All you plagiarism would be found in few seconds! Briefly about how plagiarism detector works
Today, information is becoming more and more important resource: so most people think about the quality of this resource. How to check it?

The problem of the uniqueness of information is becoming more serious because of the development of the Internet: the number of websites is growing exponentially, and the technical solutions for the determination of authorship do not exist. Modern detectors of plagiarism check fragments, paragraphs, and small sections of text searching for matches of sequences of words in the document and compare them with those that are in the search engine index, finding non-unique sentences.
There are the following signs of plagiarism - a person engaged in plagiarism, if:
- person quotes or paraphrases another's statements without proper references;
- a person publishes other people's ideas without giving a source.
And now let's get acquainted with the exemplary principle of work of any plagiarism detector.
The first stage of the analysis relates to the grammatical structure of the input file. Parsing is carried out by using a probabilistic speech packet of part of speech recognition. It marks each word in the file as a part of speech ( adjective, noun, pronoun). This helps to eliminate some of the words from the further search and identify variations of time, voice and person.
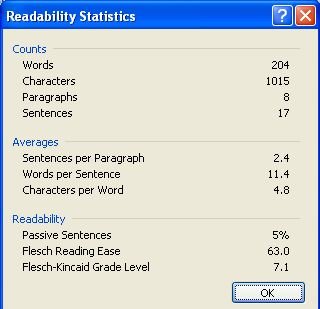
Furthermore, readability of the document is estimated with the help of the Flesch method. Flesch ease reading index and education index of Flesch-Kincaid Grade Level are calculated for each paragraph and for the document as a whole. It's a well-known readability measure based on the calculation of the average number of words per sentence and the average number of syllables per word. They are used as indicators of the potential involvement of several authors in the writing of the text based on the assumption that the indexes of the text, written by one person, can’t change much from section to section or from paragraph to paragraph.
Analysis of variance paragraph indexes in relation to the average value is made for the entire document and it can identify places with potential plagiarism, which are then retrieved by the search on the Internet.
The detector uses different searching engines, for example, Google. To do this it uses the SOAP protocol of the Google Web API Web service.
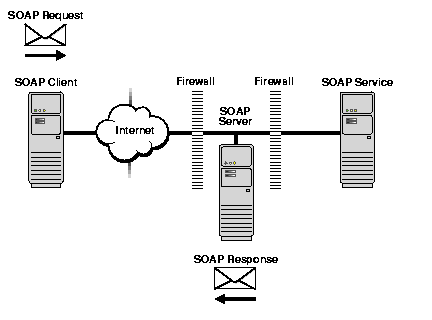
Fragments of text, which were identified as potential "hot spots" are converted into samples for research. The transformation is carried out in two ways: a search for exact matches of sentence fragments (Google limits the length of a fragment with ten words) and contextual matching of keywords (which are defined by parts of speech recognizer).
The user can configure the detector so as to use only one of these methods, or to leave the default mode in which contextual search is performed only when the results of exact matches are below a predetermined point.
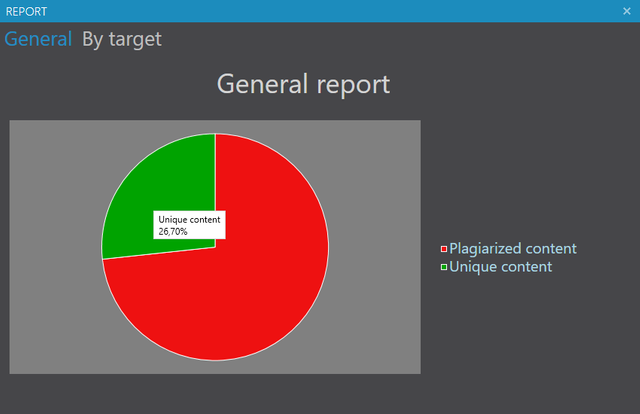
The detector scans returned a list of links from Google to remove unnecessary and duplicated URLs and identify the most obvious matches in each piece of text, and in the whole input file. During the calculation, the index of plagiarism document takes the number and degree of coincidence of found texts, the standard deviation of the Flesch index and results of grammatical analysis into account. Plagiarism index is set in a range from one to five, and the reports are indicated with the mark on the five-color scale - from green "completely innocent" to red for "very guilty".
Like any other similar tool, detectors of plagiarism - are just machines, so they also make mistakes. Thus, they are virtually useless without Homo sapiens. Software that can detect plagiarism, need a good partner, so, in the end, to correctly analyze the text and draw some conclusions about its future use.
Follow me, to be the first to learn about my publications devoted to popular science and educational topics
With Love,
Kate
what ever happened to the Cheetah bot? She did a great job here i thought in this domain !!
Now that you mention it... where is that bot?
I think that it still works. You may ask @anyx about this bot
Trumps wife could've used some of those tips! It is a good thing to protect people's original ideas. Kudos on the article.
Funny, I was just looking up for one. It would be nice to have something like this imbedded in Steemit.
Good idea. Actually there was a bot with embedded anti-plagiarism API, that checked every post and if there was any plagiarism it notified readers in comments.
I'm no plagiarism detector, but I think a lot of it has made a bunch of money here on Steemit. Ooops, Steemstats just notified me of one that probably is plagiarism, better go check it out :)
oh, really. How does steemstats notify? Haven't ever seen this functionality there
It doesn't notify plagiarism. I can see where my comment might have been confusing. When I was writing my original comment, Steemstats notified that someone I follow and think might be plagiarizing, just posted something.
okay, got it
Would it be usable for other languages too?
of course, the basis is the same. But it also depends on language structure, as e.g. Russian and Chinese is much more complicated than English, that's why algorithm requires some modifications for each specific language
Valuable information, thanks so much. If anyone's bothered would be cool to check my profile for some Steemit wallpapers :)
I'm researching for an article, and certain facts need to be taken from Wikipedia, if I cite the sources, is that plagiarism?
of course not. If you cited then it's okay. But obviously, you shouldn't copy-paste the entire article. e.g. It's okay if you quote some definition and add your own comments to it
Cool, thanks!
very good article