[Tutorial] Building a Web Crawler With Python 2

Repository: Python Repository Github
Software Requirements:
Visual Studio Code(Or any preferred code editor)
What you will learn:
In this tutorial you would learn to build a web crawler with these functionalities
- Understand What Crawling is
- Learn how to observe url pattern changes and use them to create better crawlers.
- Use the
Beautiful Souppackage in thebs4module.
Difficulty: Beginner
Tutorial
What is crawling
In this tutorial we would be further developing the bot we started creating in the last of this series. We would add more advanced functionality so that it would be able to search through more pages by observing url patterns for the site we would want to crawl.
Before we do this, due to a comment by @portugalcoin, i would try to explain what a webcrawler is a bit better.
Lets start with the wikipedia definition.
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing (web spidering).
Web search engines and some other sites use Web crawling or spidering software to update their web content or indices of others sites' web content. Web crawlers copy pages for processing by a search engine which indexes the >downloaded pages so users can search more efficiently.
So that quite simplifies the definition to a well understandable form. Lets move on to improving our code.
When writing a webcrawler using beautiful soup, you would need to understand how the web url are directed and rerouted. Most times, whenever you navigate to a new page, the name is just added to the preset url like '/newpage'.
Some websites are structured differently, so you would still need to move around and understand the structure for that site before you write your crawler.
So on to the coding
From our last tutorial, this is where we are
from bs4 import BeautifulSoup
import requests
import re
def thecrawler(maxpages,movie):
page = 1
searchnetnaija(movie)
while page < maxpages:
searchtoxicwap()
def searchtoxicwap():
url="www.toxicwap.com"
def searchnetnaija(movie):
search = True
while(search):
print('This works')
url1="http://www.netnaija.com/videos/movies"
sourcecode = requests.get(url1)
plain_text = sourcecode.text
soup = BeautifulSoup(plain_text,'lxml')
list = []
for link in soup.find_all('a'):
lin = link.get('href')
list.append(lin)
search = False;
for dat in list:
x = re.search(r'movies',dat)
if x:
s = r'%s' % movie
y = re.search(s,dat)
if y:
print(dat)
Understanding Url patterns
We can see that the problem with this is that it only searches one page in the website. To make it search other pages, we would need to see how our url changes for other websites. First head to the website here and navigate through the movie pages while noticing how it changes.
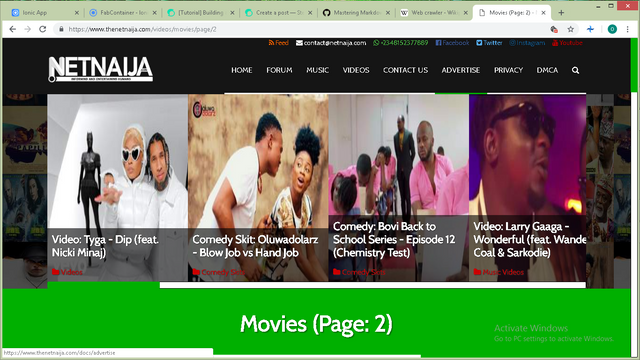.png)
From this page all we want is the url
.png)
So if you payed attention you would see that as stated earlier the number at the end of the url for each page changes to the corresponding page number and this is the feature that we can exploit.
To loop through a certain number of pages we would use a while loop like this
def searchnetnaija(movie,max_pages):#Add a new max_pages arguement to the function
page = 2#Start off from page 2
while(page < max_pages):
url1="http://www.netnaija.com/videos/movies"+ str(page)#Interpolate into the url
page += 1#navigate to the next page
Since we would want to use a single function to search through multiple sites, we would need to send the same max_pages parameter through all the pages. Hence, you could use this parameter to call all the functions within your main function.
def thecrawler(maxpages,movie):
searchnetnaija(movie,max_pages)
So after this is done we would like the crawler to navigate to the link we've found and find the download link within it. Most sites wouldnt want bots going through their websites and downloading files, so they make on-screen buttons that must be used to download these files. You could choose to just navigate to the link your bot has provided or you could choose to use a module called pyautogui to actually click on the button and download your file within your browser(This would be quite more complex, but would be happy to do a tutorial on it if interest is indicated).
So we would need to navigate to our new page and look for the link for the download.From the url method we learnt above, we would see that the links for movie downloads have '/download' beside them which leads to a new site for download. So we just add this to our code and we should be good to go.
for link in newSoup.find_all('a'):
a = link.get('href')
lis.append(a)
for dat in lis:
x = re.search(r'movies',y)
if x:
s = r'%s' % movie
y = re.search(s,y)
if y:
new_link = url1 + '/download'#this line adds the download to the url and gets us the link
requests.get(new_link)
Thanks for reading
You could head to my Github to see the code for this tutorial.
Thank you for your contribution @yalzeee.
After an analysis of your tutorial we suggest the points below:
Improve your tutorial texts, and please put punctuation. It is important that the tutorial be well written.
We suggest you add more comments to your code, so it's very important for the reader to understand what you are developing.
Put your tutorial as detailed as possible for the user to understand well the theory and practice that you are explaining in your tutorial.
We suggest that in your tutorial always have advances of your code without repeating the code of the previous tutorial.
Thanks for your work on developing this tutorial.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thank you for your review, @portugalcoin! Keep up the good work!
Hello! Your post has been resteemed and upvoted by @ilovecoding because we love coding! Keep up good work! Consider upvoting this comment to support the @ilovecoding and increase your future rewards! ^_^ Steem On!

Reply !stop to disable the comment. Thanks!
Hello! I find your post valuable for the wafrica community! Thanks for the great post! We encourage and support quality contents and projects from the West African region.
Do you have a suggestion, concern or want to appear as a guest author on WAfrica, join our discord server and discuss with a member of our curation team.
Don't forget to join us every Sunday by 20:30GMT for our Sunday WAFRO party on our discord channel. Thank you.
Congratulations @yalzeee! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board of Honor
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard:
Hi @yalzeee!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @yalzeee!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!