[논문 소개] Clinically applicable deep learning for diagnosis and referral in retinal disease
- 논문 정보
- 논문 제목: Clinically applicable deep learning for diagnosis and referral in retinal disease
- 논문 링크: https://www.nature.com/articles/s41591-018-0107-6
- 저널 정보: Nature Medicine (2018)
- 블로그 페이지: https://deepmind.com/blog/moorfields-major-milestone/
오늘 소개드릴 논문은 Clinically applicable deep learning for diagnosis and referral in retinal disease(Nature Medicine, https://www.nature.com/articles/s41591-018-0107-6)입니다. Nature Medicine에 실린 논문으로 의료, 특히 안과 계열 진단을 한다고 밝혔던 Deepmind가 "A major milestone for the treatment of eye disease (https://deepmind.com/blog/moorfields-major-milestone/)"이라고 표현한 결과를 정리한 논문입니다. 뭐 요즘 AI라고 하면 NIPS, ICML 같은 학회만 중요하다고 생각하시는 분이 많고 어느 한국의 N-검색회사 면접에서는 조금 벗어난 저널을 썼다고 하면 그런거 가지고 졸업하냐고도 하셨다지만, Nature Medicine은 소위 말하는 IF가 30이 넘는 저널입니다.
제목은 "Clinically applicable deep learning for diagnosis and referral in retinal disease"이라고 되어 있습니다. 결국 deep learning을 적용하여 망막질환을 진단하는 일을 하는데, 이렇게 제목만 보시면 2016년에 구글에서 발표한 "Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs" (https://jamanetwork.com/journals/jama/fullarticle/2588763)을 먼저 생각하실 수 있지만, 일단 그 논문은 Retinal Fundus, 즉 안저 영상을 기반으로 한 방법이고, 이번 논문은 OCT(Optical coherence tomography)를 이용한 논문입니다. OCT는 IVUS(Intravascular ultrasound)와 같이 3D image를 제공해 주는 기술이라고 보시면 되는데, 빛을 이용하다보니 더 선명한 영상을 제공해주나 대신 penetration depth가 낮은 단점을 가지고 있습니다. 많이 쓰이는 영역이 이 논문에서와 같이 망막 질환을 보거나, 혈관을 관찰하여 심혈관 질환을 진단할 때도 쓰입니다. 그럼 다시 제목으로 돌아가면 이 논문은 deep learning을 이용하여 망막 질환을 진단하는데 OCT를 입력으로 받아 망막 질환을 진단합니다. 더 보시면 아시겠지만, 진단 뿐 아니라 얼마나 위급한지도 같이 하죠.
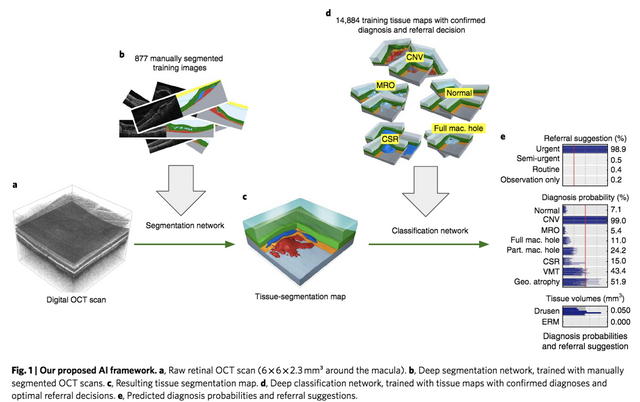
논문에서 나타난 것과 같이 이 논문은 기존 JAMA 논문과는 조금 다른 방법을 제시합니다. 판단의 과정이 2개로 나누어져 있습니다. 1. Segmentation network, 2. Classification network으로 나누어져 OCT 영상이 입력되면 일단 Segmentation network이 Tissue-segmentation map을 제공하고, 이를 기반으로 Classification network으로 어떤 병인지, 얼마나 위급한지, 그리고 특정 Tissue volume을 제공합니다.
일단 이렇게 두가지 스텝으로 나누면서 여러 장점을 얻습니다. 보통 저렇게 feature extraction 파트와 classification 파트로 나누는 경우 장점은 feature라는 중간 단계 결과를 볼 수 있다는 점과 만약 그 feature라는 중간 단계가 interpretable하다면 domain전문가들에게 feature라는 형태로 정보가 전달되어 Black box problem(Deep learning 어떻게 되는지 모르겠다~~는 문제)을 어느 정도 줄일 수 있다는 장점이 생깁니다. 이 논문의 방법에서도 이미 알려진 tissue단위로 segmentation을 하여 그 segmentation map을 제공함으로써 그런 장점을 얻었습니다.
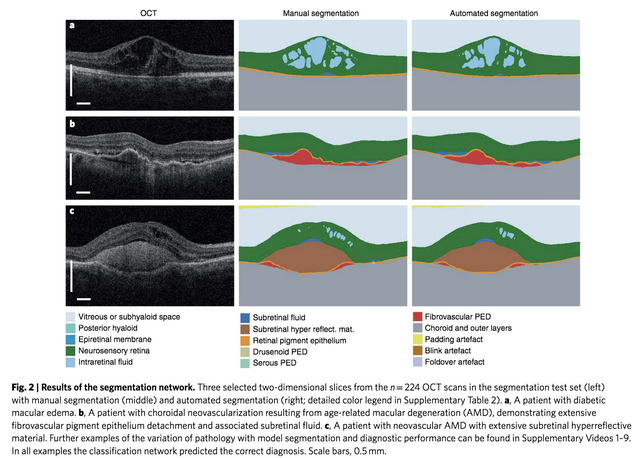
또 하나의 장점은 Generalization 과정에서 2번 classifcation 과정을 독립시킬 수 있습니다. 무슨 말이냐면, 이 논문에서 사용된 기계는 두가지 타입입니다. 하나의 타입에서 나온 데이터로 학습시키면 다른 타입의 기계에서 나온 데이터에서 잘 동작을 안 합니다. 그런데, 이 때 동작을 안 하는 원인은 타입이 달라져서 interpretable 특징을 가지고 있는 segmentation map 자체가 망가지는 것이지 classification network은 문제가 없다는 말입니다. 그래서 새로운 기기에 적용할 때는 전체 데이터가 아니라 segmentation을 위한 데이터만 다시 준비해서 그 부분만 다시 학습을 진행하여 고쳐주면 잘 동작한다라는 결과를 보여줍니다. 뭐 이 정도도 문제라고 보실 분은 많지만, Generalization을 제공하기 위한 데이터 준비의 과정을 줄일 수 있다라는 점이 있습니다. 그리고 interpretable 특징이 증명된 면도 있고요.
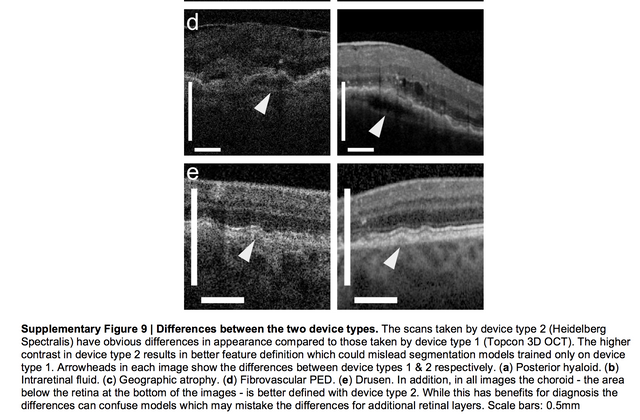
보시는 것과 같이 두 타입의 기계에서 나오는 영상은 확연히 그 성질이 달라보이고, 그 결과 아래와 같이 segmentation map이 동작하지 않는 것을 보실 수 있습니다.
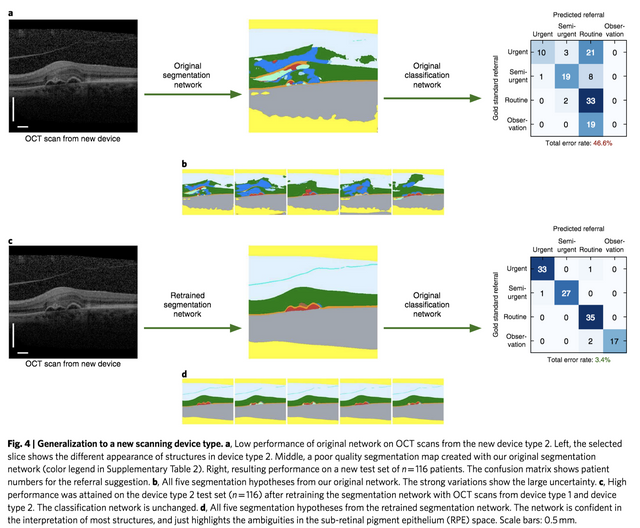
그러나 이 부분을 수정해 주면 아래와 같이 성능이 좋아지죠.
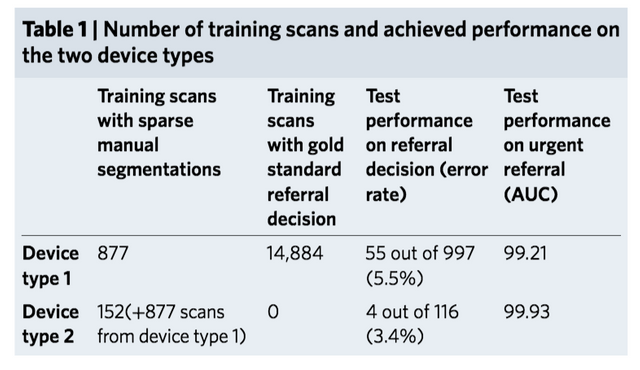
다시 주제로 돌아와 이렇게 하면 성능이 어느 정도냐가 이 논문의 핵심일 것인데, OCT만 봐도 전문의들이 안저영상과 다른 노트들을 같이 본 수치만큼 혹은 좋게 나타나고 있습니다. 뭐 OCT 영상을 판독하는거 자체가 애매한 경우에는 힘들고 3D 영상이다보니 그걸 시간을 들여 아주 자세히 보기도 쉽지는 않은듯 합니다.
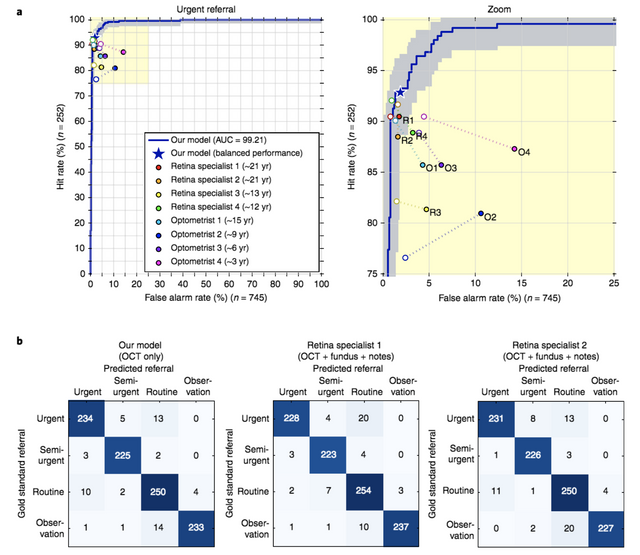
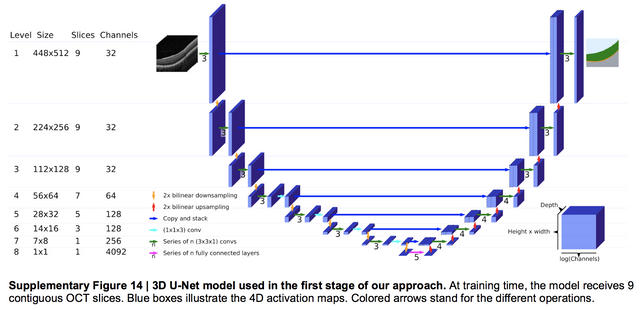
이 논문이 기존 JAMA 논문과 다른 점이라면, 딥러닝 썼다 잘 나왔다! 라는 결론이 아니라 학습등 다양한 방법에 대해서 기술을 나름 최대한 자세히 제공하고 있습니다. 예를 들어 segmentation network은 아래와 같이 3D UNet을 기반으로 하고 있습니다. 제공된 그림에서 확인할 수 있듯이 upsampling, down sampling을 위해서는 max-pooling과 up-convolution 대신 bilinear interpolation을 사용하고, 추가적인 residual connection을 사용하여 receptive field를 넓게 가져가는등 여러 효과를 부수적으로 노립니다. 또한 per-voxel cross entropy에 0.1 label-smoothing regularization, 그리고 affine, elastic transformations을 이용한 data augmentation을 사용합니다.
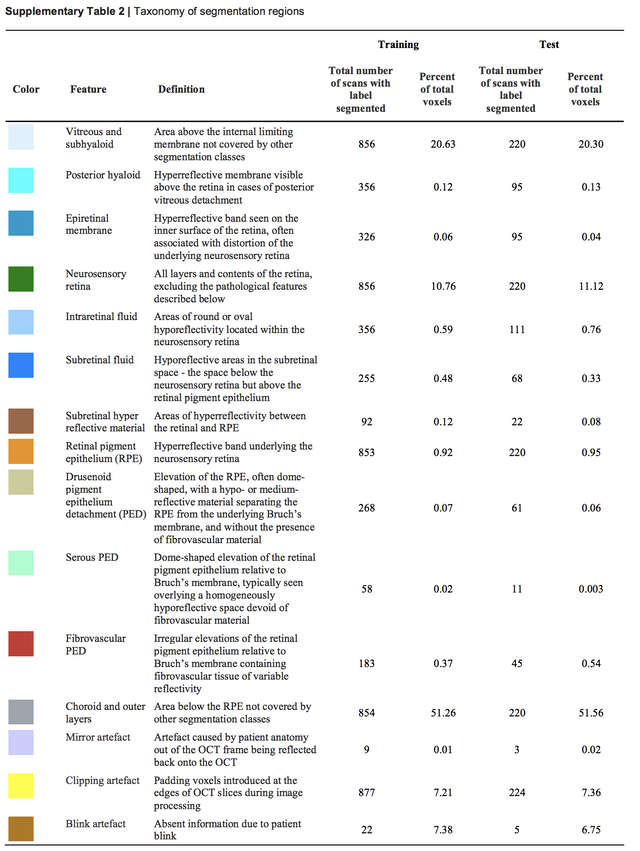
다양한 많은 기술이 쓰일 수 밖에 없는 것은 이 논문에서 하려는 segmentation 작업이 그만큼 쉽지 않고, 또 정확해야 하는 작업이였습니다. 아래 보시는 것과 같이 segmentation 대상으로 삼은 부분을 보시면 그 대상이 많기도 하지만 일부의 경우 그 빈도가 아주 적습니다. segmentation 대상 자체가 imbalanced set입니다. 아마 그래서 loss 부분도 수정했고, 또한 receptive field를 넓게 가져가려고 노력한거 같습니다.
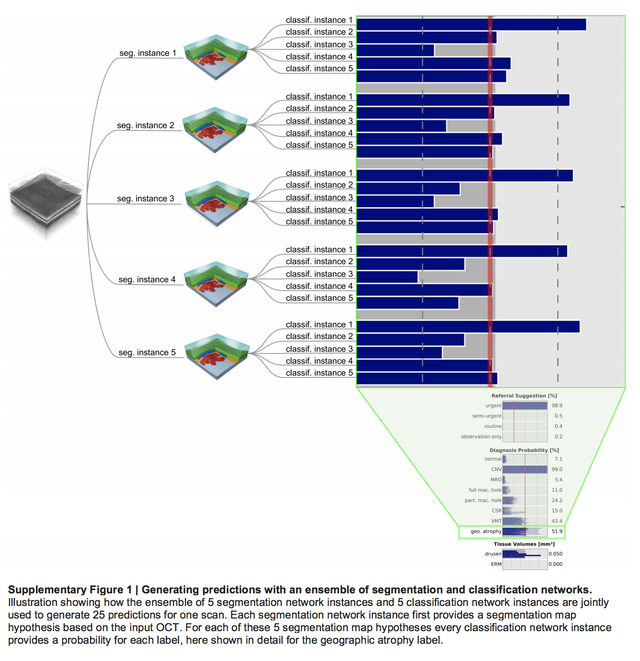
이 논문은 그 뿐만 아니라 다양한 부분에서 최대한 자세한 설명을 제공합니다. 이 논문에서 사용된 방법은 이 뿐 아니라 ensemble 방법도 사용이 되었는데, 기본적으로 아래 그림과 같이 5가지 다른 모델의 결과를 결합니다. segmentation을 위한 network도 5개 classification을 위한 network도 5개, 그렇게 적용이 되면 25개의 결과를 얻는데 최종결과는 average해서 취합니다. 네, 물론 지금까지 deepmind와 google 모두 ensemble을 기본으로 하면서도 그 효과를 이론적인 아닌 경험적, 기술적으로 설명하고 있지만, 그 전 논문보다는 훨씬 친절합니다.
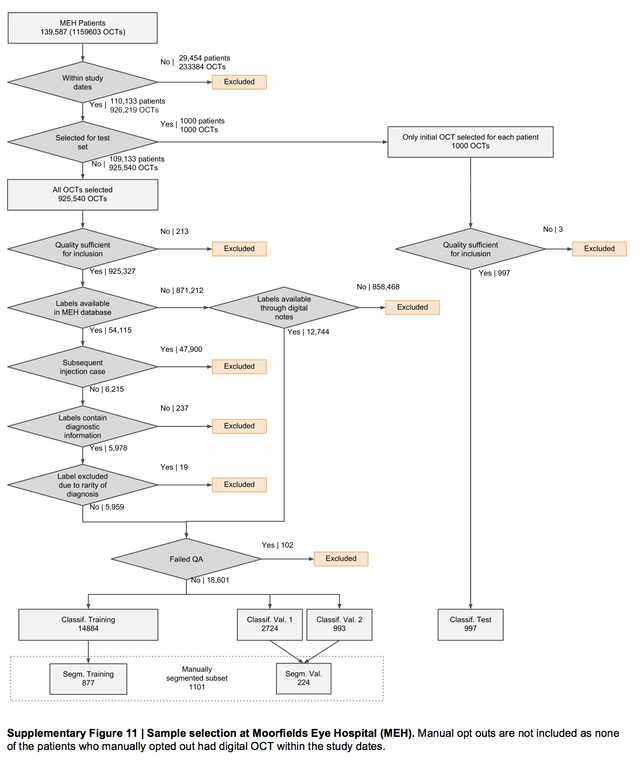
그리고 데이터의 수와 더불어 이 데이터가 어떻게 정제되었는지 단편적인 과정을 순서도로 보여줍니다. data의 노이즈가 어떤 문제인지는 많은 논문에서 리뷰되었는데, 그래서 어떻게 정제하는지는 다 제 각각이였는데, 그래도 친절히 많은 데이터에서 좋은 데이터를 걸러내는 과정을 보여줍니다. 이런 데이터 정제의 과정도 하나의 contribution이기에 이렇게 제공해 주는게 고맙고 좋은듯 합니다.
그리고 마지막으로.. 논문을 읽어보시고, deepmind의 blog를 보면 얼마나 조심스럽게 이 업적을 설명하는지 조금은 쓰여져 있고, 느낄 수 있습니다. 그런데.. 언론은 주로 이렇습니다. 의사만큼 의사가 하는 극히 일부의 영상 판독, 진단 부분에서 어떤 하나의 메트릭으로 얻은 좋은 수치만을 강조합니다.

바쁜 와중에 논문을 읽어본 이유이기도 하지만, 저자나 정말 이 분야에 일하는 분들은 조심스럽게 한걸음한걸음 나가고 있는데 그걸 전달하는 사람이나 정작 이 분야에 없는 사람들이 의사 vs. AI 프레임을 씌워서 기사를 쓰고 자극적인 제목을 달고 있습니다. -_- .. 젠장
Congratulations @jiwoopapa! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!