리소스 패치 시스템 개발기
서론
지난 3개월동안 다니는 회사에서 리소스 패치 시스템을 개발했다.
기존에는 퍼블리셔가 제공하는 리소스 패치 시스템 등의 인프라를 사용하였지만, 자체 퍼블리싱을 준비함에 따라 직접 만들게 되었다.
모바일 게임을 즐겨보면 알겠지만, 어떤 패치는 앱스토어에서 새로 앱을 다운받을 필요 없이, 로비 화면 등에서 간단한 다운로드를 받고 계속 게임을 진행할 수 있게 한다.
이 때, 필요한 리소스를 다운로드 받고 바로 접속 가능하도록 하는 것이 리소스 패치 시스템이다. 이러한 리소스의 예로는 이미지, 게임 수치 데이터 등이 포함된다.
원래는 인프라 쪽 관련 일은 하지 않았지만, 정말 갑작스럽게 일을 맡게 되었다. 스타트업이 뭐 다 그렇다.

자체 퍼블리싱을 하는 것 자체가 급하게 결정되어버렸기 때문에(어떤 분들은 눈치채셨을 수도 있다) 리서치 및 개발하는 시간이 부족했지만, 간단하게나마 그 과정을 공유하고자 한다.
프로젝트 이름
회사 대표 게임이 북유럽 신화를 모티브로 만들어져서, 리소스 패치 시스템의 이름을 Bifrost 라고 명명하였다.
이 프로젝트를 하면서 가장 잘한 일(?) 중 하나이다.
필요한 것
가장 러프하게 생각했을 때, 필요했던 것은 다음과 같다.
리소스 배포
리소스 버전 관리
서버 점검 상태 관리
서버 점검 상태 관리의 경우에는, 현재 따로 점검 서버가 존재하지 않고, 점검 때 텍스트 출력하는 것이 현재 스펙의 전부였기 때문에 같이 관리하기로 결정했다.
리서치
한번도 해본 적 없던 일이고, 시간과 인력도 그리 많지 않았기 때문에 먼저 다른 갓갓 선구자들이 해놓은 일들을 조사하기로 했다.
다행히 데브시즈터즈에서 Pycon 2015 때 발표한 자료가 있어 많은 도움이 되었다. (사랑해요 뎁시)

결국 데브시스터즈 발표자료의 핵심내용을 정리하자면 다음과 같았다.
git 으로 버전 관리 (libgit2)
AWS s3 + CloudFront 사용 (boto3)
Python 사용
그리고 위 내용들에 대해 하나씩 검토하기 시작했다.
AWS CloudFront
당연히 사용해야 했다.
글로벌 서비스를 하고 있었기 때문에 CDN 을 쓰지 않는다는 것은 불가능했고, AWS 외의 다른 선택권이 사실상 없었다.
git 으로 버전 관리
기존에 사용하고 있던 리소스 패치 시스템에서는 자체적인 버전 관리 기능을 사용하고 있지 않고, 그저 필요한 파일을 zip 으로 묶어 올리면 끝이었다.
퍼블리셔의 경우에는 여러 개발사의 케이스를 고려해야 하기 때문에 최소한의 dependency 만 가지고 가고 싶어서 그렇게 결정한 것 같으나, 나같은 개발사의 입장에서는 버전 관리를 위한 불필요한 tool 의 사용만 증가될 뿐이었다.
따라서, 쉽고(정확히 말하자면 learning curve 가 그리 크지 않고) 간단한 버전 관리를 할 필요성이 있었다.
이미지 등의 binary 파일에 git으로 버전 관리를 하는 것이 100% 좋다고 볼 수 없지만, 개발 기간을 생각한 적절한 trade-off 였다고 생각한다.
그래서 버전 관리는 git 으로 하고, git 의 tag 를 통해 snapshot 을 남기고 관리하는 것으로 결정하였다.
Python 사용
데브시스터즈가 한 것과 비슷하게 Python (+ Django) 를 쓰기로 결정하였다. 이유는 다음과 같다.
Python 의 생산성
AWS api 사용성 (boto3)
Django + ORM 사용으로 인한 웹 사이트 구현 생산성 + DB 신경 덜 써도 됨
개발 기간이 짧은데다 time critical 한 데드라인인 점, 그리고 최종 결과물을 제외하고는 내부에서 쓰는 툴이기 때문에 성능보다는 개발 생산성에 포커스를 맞춰 고민했다.
일단 생각한 Tech Stack
그래서 기본적으로 결정된 tech stack 은 다음과 같다.
Python + Django
boto3 (AWS S3 + CloudFront)
libgit2 (Python 으로 binding 한 pygit2)
배포도 관리하기 쉽게 Elastic Beanstalk 으로 하기로 했다.
기술적 고려사항
이 일을 하면서 여러 기술적 고려사항들이 있었다.
웹 서비스로 구현, 있는 것은 최대한 활용
내부에서 쓰는 툴이면서도, 기획 및 아트팀이 잘 써야 하므로 웹 서비스로 구현하는 것이 적절하다고 생각했다.
또한 리소스 자체를 확인하고 업데이트 하는 건 소스트리를 이용하여 볼 수 있도록 했다. git UI까지 구현할 시간은 없었고, 구현한다고 해도 기존 UI 툴보다 잘할 수 없을 것 같았다.
클라이언트 중심 로직 구현
기존의 패치 서버의 경우 아래와 같은 로직으로 이루어져 있었다.
클라이언트에서 리전별 엔드포인트에 API CALL -> 패치 유무 확인 -> 패치를 해야 할 경우 해당하는 파일 주소 서버 측에서 계산하여 전송
하지만 우리는 게임 클라이언트가 접속하는 패치용 서버를 띄우지 않기로 결정했다.
리전별 패치 서버를 관리할 인원과 자금이 부족했고(리전별로 띄우지 않으면 해당 서버가 병목 지점이 될 가능성이 높았다), 동적 패키징을 하지 않는 한 크게 효율이 증대되지도 않았다.
그러나 클라이언트에서 리소스 패키징 등을 제대로 하지 않은 상태여서 동적 패키징이 힘들었다.
따라서, 다음과 같은 클라이언트 중심 로직으로 개편했다.
클라이언트에서 특정 static file 다운로드 -> 패치 유무 확인 -> 클라이언트에서 필요한 리소스를 규칙에 따라 알아서 확인 -> 다운로드
이 선택은 제일 중요한 선택 중 하나였지만, 제일 아쉬웠던 선택이기도 했다.
서비스가 더 잘되어서 패치 시간을 단축시키는 것이 정말 중요한 이슈였다면 더 잘할 수 있었을 것 같다.
Live QA 기능
기존 시스템에서 사용하던 기능 중, 라이브 서버에 whitelisted 된 IP 만 패치할 리소스를 미리 다운로드 받게 하는 기능이 있었다.
서버에서 리소스를 내려 줄 경우에는 IP를 보고 판단할 수 있으므로 그리 어려운 이슈는 아니었지만, 클라이언트 중심 로직으로 바뀌게 되면서 이러한 경우를 어떤 식으로 처리할지 곤란했다.
AWS Lambda@Edge 가 날 구원해주었다. AWS Lambda 를 이용하여 cloudFront Edge 에 사용자 요청이 올 때, 내부 IP 의 경우에는 다른 static file 의 주소로 리다이렉션을 시켜줘서 해당 스펙을 똑같이 쓸 수 있었다.
Celery 도입
웹 기반 시스템으로 만들었기 때문에 AWS 와 연관된 long-time task 를 처리하는 것이 굉장히 힘든 일 중 하나였다.
특히 cloudFront 에 배포되는 static file 을 invalidation 을 해야 최신 파일이 각 엣지에 캐싱되게 되는데, 이 과정에 많은 시간이 걸렸다.
그래서 Celery 를 도입해서 백그라운드에서 처리하도록 구현했다. 사실 distribution 이 필요없는 상황이므로 Celery 까지 필요없는 일이었지만, Background Job 관련 내용을 blackbox 로 두고 처리할 수 있었으므로 도입했다.
Elastic Beanstalk 배포
Elastic Beanstalk 의 경우, 일단 설정이 되면 배포는 너무 쉬웠지만, 배포 스크립트를 만드는 과정이 상당히 고통스러웠다.
일단 기본적으로 libgit2는 yum 을 이용해서 install 하지 못했고, Celery 를 daemonize 해서 돌려야 했었고, 로그도 따로 남겨야 했었다.
또한, git pull 을 받아서 배포를 하다 보니 instance 를 띄울 때마다 EBS를 mount 시켜야 하는 스크립트도 짜야 했었다.
물론, 다 하고 나니 너무 편하고 좋았다.
그래서 최종 tech stack
Python + Django
boto3 (AWS S3 + CloudFront + Lambda@Edge)
libgit2 (Python 으로 binding 한 pygit2)
GitLab (Git 서버 용으로 기존 사용하고 있던 Gitlab 사용)
Celery (long-time task 를 위해) + Redis (broker 로 씀)
Mysql (최소한의 Persistent Data는 당연히 필요한 거니까)
Elastic Beanstalk
Front-end 는 bootstrap 으로 비개발자들이 잘 사용할 UI를 만들었다.
로 리소스 패치 시스템을 개발했다. 전체적인 workflow 는 다음과 같다.
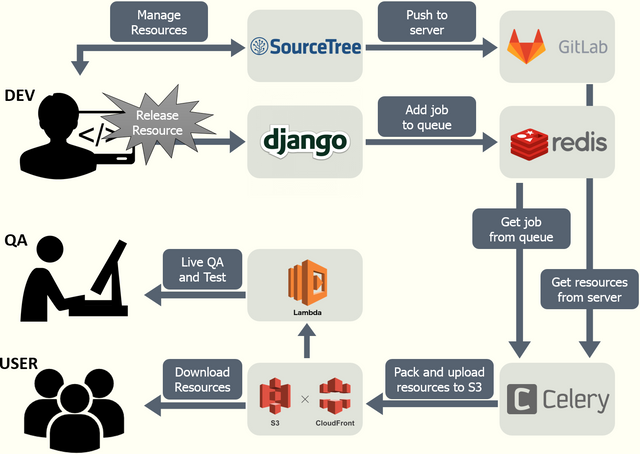
후기들
사실 초반에는 되게 힘들었다. 빨리 개발을 해야 했지만, 스펙도 명확히 주어지지 않은 일을 혼자서 해야 하는 상황이었다.
다행히 기존 사용하던 시스템 + 데브시스터즈의 발표자료를 레퍼런스 삼아 그렇게 많이 방향을 우회하지 않고 결정을 내릴 수 있었던 것 같다.
삽질
처음에는 그냥 모든 최신파일을 엣지에 올려놓고, 클라이언트에서 파일별 hash list 를 내려받아 가장 최신값만 가지고 갈 수 있도록 하려고 했다.
그러나 클라이언트에서 패키징이 되어 있지 않은 상황이라 처음 full resource 를 받을 때 http connection 을 15000개 이상 맺어야 했다.
HTTP connection 으로 인한 overhead 를 처음에 고려하지 못하는 큰 실수를 해서 중간에 선회를 하기도 했다.
이번 프로젝트를 진행하면서 한 가장 큰 실수인 것 같다.
EFS
git pull 을 해야 하기 때문에, 인스턴스에서 로컬 스토리지를 쓸 수밖에 없었다.
그러나 Beanstalk 으로 배포하는 현재 시스템에서는 scale up 만 가능하지 scale out 은 가능하지 않다. (Beanstalk 으로 배포를 했지만 인스턴스 제한을 1개로 걸어놓았다...)
AWS EFS 를 사용하면 network file system 을 사용해 multi instance 에서 접근이 가능하므로 scale out 이 가능해진다.
안타깝게도 서울 리전에는 EFS 가 아직 없어서 쓰지 못했다. 나중에 서울 리전에 EFS 가 출시되면 업그레이드 할 계획
Python
이전까지는 Python 을 제대로 쓰지 않았는데, 파이썬을 제대로 써볼 수 있었던 기회였던 것 같다.
아주 매력적인 언어인 것 같고, C base 라는 점도 마음에 들었다. 그리고 다음 Pycon에는 꼭 참가하고 싶다.
블로그 글과 관련하여 질문이 있거나, 틀린 점을 발견했다면 [email protected] 또는 Discord ethanhur#8277 로 연락 부탁합니다. 태클 환영합니다.
스펙이 정확하지 않은 상황에서 스펙 만들어가면서 일하는 것이 힘들죠 ㅠ_ㅠ 고생 많으셨습니다.
개발 관련 태그는 #kr-dev 를 추천드립니다.
명성도(이름 옆의 숫자)가 55였나? 를 넘기 전에는 #kr-newbie 태그도 추천드립니다.
kr-dev 태그가 있는 줄은 몰랐네요. 감사합니다. 앞으로도 자주 글 남길 수 있었으면 좋겠네요
네 앞으로 다른 글도 기다리겠습니다 :)
잘봤습니다~ 고생이 여기까지 느껴지는듯 합니다.
좋게 봐주셔서 감사합니다. 팔로우 했습니다~