Tensorflow入门——处理overfitting的问题
在之前的文章中,我们发现训练组(篮)和验证组(红)的损失函数在20个Epoch之后,向着相反方向变化。训练组损失函数继续下降,验证组损失函数反而在上升,这就是典型的Overfitting(过拟合)现象。
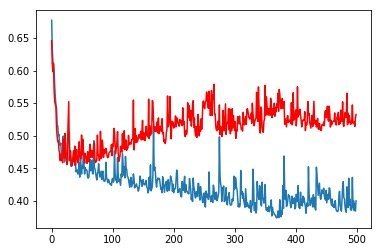
过拟合就是模型过度地学习了训练集的特征,反而没法处理测试集中更一般化的问题。处理过拟合最根本的解决方法当然是获得更多的训练样本。
但是在无法获得更多的训练样本的时候,也有两个最简单的方法,一是对权重进行正则化处理,二就对神经元随机dropout.
关于更多Keras的入门介绍,感兴趣的朋友可以参考Google的官方教程,更多关于过拟合和欠拟合的相关资料请参考这里
在Keras中我们只需要对模型进行简单改造就能实现正则化和dropout,同样的,为了方便与读者交流,所有的代码都放在了这里:
https://github.com/zht007/tensorflow-practice
L1,L2正则化
模型Overfiting其中一个原因就是某些权重在训练的过程中会被放大,L1正则化相当于给权重加了惩罚因子,从而限制了某些权重过度膨胀。L2相当于对L1惩罚因子乘了个平方,对权重的膨胀加大了惩罚力度。
在Keras的模型中引入L1,或者L2也非常简单,只需要在建立模型的时候加入:
kernel_regularizer = keras.regularizers.l1
或
kernel_regularizer = keras.regularizers.l2
模型如下所示
model = Sequential()
model.add(Dense(20,input_shape = (X_train.shape[1],),
activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(Dense(20,input_shape = (X_train.shape[1],),
activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(Dense(10,activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(Dense(2, activation = 'softmax'))
Dropout
在需要Dropout的Dense层之后加上:
model.add(Dense(2, activation = 'softmax'))
最后我们看看加上L2正则化和Dropout之后的模型是怎么样的。
model = Sequential()
model.add(Dense(20,input_shape = (X_train.shape[1],),
activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(keras.layers.Dropout(0.5))
model.add(Dense(20,input_shape = (X_train.shape[1],),
activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(keras.layers.Dropout(0.5))
model.add(Dense(10,activation = 'relu',
kernel_regularizer = keras.regularizers.l2(0.001)))
model.add(keras.layers.Dropout(0.5))
model.add(Dense(2, activation = 'softmax'))
model.summary()
Model.summary可以查看整个模型的架构和参数的个数
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 20) 180
_________________________________________________________________
dropout_7 (Dropout) (None, 20) 0
_________________________________________________________________
dense_20 (Dense) (None, 20) 420
_________________________________________________________________
dropout_8 (Dropout) (None, 20) 0
_________________________________________________________________
dense_21 (Dense) (None, 10) 210
_________________________________________________________________
dropout_9 (Dropout) (None, 10) 0
_________________________________________________________________
dense_22 (Dense) (None, 2) 22
=================================================================
Total params: 832
Trainable params: 832
Non-trainable params: 0
_________________________________________________________________
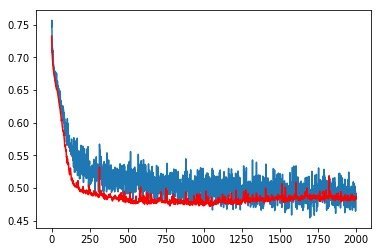
训练结果
最后我们看看正则化和Dropout后端的训练结果吧,是不是比之前漂亮多了。
参考资料和数据来源
https://www.kaggle.com/uciml/pima-indians-diabetes-database
https://www.tensorflow.org/tutorials/
https://en.wikipedia.org/wiki/Overfitting
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
提一些建议哦:
谢谢建议,
2.公开数据的来源在源代码中已经做了说明,接受建议,在文末添加了。
哈哈,不客气,我只是从写此类分享文章的角度提一下自己的看法。😀
Steemit代码展示我也有些不了解,晚些看到方法我分享一下😛
你有加入新手村吗?可以联系一下村长 @ericet 他的微信也是ericet
帅哥/美女!想要参加活动但是不知道从何开始?关注寻宝团@cn-activity每日整理社区活动!倘若你想让我隐形,请回复“取消”。
结尾漏了同步到你的简书。。。
哈哈 谢谢提醒
Posted using Partiko iOS