Writing a simple Compiler on my own - Bison basics

Hello it's a me again Drifter Programming! Today we continue with my Compiler series again to talk about the C-tool Bison (improved version of YACC) that will help us with the Syntax and Semantic Analysis steps of our Compiler.
Our whole compiler is based on the Syntax and so everything after the Lexer (Lexical Analysis) will actually be done in Bison!
This post is all about explaining how Bison works and what it offers to us. After this post we will be able to start writing the Parser (Syntax Analyst) for our Compiler!
So, without further do, let's get started!
Bison Introduction
In this series so far we used Flex, which is a C-tool that generates lexers (lexical analysts) that can be used for compilers. Bison, on the other hand, generates parsers (syntax analysts). In my previous post we covered different types of grammars and also said that Bison (or previously known us yacc) is using LALR(1) contex-free grammars. This is the default type of parser generated and we are able to change it, but it's actually good enough for most languages, and of course more than enough for the simple C-Language that we are using!
Compatibility with Flex
The good thing about Bison is that it is compatible with Flex, which means that we can tokenise our program using Flex (our lexer) and then provide those tokens to Bison to do the Syntax and Semantic analysis on.
This tool will make it easier for us to write the parser for our compiler cause:
- It's written in C
- Compatible with yacc, flex, lex etc. in Unix environment
- Relatively easy to use
- Gives us a parser with high performance
- As mentioned already it uses LALR(1) grammars AND
- It can also define and check the semantics
Downloading Bison
In a previous post I already told you to install Cygwin and the gcc, flex and bison packages!
![]()
You can get Cygwin from here: https://www.cygwin.com/
Choose the packages gcc, flex and bison when installing it and try not to download the debug files!
Bison File Structure
A Flex file/program was build up in 3 parts and so does a Bison file!
The first part is used for definitions.
Those can be:
- C/C++ definitions (data types, variables, functions)
- Bison definitions (tokens, non-terminal symbols, semantics etc.)
The second part is used for the grammar rules.
In that part we write the grammar rules and also an action (mostly semantic analysis or intermediate code generation) that will be executed when a specific rule is triggered.
The third and last part is optional C code.
There we mostly write our main() function and other small functions that we use inside of the grammar rules or have defined in the first part.
So, the structure of a Bison program is:
// definitions%%// grammar rules%%// functionsLet's get into each part more in depth!
Definitions
The C/C++ definitions are self-explanatory and are the same as in Flex.
So, we include libraries, define constants, functions and variables.
All that using:
%{ // c code%}After that we have the Bison definitions.
A token can be defined using %token.
For example:
%token STRINGWith %start we define the starting symbol!
%start programWith %left, %right, %nonassoc etc. we define associativity.
For example:
%left PLUS MINUS%right MOD%nonassoc EQUALS
Priority is defined by the order that those semantic rules are placed wth. The priority is increasing downwards and so EQUALS in our example has a higher priority then PLUS or MOD. Tokens in the same line have the same priority.
With %prec we can define the priority inside of a grammar rule directly!
Grammar rules
A grammar rule is of the form:
a: b;The left side is a non-terminal symbol.
The right side is 0 or more terminal and non-terminal symbols.
For example:
expression: term PLUS expressionexpression and term are non-terminals and PLUS is a terminal.
We tend to use small letters for the non-terminals and caps for the terminals.
As already mentioned previously we can also define actions for those rules.
These can be done like that:
a: b { // action C code }We can also define multiple right-sides like that:
a: b | c | d ;Of course each of those rules can have a different action!
For empty rules we use /* empty */ like that:
a : /* empty */ | b ;You don't have to put a comment, but it's easier to distinguish it!
Functions
The last and final part contains functions that are helpful for the actions and also the main() function!
There is not much more to say :P
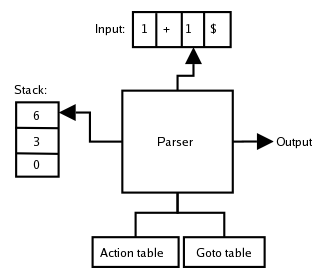
How the parser works
Lastly, let's get into how the parser works.
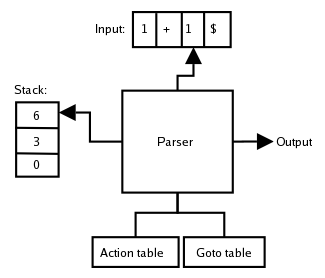
Because it's an LR parser (actually LALR(1) approximation of LR) it analyzes bottom-up and uses a stack to store the elements of the language/program.
The following actions take place on the stack:
- shift -> insert the next input element to the stack.
- reduce -> applied to the head of the stack when the right-side of a rule has been found by replacing the right-side with the left-side.
- accept and abort that tell us if the analysis was successful or not (grammar error or not)
When finding conflicts Bison solves them like that:
- shift/reduce -> use the shift rule
- reduce/reduce -> use the first reduce rule that was defined
With bison -v we can generate a file that describes the conflicts.
The main function of our parser is yyparse() that needs to be run from the main() function. This function runs yylex() which is the lexer function that we got from Flex.
Running Bison
Lastly, let's also get into how we run Bison in the Console.
When having only Bison we do:
bison -d parser.ygcc -o compiler parser.tab.c./compilerWhen having Flex also then we do:
bison -d parser.yflex lexer.lgcc -o compiler parser.tab.c lex.yy.c./compilerA simple Example
Here a Bison program for a simple calculator:
%{#include<stdio.h>#include<ctype.h>void yyerror(char const*s){ fprintf(stderr,"%s\n",s);}%}%token DIGIT%%line : expr '\n' { printf ("%d\n" , $1 ) ; }expr : expr '+' term { $$ = $1 + $3 ; } | term ;term : term '*' factor { $$ = $1 * $3 ; } | factor ;factor : '(' expr ')' { $$ = $2 ; } | DIGIT ;%%yylex( ){ int c; c = getchar( ) ; if (isdigit(c ) ) { yylval= c - '0'; return DIGIT ; } return c ;}int yyparse(void);int main ( ) { return yyparse( ) ;}You can download it from here: https://pastebin.com/XQ0bZWBV
Running it in the Console looks like that:
Compile:
Run:
Image Sources:
http://goodnature.nathab.com/wp-content/uploads/2017/05/HenryHoldsworthFumanchu_Web.jpg
{kind=link}
https://elliotideas.com/wp-content/uploads/2016/06/cygwin-logo.png
{kind=link}
https://upload.wikimedia.org/wikipedia/commons/2/2b/LR_Parser.png
{kind=link}
Previous posts of the series:
Introduction -> What is a compiler, what you have to know and what you will learn.
A simple C Language -> Simplified C, comparison with C, tokens, basic structure
Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
Symbol Table Structure -> Why Symbol Tables and Basic implementation
Using Symbol Table in the Lexer -> Flex and Symbol Table combination
Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
And this is actually it for today and I hope that you learned something!
Next time we will create the grammar (a basic one to get started with) for our Language and implement it using Bison. After that we can combine the Lexer an Parser together!
Bye!
I don't know what it is but I like programmers. They make the world better! 💯
Haha thank you! :)