according to the HTML semantics (selection of the div element with the class "PostFull__body" and the a elements) with a search based on regular expressions which has been facilitated by the fact that the 90 posts analyzed have a fairly regular structure. Some variation in the structure of future reports could affect the performance of this algorithm. In addition, we must note that if in any distilled post summary another Steemit post were mentioned and linked, this algorithm may not be sensitive to it, so it would need more diligent filters. This is a limitation due to the fact that Steemit users cannot properly add HTML semantics to their posts content.
The information covered here is an introduction to the topic of web scraping and Beautifulsoup, which is more extensive if it is approached more technically. Therefore, I ask you, dear reader, to check the official documentation of this library if you are a programmer and have an interest in deepening. In any case, in the future we will surely address more details of this library and other similar tools.
If you have any questions or comments, don't hesitate to let them know. See you.
- Beautiful Soup Documentation — Beautiful Soup 4.4.0 documentation; available here.
- Repository on GitHub: Useful-Steemit-Scripts(I posted the aforementioned scripts there).
- SteemSTEM blog on Steemit.
- SteemSTEM distilled posts from the 1st edition to the 90th edition
EXPLANATORY NOTES:
- Unless otherwise indicated, all of the images in this post have been created by the author, including the banner which is based on public domain images.
- The footer image is of public domain.
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @utopian-io and @curie.
If you appreciate the work we are doing then consider voting all three projects for witness by selecting stem.witness, utopian-io and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
You're the best!
Congratulations! Your post has been selected as a daily Steemit truffle! It is listed on rank 8 of all contributions awarded today. You can find the TOP DAILY TRUFFLE PICKS HERE.
I upvoted your contribution because to my mind your post is at least 8 SBD worth and should receive 268 votes. It's now up to the lovely Steemit community to make this come true.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigThank you! :D
Interesting stuff, @eniolw. Recognized a few users there. I've been practising a lot of HTML and .py recently, so i'll hop in on Github to check out the scripts later.
Also, your second tag is so OMG!
😂 I already corrected... I have to check the tool I used to post. Thanks!
Really expansive post. Lots of detail as well as a unique application and analysis. Nice job!
Thank you for your nice assessment and review, @JustTryMe90
:D
This is a really useful post. Web Scraping will come really handy for multiple analysis. Well done.
Thanks @DexterDev. Yeah, Web Scraping can be really useful!
Do you mind putting the code in github or so?
Sure. I have already done it. Please, check the section "SOME SOURCES OF INFORMATION AND USEFUL LINKS" I put the links to GitHub there.
Sorry I missed those. Thanks
Hi @eniolw!
Your post was upvoted by Utopian.io in cooperation with @steemstem - supporting knowledge, innovation and technological advancement on the Steem Blockchain.
Contribute to Open Source with utopian.io
Learn how to contribute on our website and join the new open source economy.
Want to chat? Join the Utopian Community on Discord https://discord.gg/h52nFrV
Thank you very much!