3-3 최소제곱법에 의한 AND 로직 머신 러닝 Classification
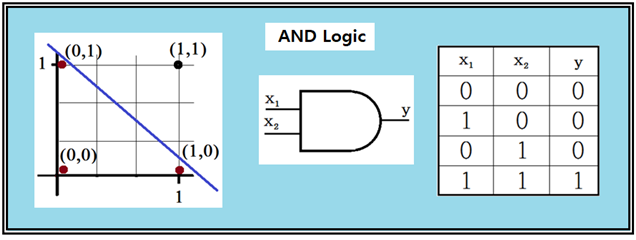
아두이노의 디지털 데이터 핀 또는 라즈베리 파이의 GPIO 디지털 출력은 “LOW”와 “HIGH” 또는 “0” 과 “1” 로 표현이 가능하다. 이러한 논리(LOGIC) 값 출력을 바탕으로 AND 논리(LOGIC)를 고려해 보자.
AND 논리에서 “0”과 “1”을 사용하여 입력 값 x1,x2가 주어지며 이 2개의 입력 값이 항상 “1”이라야만 출력 y가 “1” 이 된다.
그림의 직각 좌표 평면에서 4개의 입력 값이 표현되어 있다. 이 그림에서 출력 라벨 값이 “0”이 되는 3개의 점과 출력 라벨 값이 “1”인 1개의 점은 가로지르는 직선에 의해서 명확하게 선형적으로 분리(linearly separable)가 가능하다.
따라서 이 분리선 왼쪽 영역은 논리 값이 “0”이 되며 그 오른 쪽은 논리 값이 “1”인 영역이 된다.
이러한 분리선을 학습에 의해 찾아낼 수 있도록 다음과 같이 입력벡터 X와 웨이트 백터 W를 정의하자.
X 와 W를 사용하여 다음과 같이 선형의 hypothesis를 설정하자.
hypothesis = XW + b
즉 hypothesis = x1w1 + x2*w2 + b 이 성립한다.
TensorFlow에서 hypothesis를 사용하여 학습을 하기 위한 데이터를 다음과 같이 준비하자. 이 문제는 앞의 골동품 할아버지 시계 문제와 상당히 유사한 형태이지만 출력에 해당하는 입찰 시계 가격이 연속적으로 변화할 수 있는 아날로그 데이타임에 반하여 이 문제는 출력 값이 오직 “0” 과 “1” 인 디지털 문제로 볼 수 있다.
x1_data = [ 0, 1, 0, 1 ]
x2_data = [ 0, 0, 1, 1 ]
y_data = [ 0, 0, 0, 1]
최소제곱법에 의한 cost 함수를 구성하고 경사하강법 적용을 위한 learning_rate 값을 0.005 로 설정한다. 이 값은 여러 번의 학습 시도를 통해 결정이 가능하다. 다음의 계산 결과는 라즈베리 파이 보드에서 파이선 2.7을 사용하여 계산한 결과이다.
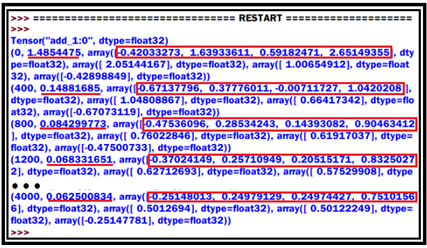
cost 함수는 1.48에서 시작하여 4000번 학습 후 0.06 수준에 도달했다. 한편 출력 데이터 값 [ 0, 0, 0, 1 ] 에 대한 실제 계산 값은 [-0.25, 0.25, 0.25, 0.75] 로 주어진다. 이때의 w1,w2 및 b 는 각각 0.5, 0.5 및 –0.25 로 주어진다. 4000회 학습에서 얻어진 결과를 종합하면 아래의 결과가 얻어진다.
hypothesis = x1*w1 + x2*w2 + b = 0.501*x1 + 0.501*x2 – 0.251
이 hypothesis 를 3차원적으로 라즈베리 파이의 매스매티카를 사용하여 플롯해 보자. 3차원 플롯에 의하면 hypothesis는 그림과 같이 기울어진 3차원 면을 나타낸다.
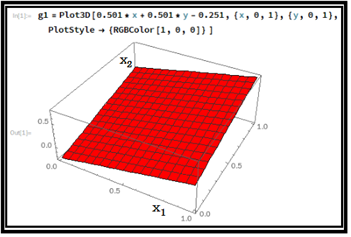
(x1,x2) = (0,0) 데이타를 적용하면
hypothesis = -0.251
(x1,x2) = (0,1) 데이타를 적용하면
hypothesis = 0.25,
(x1,x2) = (1,0) 데이타를 적용하면 hypothesis = 0.25,
(x1,x2) = (1,1) 데이타를 적용하면 hypothesis = 0.752 가 된다.,
아울러 hypothesis 방향으로 즉 높이 방향으로 0.251이 되는 초록색 평면을 설정하자.
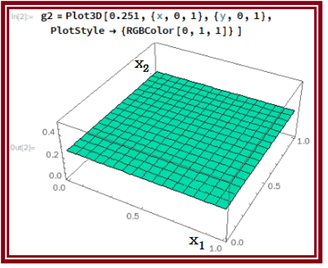
hypothesis 와 이 면을 겹쳐 보도록 하자.
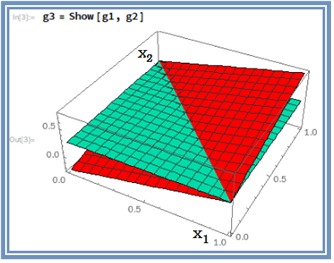
왼쪽의 삼각형 초록색 면을 x1,x2 평면에 투영하면 3개의 데이터 (0,0),(1,0) 및 (0,1) 이 포함됨을 알 수 있다. 반면에 (1,1)은 반대쪽에 위치하게 된다.
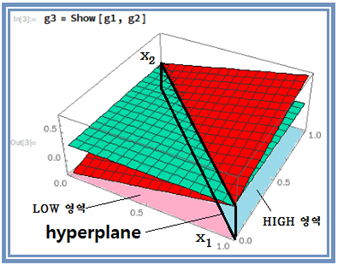
“0”의 영역과 “1”의 영역을 분리하기 위해서는 높이 방향에서 보았을 때에 3개의 점 (0,0),(1,0) 및 (0,1)을 포함하도록 그림의 검은색 사각형 면 즉 hyperplane에 의해 분리된다.
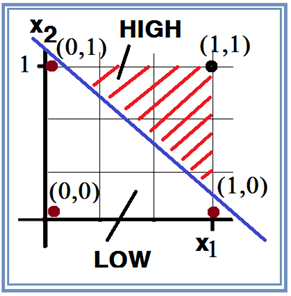
머신 러닝 계산에 의해 결정되는 hypothesis는 단지 x1,x2 평면 관점에서만 직선으로 파악되지만 가시화해서 보면 3차원 그래프이다. 그리고 hypothesis 로 계산한 값이 0.25 이상이라면 HIGH 로 분리 가능하며 반면에 0,25 이하에서는 LOW로 보아도 무방할 것이다. 이 점은 앞으로 흔히 사용하게 될 퍼셉트론에서의 Sigmoid 함수 사용과 더불어 hypothesis 계산치 기준 threshold 0.5 로 HIGH 와 LOW를 분리하게 됨에 유의하자.
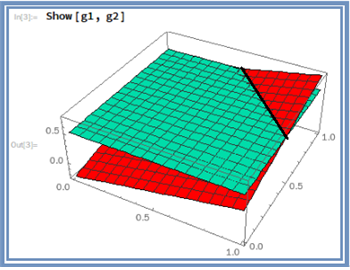
만약 hypothesis의 threshold 값을 0.25에서 0.5로 설정했을 때의 위 그림을 관찰해 보면 x1,x2평면 관점에서 생각하는 분리선이 hypothesis threshold 값이 0.25 일 때와 비교해 3차원적으로 보면 많이 달라져 버렸음을 쉽게 알 수 있다.
Sigmoid 함수 사용 시에 Classification 작업을 위해 사용하는 hypothesis의 threshold 값 0.5도 Sigmoid 함수를 사용하지 않는 경우에는 유의할 필요가 있다.
첨부된 파이선 코드를 실행해 보자. 단 session = tf.Session() 이하 영역에서 indentation 이 무너진 부분을 반드시 복구하여 실행하기 바란다.
#multi_variable_linear_regression_AND.py
#Multi-variable linear regression AND
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
x1_data = [0., 1., 0., 1.]
x2_data = [0., 0., 1., 1.]
y_data = [0., 0., 0., 1.]
#placeholders for a tensor that will be always fed.
x1 = tf.placeholder(tf.float32)
x2 = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
w1 = tf.Variable(tf.random_normal([1]), name='weight1')
w2 = tf.Variable(tf.random_normal([1]), name='weight2')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = x1 * w1 + x2 * w2 + b
print(hypothesis)
#cost/loss function
cost = tf.reduce_mean(tf.square(hypothesis - Y))
Minimize. Need a very small learning rate for this data set
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.005)
train = optimizer.minimize(cost)
#Launch the graph in a session.
sess = tf.Session()
#Initializes global variables in the graph.
sess.run(tf.global_variables_initializer())
for step in range(4001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train],
feed_dict={x1: x1_data, x2: x2_data, Y: y_data})
if step % 400 == 0:
print(step, cost_val, hy_val)
아직 Payout 되지 않은 관련 글
모든 기간 관련 글
인터레스팀(@interesteem)은 AI기반 관심있는 연관글을 자동으로 추천해 주는 서비스입니다.
#interesteem 태그를 달고 글을 써주세요!
이오스 계정이 없다면 마나마인에서 만든 계정생성툴을 사용해보는건 어떨까요?
https://steemit.com/kr/@virus707/2uepul
pairplay 가 kr-dev 컨텐츠를 응원합니다! :)