60s Data Science : Structurez vos projets de Machine Learning avec ASUM-DM

Machine Learning, Recherche et Industrie
[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed.
— Arthur Samuel, 1959
Le Machine Learning (ML) est devenu pratique courante dans tous les domaines en contact avec des bases de données, en particulier dans la recherche et l’industrie. Le ML peut permettre de fournir des réponses aux problèmes :
- de classification (ie. : les vibrations d’un moteur correspondent-elles à un état (i) correct, ou (ii) anormal ?),
- de régression (ie. : quel sera le cours du SNP500 dans 6 heures ?),
- ou encore de clustering (ie. : parmi mes sujets, puis-je déterminer des groupes présentant des caractéristiques d’expertise motrice similaire ?).
Là où une approche computationnelle classique demanderait beaucoup de temps et d’énergie à mettre au point et à optimiser, le ML permet d’impliciter la programmation. L’algorithme apprenant "par lui-même" en fonction des données disponibles, le code est simplifié, sera généralement plus rapide, et une grande partie de l’optimisation sera automatisée.
Il faut noter qu’il est possible de faire du ML sans données, mais cela fera l’objet d’un autre article.
Quand on parle de Machine Learning, les thématiques les plus récurrentes restent le choix du modèle, et l’évaluation de celui-ci. Ces étapes sont nécessaires, mais pas suffisantes pour garantir le succès d’une implémentation dans le monde réel. L’implémentation d’une solution de ML au sein d’une organisation doit respecter plusieurs critères [1].
Minimisation des risques
Selon les champs d’application, cette étape peut s’avérer primordiale. Prenons l’exemple d’un problème de classification pour la prédiction de cancer en Computer Vision. La gestion des types d’erreur est importante. Aucun modèle n’aura une précision atteignant 100%, qu’importe l’algorithme, il provoquera des erreurs de Type I (faux positif), et de Type II (faux négatif).
Dans le cadre de l’imagerie médicale, il pourrait être plus intéressant de pondérer la sensibilité de l’algorithme : les conséquences d’un faux positif sont beaucoup moins importantes qu’un faux négatif, laissant un patient avec une tumeur non-détectée.
Scalabilité
Pour développer un modèle, il est d’usage d’utiliser son propre ordinateur, ou encore des plateformes de Cloud Computing comme IBM Watson Studio, Google Colab, ou Alibaba Cloud. Il faut garder à l’esprit le contexte d’application du Machine Learning. Si la tâche demandée est complexe et qu’un modèle de Deep Learning est requis, à quelle fréquence vais-je devoir le réentraîner pour garder des performances correctes ? L’algorithme est-il optimisé pour le matériel sur lequel il va être exécuté (CPU, GPU, TPU, etc...) ? Il faut garder en tête que la solution restera peut-être effective pendant 5 ou 10 ans. Si la base d’utilisateurs est multipliée par 10 ou 100 en 10 ans, l’algorithme sera-t-il toujours tout aussi efficient et adapté ? Mon matériel (serveur, service cloud) sera-t-il capable de gérer les calculs, stocker les données et résultats sans dégrader les performances de mon service ?
Analytics Solutions Unified Method for Data Mining/Predictive Analysis
Pour optimiser les bénéfices d’une telle implémentation, il convient de mettre en place plusieurs étapes clé [1]. Au sein de toutes les étapes, tous les membres de l’organisation font partie intégrante de la réalisation du projet, même simplement pour apporter l’expertise nécessaire à la compréhension du problème spécifique.
- Comprendre et analyser le problème : définir l’état actuel de la solution de l’organisation, et définir les objectifs de l’implémentation (augmenter le nombre de clients en individualisant les suggestions ?). Il conviendra ensuite de définir les pré-requis de l’implémentation (données utiles et leurs moyens d’obtentions, performances du modèle, etc...),
- Design : définir tous les composants nécessaires à l’implémentation puis commencer à construire le modèle sur la base de données pré-existantes, transformées ou simplement synthétisées pour commencer à évaluer les différentes pistes et leur faisabilité sous forme de prototypes,
- Configurer et Implémenter : sur base des prototypes créés en phase de design, lequel est le plus performant et adapté au problème ? Commence alors la phase d’implémentation en situation réelle. Intérative et incrémentale, cette approche permet de commencer à adapter l’architecture logicielle et matérielle existante pour permettre d’y insérer notre solution. Le modèle, presque fonctionnel, ne requiert plus que quelques ajustements pour arriver en production,
- Déployer : une roadmap est créée. Le modèle est alors déployé et configuré en environnement de production et les deadlines sont fixées quant aux différentes mesures de précision du modèle, le réentraînement de celui-ci ou encore la fréquence de maintenance du matériel utilisé,
- Maintenance et Optimisation : le modèle est complètement opérationnel en production et commence à générer une plus-value (meilleur diagnostique médical, accroissement de revenus, meilleure expérience utilisateur, etc...). La précision du modèle et ses paramètres sont régulièrement vérifiés pour rester cutting-edge.
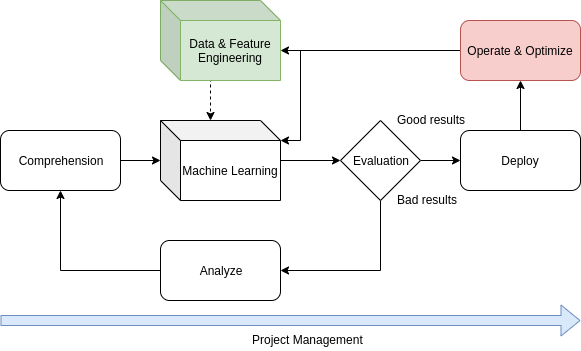
Gestion de Projets en ML, CC BY-SA Clément POIRET.
Pour Aller Plus Loin
A. Géron, “Hands-On Machine Learning With Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems,” 2019.
Références
[1] IBM, “Analytics Solutions Unified Method, Implementations with Agile principles”, n-d.
60s (Data) Science est un nouveau format d'articles ayant pour objectif d'introduire et de présenter rapidement des concepts en Sciences, et Sciences de Données. Tout feedback sera apprécié à sa juste valeur :)

Bannière par @nitesh9 et @rocking-dave
Merci aux communautés #SteemSTEM et #FrancoSTEM pour leur aide et leur soutien ! <3
Congratulations @clement.poiret! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
@clement.poiret, thank you for supporting @steemitboard as a witness.
Click on the badge to view your Board of Honor.
Once again, thanks for your support!
!trdo
Congratulations @cryptoyzzy, you successfuly trended the post shared by @clement.poiret!
@clement.poiret will receive 0.03490088 TRDO & @cryptoyzzy will get 0.02326725 TRDO curation in 3 Days from Post Created Date!
"Call TRDO, Your Comment Worth Something!"
To view or trade TRDO go to steem-engine.com
Join TRDO Discord Channel or Join TRDO Web Site
Congratulations @clement.poiret, your post successfully recieved 0.03490088 TRDO from below listed TRENDO callers:
To view or trade TRDO go to steem-engine.com
Join TRDO Discord Channel or Join TRDO Web Site