How to Put the World’s Data on the Blockchain

The wealth of data available today is immense. In 2017, The Economist reported that data passed oil as our world’s most valuable commodity. Data is the fuel that powers advanced digital applications — applications that impact our daily lives, that have transformed shopping, entertainment, social media, and automation. Tapping into this data will be critical for decentralized tech if it hopes to serve any significant role in our ever more data-centered future.
In the real world, we play fantasy sports, assigning digital value to the outcomes of real sports games. We trade financial instruments built on the future prices of oil or corn. We have insurance markets that protect against storms and other natural disasters. All these applications depend on data that lives outside of the blockchain.
For decentralized technologies to reach their full potential, they need reliable outside data. Getting truthful real-world data into the blockchain is tricky. It is the job of blockchain oracles to implement mechanisms so that smart contracts can use reliable data to settle transactions.
Blockchain oracles
There are two major classes of blockchain oracles. Game Theoretic Decentralized Oracles ask for a number of participants to report what happened in the world outside the blockchain. Naturally, it is vital for this type of oracle to disincentivize bad actors through a reputation or compensation mechanism. In other words, honesty must be rewarded and/or deceit punished.
One way of implementing Game Theoretic Decentralized Oracles is to allow people with quantifiable reputation or system tokens to vote on outside events by staking those tokens. In the end, some combination of the votes, weighed by stakes, is taken to be the truth. The reason this works in principle is that, when a number of voters don’t know how others will vote, they tend to report the truth. This is because the shared knowledge about reality is the most obvious candidate they can expect each other to vote for. This guessed point of convergence is known as the Schelling Point. TruthCoin and SchellingCoin are examples of oracle systems based on variants of this principle.
This appears simple in theory, but there are several complications. First of all, it is difficult to establish how well these mechanisms resist attempts at distorting results through Sybil attacks or by bribing voters.
There’s another problem: if voters can choose among multiple markets or contracts, they will tend to stake all their tokens on easier and safer votes. They will only vote for things of which they are certain of the answer — trivial or non-controversial facts found in the outside world. However, if the tasks involve more effort, such as researching, thinking, or computing, the voter will need to spend more resources while becoming less certain about how others will vote. For instance, most voters would prefer to check a weather website and report whether it rained in some city, whereas they’ll avoid making complex computations and processing a large amount of data. As a result of this, settlements that have low stakes due to poor voter participation are prone to 51% attacks.
Besides using the Schelling Point as a principle, there are other possible algorithms such as the one used in the latest version of Augur. Instead of allowing for many participants to cast votes, the prediction markets have a single designated reporting party, whose vote can be disputed later on by other parties. This algorithm isn’t free from pitfalls. For instance, a malicious losing party might threaten to initiate a dispute in order to delay the release of the funds to the honest participants. That would be a way to extort money from the victim, who might feel compelled to pay the attacker in order to avoid delays and their incurred costs.
In defense of the game-theoretic approach, voters generally behave more honestly the more assertions they make and the more reputation they accrue. Then again, these oracles are dealing with externalities. It’s possible that what bad actors will lose by cheating the system (meaning reputation or tokens) is less significant than what they stand to profit in terms of real world value. Since everything is anonymous, what is lost is necessarily contained and limited within the system, whereas what is won may be virtually unlimited, because it relates to the external world.
The second major class of oracles is normally referred to as Mechanical Oracles. With mechanical oracles, blockchains rely on a source of information that can be found somewhere else on the Internet. The oracle provides a way to extract that data as safely as possible from web pages, service API’s, or files made available by third-party sources (e.g. Provable, Chainlink).
Obviously, we could argue that even if the external source is reliable, a transport layer between the source and the blockchain adds a vulnerable link to the chain.
With mechanical oracles, the transport layer often relies on the infrastructure of reputable, albeit centralized, service providers (such as AWS) or hardware manufacturers (such as Intel). This adds an element of centralization to the mix. In fact, describing an application as decentralized becomes a hard sell when it relies on centralized components that copy external data to the blockchain.
Last but not least, since the incentive mechanism of the oracle is in itself decoupled from the financial instruments that use it, both game theoretic and mechanical oracles tend to get less secure as the stakes involved in the contract increase. For example, when some party expects to win or lose $1M USD depending on what the oracle reports, there may be a large incentive for them to hack the mechanical oracle or bribe voters in a decentralized oracle.
Let’s consider a different approach for oracles. Suppose that people can choose among different providers as part of a feeds marketplace that rates providers according to the reputation and availability of their services. Providers would necessarily be transparent and would disclose their personnel and business names, perhaps even accepting some legal liability for misconduct or mistakes. Additionally, the data providers could have a third-party custodian maintain a substantial amount of funds available as reparation to victims of such failures. That would add yet another layer of trust. This idea is not new and a more thorough description can be found in this article by Yotam Gafni.
In the example that follows, we describe a technical solution that follows this approach. The data is provided by a real-world institution that might in the future be tracked by a reputation system. However, the reputation system itself is not the scope of this article. We show how the data can be transported and processed in a safe and decentralized way, assuming the parties involved in the decentralized application are at ease with the reputation of their oracle feeds of choice.
The challenges of transport and processing
Imagine a simple Ethereum-based application in which two users bet on temperature trends for any region in the US relative to some previous year. The details of the application itself are unimportant. Our goal here is to understand the challenges faced by any blockchain application with similar external data requirements.
Suppose our users trust a scientific agency such as NOAA to provide accurate data. If they trust this third party, they will be satisfied if the source and integrity of the data can be verified on-chain. Let’s proceed under this assumption. NOAA’s nClimDiv dataset includes a file (currently 37MB) with sequential climatic county monthly maximum, minimum, and average temperature and precipitation, from 1895 to present, updated monthly. In our ideal world, NOAA signs the checksum of this file, much like Linux distributions sign package checksums to allow downloaders to verify the source and integrity of packages they want to install in their systems.
If we want to bring this data to the blockchain and make it available to smart contracts, we must overcome economic and engineering challenges that are specific to blockchain infrastructures.
The most obvious issue is that directly storing 37MB of data on Ethereum could cost approximately 50K USD (@10 gwei and 208 USD / ETH). If the data was very valuable and widely useful, this cost could be amortized across a consortium of applications. However, these economic requirements make many applications impractical. Perhaps the data should be kept off-chain, on IPFS? But then, how are we going to verify source and integrity on-chain, and indeed use the data afterwards, given that it is not directly accessible to smart contracts?
Now assume the data somehow made it to the blockchain. We still have computational restrictions to overcome. Verifying the checksum signature might be economically viable, but how about computing the checksum itself? And what about processing the data after this verification succeeds? This could cost hundreds of dollars per execution. It may also require an immense amount of complex and expensive Solidity development.
In the off-chain world, any programmer could write a script in a few lines of code that computes the checksum and verifies the signature. It is also trivial to go through the data, aggregate the averages for the region of interest during both periods, and output the trends. Consider writing the same program in Solidity, where even text processing is painful. Along the same line, those 37MB compress down to 5MB using the xz program. Think about how much cheaper it would be to store the compressed data. Off-chain, this would be a no brainer. Now imagine trying to write a decompressor in Solidity and running it inside the blockchain.
We seem to be hitting one obstacle after another. These difficulties stifle innovation. Our example application should be easy to code and cheap to run. In reality, even if we somehow convinced NOAA to provide signed checksums and upload the files to IPFS, we would be unable to implement this concept: direct access to authenticated data with no intermediaries.
The Cartesi way
Traditional blockchains execute tasks in their virtual machines. Unfortunately, these VMs don’t support normal operating system tools and are inefficient and expensive at performing complex computations. This means blockchains aren’t suited for big, complicated tasks. Cartesi Machines provide a secure and reproducible environment that can perform computations within an off-chain emulator. They can indeed run a full Linux distribution, so devs can use all their favorite software stacks and tools.
Let us assume that our DApp has specified a Cartesi Machine that is preloaded with any amount of support software and data in a drive, henceforth called the main drive, including NOAA’s certificate. The region and period of interest are placed in an input drive, while the dataset drive contains the NOAA’s nClimDiv dataset, and checksum drive has the signed checksum. When booted, this machine can execute a script under Linux from the main drive. This script can recompute the dataset checksum using the contents of the dataset drive, and then verify that it matches the signed checksum in checksum drive using the certificate in the main drive.
From then on, it knows the data came from NOAA and has not been tampered with. It can now proceed to load the region and period from the input drive and calculate the desired trend from the dataset in the dataset drive. Once this computation is complete, it can save the results in the output drive. If any of the checks fail, it can simply report the error in the output drive itself. Even a new programmer could create such a script.
Although Cartesi Machines are executed off-chain, they have a variety of “magical” properties that allow them to be used with blockchains. First, they can be quickly specified in a smart contract. The entire state of a Cartesi Machine, including all drives, is given by a single Merkle tree root hash. Each drive is a node in this tree, and therefore is also fully specified by the root hash of the Merkle tree of its contents. A smart contract can quickly take the root hash for a previously defined Cartesi Machine and replace one of its drives with another. All it needs is the root Merkle tree hash for the new drive.
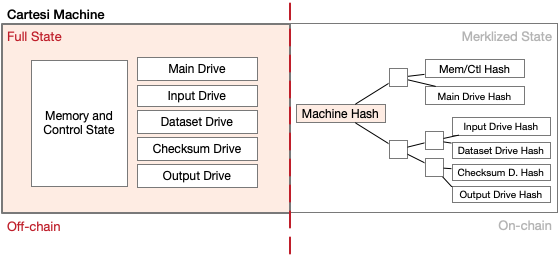
On-chain and off-chain representations of the Cartesi Machine
Another property of Cartesi Machines is that if two contestants, say Alice and Bob, run the same Cartesi Machine from start to finish, they will obtain halted Cartesi Machines with matching final state hashes, every time. Moreover, if Alice cheats and reports an incorrect final hash, Bob can challenge Alice’s results and successfully prove to the blockchain that Alice was dishonest. The blockchain doesn’t need to see the entire computation, only a negligible part. Finally, given an undisputed final state hash, Alice and Bob can quickly prove to the blockchain that any part of the state contains a given value.
Here is how all this machinery can be put in place to solve our oracle problem. The DApp predefines the Cartesi Machine with input and dataset drives, which are initially empty. These are the drives that will hold the region and period of interest and NOAA’s nClimDiv dataset, respectively. The contents of the input drive are small enough that the DApp’s smart contract itself can fill out its contents, compute its Merkle tree root hash, and replace it in the Cartesi Machine. When Alice and Bob agree on a bet, the DApp can perform these tasks on-chain. Then, when the time comes and, say, Alice, wants to claim victory, she goes to NOAA’s website and obtains the updated Merkle tree root hash for the nClimDiv dataset and its signature. Alice provides these to the DApp, so it can use them to replace the dataset and checksum drives in the Cartesi Machine. Finally, Alice runs the resulting machine off-chain and posts its final state hash and proof that the results in the output drive were in her favor. If she was honest, she will be able to defend against any of Bob’s disputes. If she was cheating, it is Bob that will be able to expose her.
Consider the properties of this solution. The blockchain does not see any of the 37MB in the dataset. Likewise, it does not perform any of the processing involved in it. There is no way Alice or Bob could misrepresent the dataset, unless they forge NOAA’s signature. In fact, there is no way even for NOAA to claim it was not the original source of the data. Since the data is widely available, either directly from NOAA or perhaps from IPFS, neither Alice nor Bob can claim not to have access to it. When both Alice and Bob are honest, the entire process takes only a couple of cheap transactions with the blockchain. There is no way Alice or Bob could cheat each other. Now compare this ease with the multiple challenges we faced when trying to develop the solution without Cartesi. It’s night and day.
TLDR:
Here’s how the Cartesi platform provides solutions to the following problems:
- A chain-of-custody for data — as long as data providers create a Merkle tree root hash of the data and sign it, Cartesi-enabled DApps can verify its authenticity.
- A solution for making data accessible to blockchain — as long as data providers guarantee their data is available off-chain, the blockchain only needs to store a hash of the actual data. There’s virtually no limit to the size of the data, as it never has to be stored on the blockchain itself.
- A method for performing computations with that data — Cartesi gives applications the tools for performing complex computations off-chain on data under Linux, in an efficient and reproducible way, with strong dispute resolution guarantees.
Conclusions
We anticipate that as applications demand large and complex data, reputable services will emerge that will host data off-chain together with their signed Merkle tree hashes, so that decentralized applications can make use of them in the fashion we described. In time, the original data providers may themselves offer these signed drives directly.
Cartesi gives applications the tools to conveniently, securely, and scalably transport and process off-chain data. Applications even have the flexibility to draw and combine data from multiple sources if they don’t want to trust a single provider. All parties involved, say in a financial instrument, can dispute the authenticity of the data or the results of its processing.
What is particularly compelling about this approach to oracles is that, since the transport of data is performed by the interested parties themselves, there’s no decoupling between the transport and the underlying financial instrument. In other words, the higher the stakes involved in the smart contract, the more the involved parties will do to ensure the data is rightfully made available to the blockchain.
Cartesi can prove instrumental for any kind of DApp that uses real-world data. The ability for secure, reproducible off-chain computations gives DApps the power they need to use real sources of data without compromising on security or decentralization on the transport of such data. We at Cartesi provide the tools so entrepreneurs and developers can finally create those killer blockchain DApps.
Interested in joining us or learning more?
Website: https://cartesi.io
Telegram Community: https://t.me/cartesiproject
Telegram Announcements: https://t.me/cartesiannouncements
Discord Dev Community: https://discordapp.com/invite/Pt2NrnS
GitHub: https://github.com/cartesi
Social Media:
Twitter: https://twitter.com/cartesiproject
Reddit: https://www.reddit.com/r/cartesi
FaceBook: https://www.facebook.com/cartesiproject
LinkedIn: https://www.linkedin.com/company/cartesiproject/
YouTube: https://www.youtube.com/channel/UCJ2As__5GSeP6yPBGPbzSOw