AI学习笔记之——多臂老虎机(Multi-armed bandit)问题
上一篇文章简要介绍了一下强化学习,强化学习是一个非常庞大的体系,与监督学习和非监督学习相比,其广度和深度都大的多,涉及到很多经典的决策算法,对统计学知识尤其依赖。作为强化学习的基础,这篇文章研究一下这个领域的一个经典决策问题——多臂老虎机。

1.探索-利用困境(Explore-Exploit dilemma)
多臂老虎机是一个有多个拉杆的赌博机,每一个拉杆的中奖几率是不一样的,问题是如何在有限次数内,选择拉不同的拉杆,获得最多的收益。
假设这个老虎机有3个拉杆,最笨的方法就是每个拉杆都试几次,找到中奖概率最大的那个拉杆,然后把之后有限的游戏机会都用在这个拉杆上。
然而这个方法并不是可靠的,因为每个拉杆试1000次显然比试10次所获得的中奖概率(预估概率)更加准确。比如你试了10次,其中那个本来中奖概率不高的拉杆,有可能因为你运气好,会给你一个高概率中奖的假象。
在有限次数下,你到底是坚持在你认为中奖概率高的拉杆上投入更多的次数呢(Exploit),还是去试试别的拉杆(Explore)呢?如何分配Explore和Exploit的次数的问题,就是著名的探索-利用困境(Explore-Exploit dilemma(EE dilemma))。
2. ε贪婪方法(ε -Greedy method)
这个方法就是设定一个ε值, 用来指导我到底是Explore 还是 Exploit。比如将ε设定为0.1,以保证将10%的次数投入在探索(Explore),90%的次数用于利用(Exploit)。
具体操作就是,每次玩的时候就抽一个0到1的随机数,如果这个数大于ε,则玩你认为中奖概率最大的那个拉杆(预估中奖概率)。如果小于ε则随机再选择一个拉杆,同时更新这个拉杆的预估中奖概率,以便于下次选择做参考。
3. 预估回报方法(Estimating Bandit Rewards)
ε贪婪方法最难的就是如何科学地选择ε,预估回报方从另一个角度,抛弃了ε,只保留其"利用"(Exploit)的部分,用预设中奖概率"天花板"的方法来解决Explore-Exploit dilemma.
首先, 将老虎机每个拉杆设置一个比较高的预估中奖概率(比如都是100%),然后每拉一次选中的拉杆, 这个拉杆的的预估概率就会改变。
比如,我第一次选择拉第一个拉杆,发现没有中奖,那这个拉杆的预估中奖概率就从100%变成了50%了。下一次Exploite选择拉杆的时候,第一个拉杆的预估概率就不是最高了,我们就去找这个时候预估概率最高的拉杆来拉,每拉一次更新一下这个拉杆的预估中奖概率。
理论上来说真实概率高的拉杆其预估概率下降的速度会比真实概率低的拉杆慢,所以多试几次之后就能找到真实概率最高的那个拉杆。
4. UCB1 (Bandit Algorithms Continued)方法
我们发现上面两个方法中,某个拉杆预估的中奖概率是随着这个拉杆被拉动的次数而变化的。我们是通过预估概率作为评判标准,来决定去拉哪一个拉杆。
如果一个拉杆没有被拉到,那么这个拉杆的预估中奖概率就不会改变。然而通过直觉就可以理解,一个拉杆的预估概率的准确度是跟你总共拉了多少次拉杆(所有的拉杆被拉的次数)相关的,拉得越多预估概率就越准确。这个时候我们引入UCB概率,而不是预估概率来作为选择拉杆的评判标准。
这里涉及到的理论知识叫做Chernoff-Hoeffding bound理论。大意就是,真实概率与预估概率的差距是随着实验(拉杆)的次数成指数型下降的。
根据这个理论就可以引入UCB概率,公式如下:
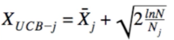
其中XUCB-j是第j个拉杆的的UCB概率,Xj是这个拉杆的预估概率,N是总共实验的次数,Nj第j个拉杆被拉到的次数。
同样的这个算法只有"利用"(Exploit)的部分,将判断Exploit的标准从预估中奖概率改成UCB概率即可。
总结
上文我试图用最简单的语言和最少的公式解释强化学习中的一个经典问题和几个经典算法,当然还有一个更好的算法,叫贝叶斯方法,会用到之前介绍的贝叶斯定理以及Bernoulli likeihood 的更多数学知识,我会找机会单独来讲讲。
相关文章
AI学习笔记之——强化学习
人工智能学习笔记之——人工智能基本概念和词汇
人工智能学习笔记二 —— 定义问题
Thanks for reading my posts and welcome to comment. If you like my post , please upvote , resteem and follow me @hongtao
感谢您的阅读,欢迎留言,如果您喜欢我的帖子,请帮忙点赞、推送及关注我 @hongtao