"Każdy kiedyś zaczynał" - czyli jak nie programować w C++. Analiza napisanego przeze mnie 13 lat temu symulatora losowań lotto.
Nikt nie urodził się programistą. Każdy z nas stawiał kiedyś swoje pierwsze kroki w dziedzinie programowania. Każdy kiedyś zmagał się z dziwaczną wówczas dla niego składnią i jeszcze dziwniejszymi nazwami funkcji. Jednak niektórzy z nas pomimo licznych niepowodzeń przebrnęli przez ten najtrudniejszy ale także i najśmieszniejszy etap swojego programistycznego rozwoju. A komedia to była iście w stylu Monty Pythona... czasami nie wiadomo było czy się śmiać, czy płakać :)
Artykuł ten jest częścią migracji lepszych wpisów z moich starszych blogów, o której kiedyś już wspomniałem. Nie jest to zwykły copy&paste. Ten artykuł został złożony z dwóch[1][2], następnie został też ponownie zredagowany. Zapraszam do dalszej lektury :)
Programować chciałem zawsze... lecz ubzdurałem sobie, że to jakaś czarna magia, która jest nie do ogarnięcia. Jestem zawodowym programistą, więc chyba coś tam w końcu opanowałem. Jednak gdy teraz patrzę na to co pisałem 7 lat temu (w zasadzie to już 13), pewien jestem, że jednak jakaś magia mi wówczas pomagała, bo spoglądam na swój kod i zadaje sobie pytanie: "jak kod wyglądający w ten sposób mógł w ogóle się uruchamiać"?
Wszystkie moje pierwsze programy były dla mnie bardzo cenne. Pamiętam, jak kiedyś w pewnym momencie podjąłem decyzję, by postarać się zachować wszystkie listingi na zawsze, by później móc się z nich śmiać... i oto chciałbym ogłosić, że nadeszły czasy w których chętnie pośmieję się z nich razem z wami :)
Lata 2003 i 2004 były to dla mnie czasy spędzone z kompilatorem firmy Borland w wersji 3.1. Sam kompilator pochodził z 1992 roku, więc z czasów wręcz zamierzchłych, jednak taki kompilator dostałem od swojego nauczyciela, na takim się uczyłem (aż się łezka w oku kręci...).
W 2011 roku planowałem zacząć publikować kolejno kod źródłowy moich starych programów wraz z ich krytycznym omówieniem, zastanawiając się dlaczego wówczas właśnie tak a nie inaczej to napisałem. Ostatecznie... powstała tylko jedna taka analiza, w której omawiałem napisany przez siebie symulator losowania lotto.
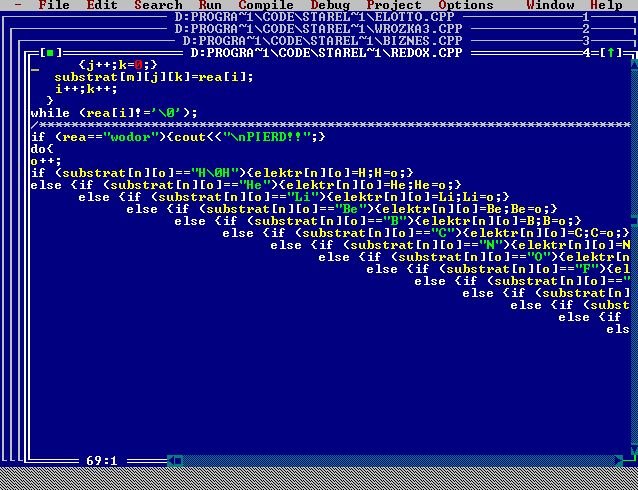
Zanim jednak przejdziemy do omówinia, pozwólcie że pochwalę się kilkoma screenshotami ze starych programów. Dla mnie te screenshoty są komiczne, bowiem o ile program jakoś działał... to kod, który krył się "pod maską" był... powiedzmy... bardzo kreatywny :D :)
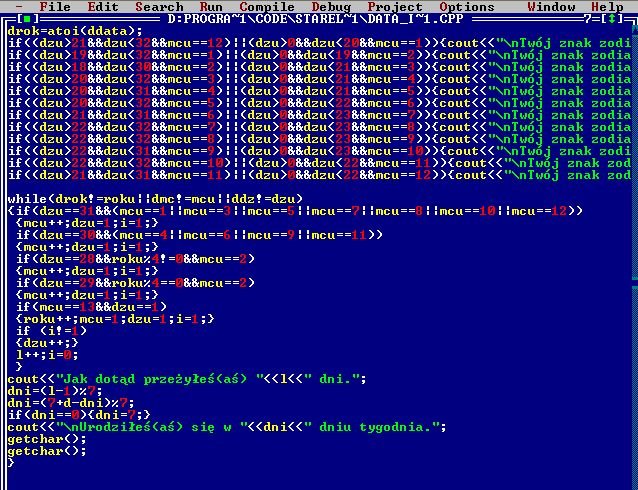
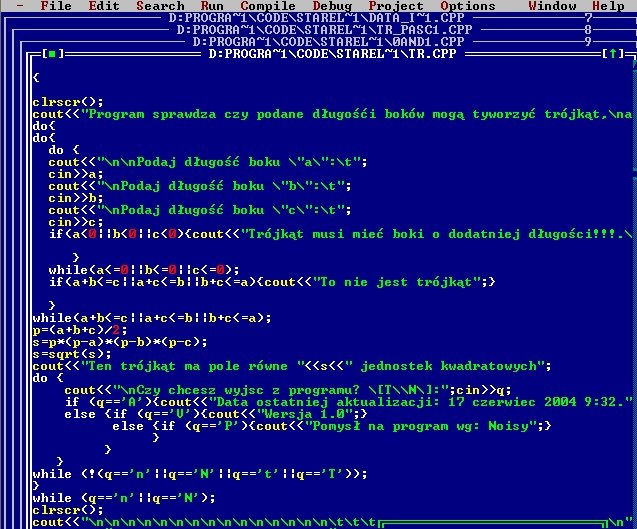
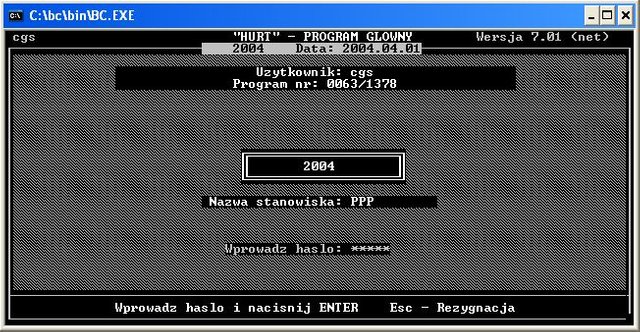
Omówienie kodu programu: symulator losowania lotto
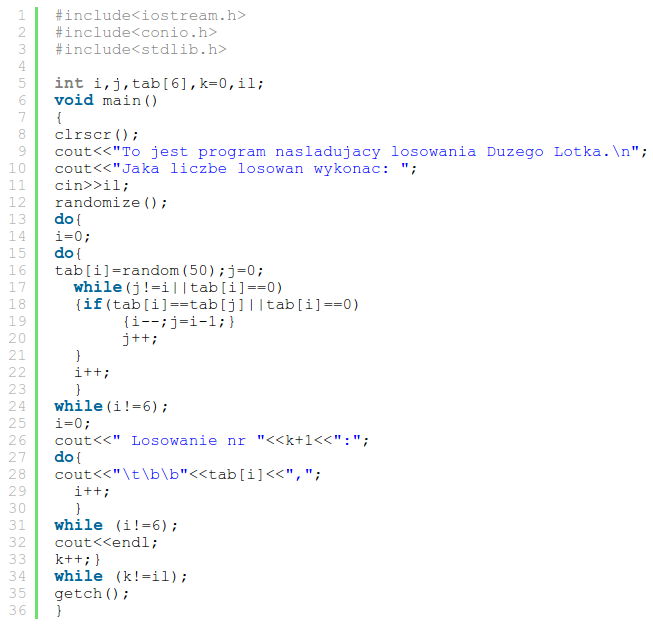
Poniżej postarałem się wytknąć SOBIE wszystkie błędy jakie popełniłem w niedzielę, 15 lutego 2004 roku o godzinie 15:16, uznając ten program za skończony (data ostatniej modyfikacji pliku ;) )
Jeżeli chciałbyś nauczyć się czegoś z tego wpisu, to prosiłbym Cię teraz, byś przed przeczytaniem dalszej części posta zastanowił się chwilę i sam się postarał wyłapać wszystkie błędy merytoryczne, składniowe i logiczne.
Zanim przejdę do omawiania błędów, chciałbym napisać co błędem nie jest (a raczej nie było, jak pisałem ów program).
Na samym początku programu włączam biblioteki:

Tych bibliotek w dzisiejszych czasach NIE należy stosować! Biblioteki iostream.h oraz stdlib.h mają swoje nowsze, ustandaryzowane odpowiedniki (iostream, cstdlib), które dostarczają takie same funkcje, lecz m.in. opakowują całość w przestrzeń nazw (namespace) std. Standard C++ wszedł w życie w 98r, sam kompilator w którym pisałem kod pochodził z 92r, więc zastosowanie ich przeze mnie, wówczas było w pełni uzasadnione. Biblioteka conio.h była pomocna przy tworzeniu tekstowego interfejsu użytkownika w systemach takich jak MS-DOS. Nie jest ona obecnie częścią żadnego standardu. W latach 90-tych była jednak dość popularna.
Wywołania takich funkcji jak clrscr, randomize, getch w śodowisku w jakim uruchamiałem program również były uzasadnione, ale o tym później.
W dzisiejszym poście błędy będę tylko wytykać. Nie będzie natomiast prawidłowego rozwiązania (pozostawiam to Wam jako ćwiczenie :) ). Podczas pisania tego wpisu doszedłem do wniosku, że całość była by zdecydowanie za długa. Chciałbym Was zmotywować, byście spróbowali sami coś stworzyć mając na uwadze wszystkie poniższe wskazówki.
Na początek błędy, które rzucają się od razu w oczy:
Ten kod jest brzydki!
Początkującym programistom bardzo ciężko wytłumaczyć, co to znaczy ładny kod. By wyrobić sobie ten "zmysł" potrzeba odrobiny doświadczenia. By go nabyć, należy dużo samemu pisać, czasami spojrzeć na obcy kod (i na ten ładny i ten brzydki ;) ). Jednak uważam, że mój stary kod nie wygląda tragicznie. Pomimo, że wcięcia są nieprawidłowe i stosowane są nie konsekwentnie, to jednak samo nawiasowanie jest nie najgorsze. Nawias klamrowy zazwyczaj znajduje się w tym samej kolumnie co drugi jemu odpowiadający (zazwyczaj, ale nie zawsze...).
Nie bez powodu rozpocząłem właśnie od tego "błędu". Przez początkujących programistów jest on lekceważony, bo "przecież nieważne jak program wygląda, skoro działa". Wielokrotnie spotykałem się właśnie z taką argumentacją np. udzielając korepetycji. Prawda jest taka, że pisząc "ładny kod", chronisz siebie, przed popełnianiem kolejnych błędów, dlatego (uwierz mi proszę!), gdy osoba, której pokazujesz kod, mówi Ci, że jest brzydko napisany lub źle sformatowany, to nie robi tego dlatego, że inny styl jej się wygodniej czyta, lecz dlatego by uchronić Cię przed naprawdę głupimi i trudnymi do wykrycia błędami.
Jakie konkretniej błędy są tutaj popełnione? Funkcja main, pomimo, że jest wyjątkowa, ciągle jest jednak tylko funkcją. Ciało funkcji zawsze powinno być wcięte (zwyczajowo albo o jeden znak tabulacji, albo o kilka znaków spacji (najczęściej 4)).
zatem źle jest:
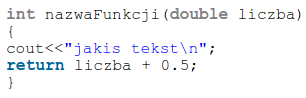
gdyż powinno być raczej (tzw. formatowanie Allman-ANSII):

lub ewentualnie (formatowanie K&R)

Analizujmy dalej. W linijkach 17-21 aż roi się od błędów:

Jeżeli już koniecznie chcemy if umieścić zaraz pod while, by nie marnować miejsca na pustą linijkę, to powinniśmy wówczas jednak stosować konwencje:

if powinien być wcięty względem while, czyli powinno być raczej tak:

Jest lepiej, jednak w powyższym kodzie, tak jak i w oryginalnym ciągle istnieje bardzo błędogenny zapis, a mianowicie

Zwróćmy uwagę na to, że obie linijki są wcięte (co mogło by sugerować, że obie wcięte linijki wykonają się tylko wówczas gdy warunek z instrukcji if zostanie spełniony. Tak mogłoby to być odczytane, gdyż powszechnie stosuje się właśnie zasadę: "względem if powinien być wcięty tylko ten kod, który jest od niego zależny".
Kwestią dyskusyjną jest fakt, czy w ogóle dopuszczalne jest zapisywanie dwóch poleceń w jednej linii. Pewne jest natomiast to, że istnieje duża grupa osób, które mówią, że tak nie należy robić, gdyż może to później utrudniać ewentualne debugowanie (które jest robione przecież linijka, po linijce).
Zatem zdecydowanie lepszym kodem byłoby:

lub stosując bardziej zwięzłą konwencje K&R:

Oczywiście piszę, że tak było by lepiej, co jednak nie oznacza, że tak było by dobrze ;) Mam nadzieję, że co niektórzy zauważyli, że część tej pętli jest tutaj w ogóle nie potrzebna! Wrócimy do tego później ;)
Wiele rzeczy można też powiedzieć na temat następnej pętli z linijek 27-31:

Zawartość tej pętli do{}while(); powinna być wcięta w obu linijkach (zarówno cout jak i i++). W pierwotnym kodzie lekko przesunięty nawias w linijce nr 30 zapewne swoje miejsca znalazł właśnie tam, by być dokładnie pod swoim odpowiednikiem z lini 27. Jest w tym pewna logika, jednak raczej częściej się stosuje zapis:

lub krócej:

Dobra... idziemy dalej.
Jeżeli patrząc na linijkę 33 wiesz (i jesteś od razu pewny), jaki obszar domyka zamykający nawias klamrowy, to jesteś naprawdę niezły ;)
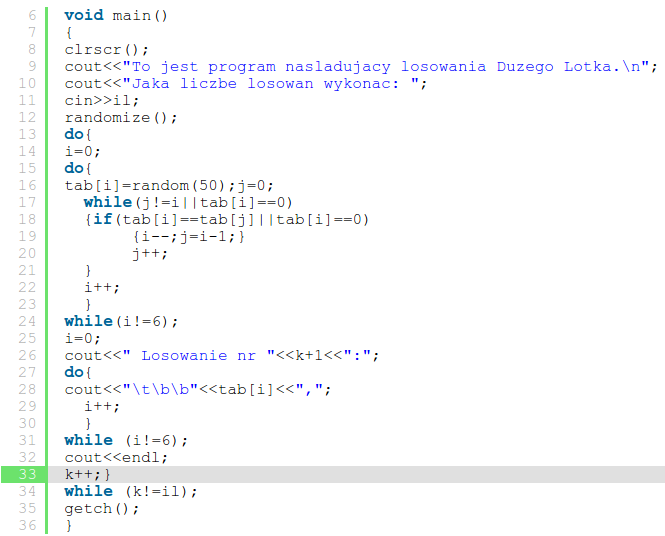
Szukając odpowiedzi na to pytanie, nasz wzrok podąża do góry. Napotyka na słowo kluczowe while z linijki 31. Czytając kod pobieżnie można by wysunąć wniosek, że to właśnie tę pętle zamykał owy nawias, co jak się okazuje prawdą nie jest!
Średnik znajdujący się za słowem while, może nam sugerować, że jest to pętla do{}while( ); a nie pętla while, tak jest właśnie i w tym przypadku. Po głębszej analizie okazuje się, że nawias z 33 linijki zamyka obszar rozpoczęty w linijce 13. Kto jest zdziwiony? :) Nawet ja, czyli autor kodu ;)
Formatowanie kodu, to naprawdę temat rzeka. Jest to również często temat lekceważony przez początkujących adeptów sztuki programowania. Nie istnieje idealny styl formatowania, jednak ludzkość dorobiła się kilku takich, które mają stosunkowo mało wad i dość dużą liczbę zalet. Postaraj się zatem używać formatowania z większą liczba zalet ;)
Nazwy zmiennych oraz zmienne globalne
Zacznijmy omawianie błędów merytorycznych. Jak widzimy w linijce 5, na raz poza obszarem funkcji main deklaruję 4 zmienne typu int oraz jedną 6 elementową tablicę tego samego typu.
Czy to jest błąd? Nie do końca, ale tak nie wyglądałby idealny kod. Jeżeli zadajesz sobie pytanie, dlaczego umieściłem je kiedyś właśnie akurat tam, to muszę Ci powiedzieć, że na szczęście pamiętam uzasadnienie mojej decyzji. Zmienne deklarowane jako globalne (poza zakresem jakiejś funkcji) są inicjalizowane zerami. Prawda jest taka, że kiedyś o tym fakcie dowiedziałem się w liceum od swojego nauczyciela informatyki. Chyba starałem się używać tego sposobu, by samemu nie zapominać o zerowaniu zmiennych. Choć w tym tłumaczeniu nie pasuje jeden fakt... to po co w takim razie zerowałem tam zmienną k? :) Nie potrafię tego wyjaśnić ;)
Nazwy zmiennych i, j, k zostały wbrew pozorom dobrane całkiem nieźle. Tymi nazwami zwykle się obdarza zmienne służące za liczniki w pętlach. Patrząc na cały program można stwierdzić, że właśnie taką rolę odgrywają te trzy inty, pomagając liczyć kolejne obiegi poszczególnych pętli. Jednak skoro doskonale zdawałem sobie sprawę z ich roli, to powinienem też się postarać, by ich deklaracja była blisko miejsca ich użytkowania. Dużo czytelniejszym rozwiązaniem było by deklarowanie ich tuż przed konkretną pętlą (a nawet tak jakby w jej części... bo prawda jest taka, że lepiej było by tutaj zastosować pętle for, która umożliwia deklaracje zmiennych w pierwszym "obszarze").
Nazwa zmiennej il powinna być dobrana lepiej. W tym programie do tej zmiennej będzie wczytywana wartość mająca oznaczać żądaną liczbę losowań do wykonania, zatem naprawdę nie ma zbyt wielu powodów, dla których nie należałoby tej zmiennej po prostu nazwać np. liczba_losowan. Długie nazwy nie są takie złe. Łatwiej odgadnąć znaczenie takich zmiennych, gdy ich nazwa niesie ze sobą jakąś informację.
Funkcja main
To że coś działa, nie znaczy że jest poprawne i będzie działać zawsze i wszędzie. W linijce 6. mamy tego przykład. Wykonywanie programu zaczyna się od wywołania funkcji main.

Mógłbym się bronić, że wszystko jest ok, ponieważ mój kompilator jakiego używałem nie zgłaszał żadnych roszczeń , jednak nowsze kompilatory, czegoś takiego by mi nie przepuściły bez słowa i z pewnością przypomniały by mi, że funkcja main, powinna zwracać wartość typu int, a dokładniej wartość 0 w przypadku bezproblemowego zakończenia z programu, oraz wartość błędu w innym przypadku.
Obecnie zatem prawidłowy szkielet mógłby wyglądać tak:

Funkcje clrscr oraz randomize
W liniach nr 8 i 12 wywoływałem wspomniane już funkcje:

Popatrzmy co na ich temat mówił help mojego ówczesnego kompilatora:
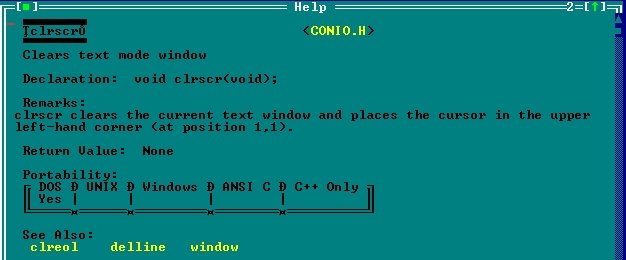
Funkcja clrscr, czyści cały ekran i umieszcza kursor w lewym górnym rogu ekranu. Wywołanie tej funkcji było poprawne, jednak w dzisiejszych czasach chcąc osiągnąć podobny efekt lepiej wywołać np:

oraz

Okazuje się, że druga funkcja randomize wcale funkcją być nie musi. Mój ulubiony help pisał o niej tak:
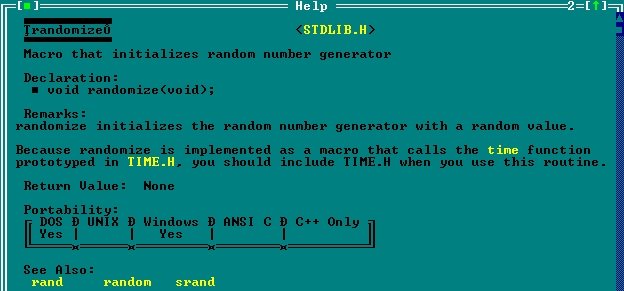
Wywołanie tej funkcji to tak jakby "rozkręcenie maszyny losującej", potrzebne by funkcja losująca faktycznie zwracała względnie losowe wartości. Z pomocy kompilatora Borland dowiadujemy się, że randomize to tak naprawdę macro (co jak sprawdziłem, też nie zawsze jest prawdą :P ). Ponadto okazuje się, że program w ogóle nie powinien mi działać, gdyż zgodnie z instrukcją nie dołączyłem #include<time.h>.
Skoro randomize nie jest ani funkcją ani makrem, to czym jest? Okazuje się że czasem funkcją a czasem makrem. Oto fragment pliku STDLIB.H:
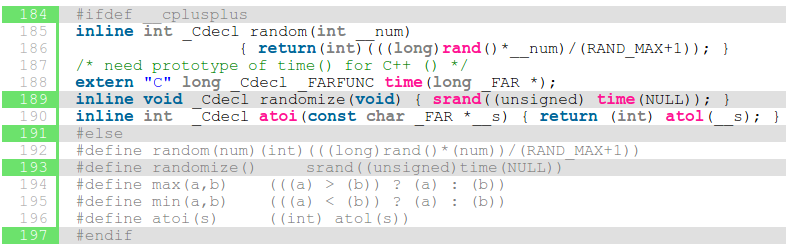
W zależności od tego, czy program był pisany w języku C lub C++ randomize przybierał postać funkcji lub makra. W tym konkretnym przypadku mieliśmy do czynienia z funkcją. Tak czy inaczej powinienem w swoim programie dołączać plik nagłówkowy time.h, czego nie robiłem. Nie do końca jestem pewien, dlaczego zatem cały program w ogóle się kompiluje. Zakładam, że któraś z innych bibliotek dołącza ją przy okazji. Żaden programista nie powinien liczyć na takie "przy okazji", gdyż bardzo by się zdziwił, gdyby po usunięciu innego wydawałoby się niepotrzebnego include'a, nagle wszystko przestało by działać.
Jeżeli chodzi o dwa polecenia cout z linijki 9 i 10 zawierające się pomiędzy wywołaniami clrscr i randomize, nie czepiam się ich.
Liczby (pseudo)losowe
A teraz czas na mój ulubiony fragment tego programu, a mianowicie:

Najpierw krótki omówienie genezy tego kodu. W losowaniach Dużego Lotka (w 2009r zmieniła się nazwa, na Lotek) losowanych jest 6 liczb z zakresu od 1 do 49. Funkcja random, której używam w linijce 16. przyjmuje jeden argument, który stanowić ma górne ograniczenie dla zwracanych liczb.

Należało tutaj zwrócić uwagę, że liczba podana w argumencie sama nigdy nie zostanie wylosowana. Największą możliwą liczbą do wylosowania będzie natomiast liczba o jeden mniejsza. Innymi słowy, random(100), może zwracać wartości od 0 do 99, a random(50) od 0 do 49.
Wartość 49, była mi potrzebna, więc wydawało mi się, że jednym wyjściem było podanie zakresu górnego jako 50. Ciekawe jest to, że zorientowałem się, jakie skutki to ze sobą będzie niosło. Tym sposobem mogłem w którymś losowaniu otrzymać liczbę 0. W Dużym Lotku taka liczba była nielegalna. By ustrzec się tej liczby, w liniach 17. i 18. pojawiał się zapis tab[i]==0 mający wykryć jej wylosowanie i mający zmusić cały mechanizm do powtórnego losowania i-tej liczby.
Pętla while zaczynająca się w linii 17. służy temu, by nie dopuścić do sytuacji w której w jednym losowaniu wybrano dwie takie same liczby. Losując i-tą liczbę sprawdzałem, czy wszystkie poprzednie (wskazywane indeksem za pomocą zmiennej j) są różne. Jeżeli, któraś z liczb się powtórzyła, mechanizm miał wylosować i-tą liczbę ponownie. Właśnie po to w linii 19. było i--, by niejako zredukować skutki inkrementacji z linii 22, która zwiększając zmienną i miała gwarantować przechodzenie do losowania kolejnej liczby.
Co tutaj jest zbędnego? Parę rzeczy, jednak chciałbym się skupić na jednej. By uchronić się przed wylosowaniem zera, pracowicie po każdym losowaniu sprawdzałem, czy to zero nie wystąpiło. W tym przypadku wylosowanie zera było dość mało prawdopodobne (2%), jednak program pomimo tego musiał tak pracowicie to sprawdzać.
Mam pytanie, czy uważasz, że gdybyśmy mieli w innym programie za zadanie losować parzyste liczby z zakresu 0-99, to dobrym pomysłem było by każdorazowe sprawdzanie, czy liczba jest nieparzysta i jeżeli tak, to powtórzenie losowania? Prawdopodobieństwo tego, że każde losowanie miało by być powtórzone wynosiło by wówczas 50%. Innymi słowy, losując 1 000 000 liczb parzystych musielibyśmy wykonać ok. 1 500 000, z czego pół miliona było by zupełnie niepotrzebne! O wiele lepszym rozwiązaniem było by coś takiego:
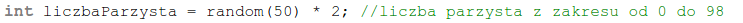
Mam nadzieję, że zaczyna coś u Ciebie świtać :) Losując liczby, nie powinniśmy myśleć o ich konkretnych wartościach, lecz o szerokości przedziału jaki potrzebujemy. W przypadku losowań liczb parzystych ten przedział został rozszerzony. W przypadku losowania liczb Dużego Lotka ten przedział możemy natomiast przesunąć:
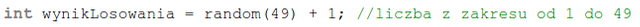
Gdy już człowiek przywyknie do takich operacji, okazuje się że losowanie z dowolnego zakresu nie jest już żadnym problemem.
Podsumowanie
Program miał bardzo dużo błędów, jednak spoglądając na to wszystko nawet teraz jestem z niego dumny. Popełnianie błędów to naturalny proces uczenia się. Najlepszą strategią jest oczywiście uczenie się na cudzych błędach, dlatego właśnie dla Was udostępniam swoje powyższe opracowanie. Jeżeli jesteś początkującym programistą, nie zrażaj się trudnościami przy tworzeniu swoich pierwszych programów. Na początku zawsze jest najtrudniej!
Bonus
Tak wyglądał ten kod w środowisku w którym powstał:
I jeszcze jeden:
Wszystkie kody źródłowe moich starych programów, są obecnie dostępne w serwisie github: https://github.com/noisy/MyFirstProgramsFrom2003 - można poczytać i się trochę pośmiać :)
Sam programuje od paru lat i ciagle czasami wychodzi spagetti :(
Fajny post, żałuję że ja nie zachowałem swojego kodu...
Ale 'w obecnych czasach' wiele błędów które wymieniłeś, niweluje Python ze swoim couplowaniem wcięć ze scopem, dlatego na sam początek wolę polecić go uczniom ponad CPP. Składnia jest o wiele czystsza, bardziej przejrzystrza i zwyczajnie prosta, dzięki czemu świeżak nie musi wielu rzeczy rać 'na wiarę' i nie ma tyle dystrakcji.
Ale kopiowanie przykładów ze stron może być czymś okropnym :D dla tego porzuciłem pythona wiele lat temu na rzecz JS i Node
obecnie najczęściej piszę w pythonie właśnie :)
Ja moich nie zachowałem, ale w gimnazium napisałem w C++ Borland Builder aplikację, która była zegarem na zaliczenie informatyki na 6. W kodzie był też pewien smaczek bo miałem tam wyświetlanie kto ma imieniny tego dnia. Przepisałem z kalendarza dane w formie
if(miesiac==1&&dzien==1){
costam.setText("Jakieś imię/imiona")
} else if(miesiąc==1&&dzien==2) ......
Coś potwornego jak sobie o tym teraz myślę, ale to było 15 albo więcej lat temu i byłem typowym samoukiem bo wiadomo jak wtedy z netem było.
ha aż się łezka kręci jak pisałem na zajęciach program lotto w średniej szkole. Była niezła beka. Ostatecznie pierwsze przeczucie okazało się trafne i programowanie to nie moja bajka :) pascal i c++ hehe
Ale spaghetti xd
Ja pamiętam jak jeszcze w latach 90tych robiłem "programiki/gry" w notatniku do *.bat :D
yhyhy to były czasy :)